> Стоп, а что тот мусорного, не считая неподдерживаемых массивов?Вы же сами ответили в предыдущем сообщении. "Зачем хранить все результаты, когда нужет только один, последний". Наверное, что бы заполнить 4 (или 8?) миллионов байт ОЗУ и измерить время обработки 1000 ошибок страниц (или сколько их будет?).
> Обычное дело при бенчмарках - прогнать кусок кода 10 в большой степени
> раз.
В данном случае может играть роль количество итераций цикла (их 77). Напомню его:
while (i <= n) {
let c = a + b;
a = b;
b = c;
i++;
}
Если такое скомпилировать в машинные команды, получится примерно 1 сложение, 2 пересылки, 1 декремент (i++ и i <= n эффективнее заменить уменьшением n и сравнением с 0) и 1 условный переход. 5 команд и 2 зависимости по данным (сложение и 1я пересылка + декремент и переход), то есть процессор потенциально может выполнить по 3-2 команды за такт. В таком случае тело цикла исполняется за 2 такта, а все итерации за 154. Но переход-то условный и на последней итерации предсказатель ошибочно предскажет переход на начало цикла. perf stat про такое выводит примерно следующее:
branch-misses:u # 4,84% of all branches
Вопрос в том, сколько стоит ошибка предсказателя (branch mispredict penalty) в тактах. Допустим, на современных процессорах 0, а на старых PIV с микроархитектурой NetBurst - 10 (число примерное, точное не помню). 164 отличается от 154 довольно существенно.
Надо понимать, что все цифры я взял от балды, но идея, надеюсь, ясна. Если бы цикл исполнялся 10000 раз, погрешность была бы меньше.
Ну и -- функция чистая (без побочных эффектов), оптимизатор вправе заполнить массив результатом первого вызова, либо вообще все лишние выкинуть.
> Правда, я бы лучше подсчитал время на весь цикл, а
> потом поделил бы его, чем пытаться мерять каждый проход, искажая результат
> ненужными получениями времени (по крайней мере в С, хотя и в
> вируалках - почему бы и нет, если можно).
Это всё так, но якобы ещё Кнут учил: «преждевременная оптимизация — корень всех зол». Я не знаю, зачем этот цикл вообще измерять. Интересно было общее время решения, т.е. включая запуск Ноды.
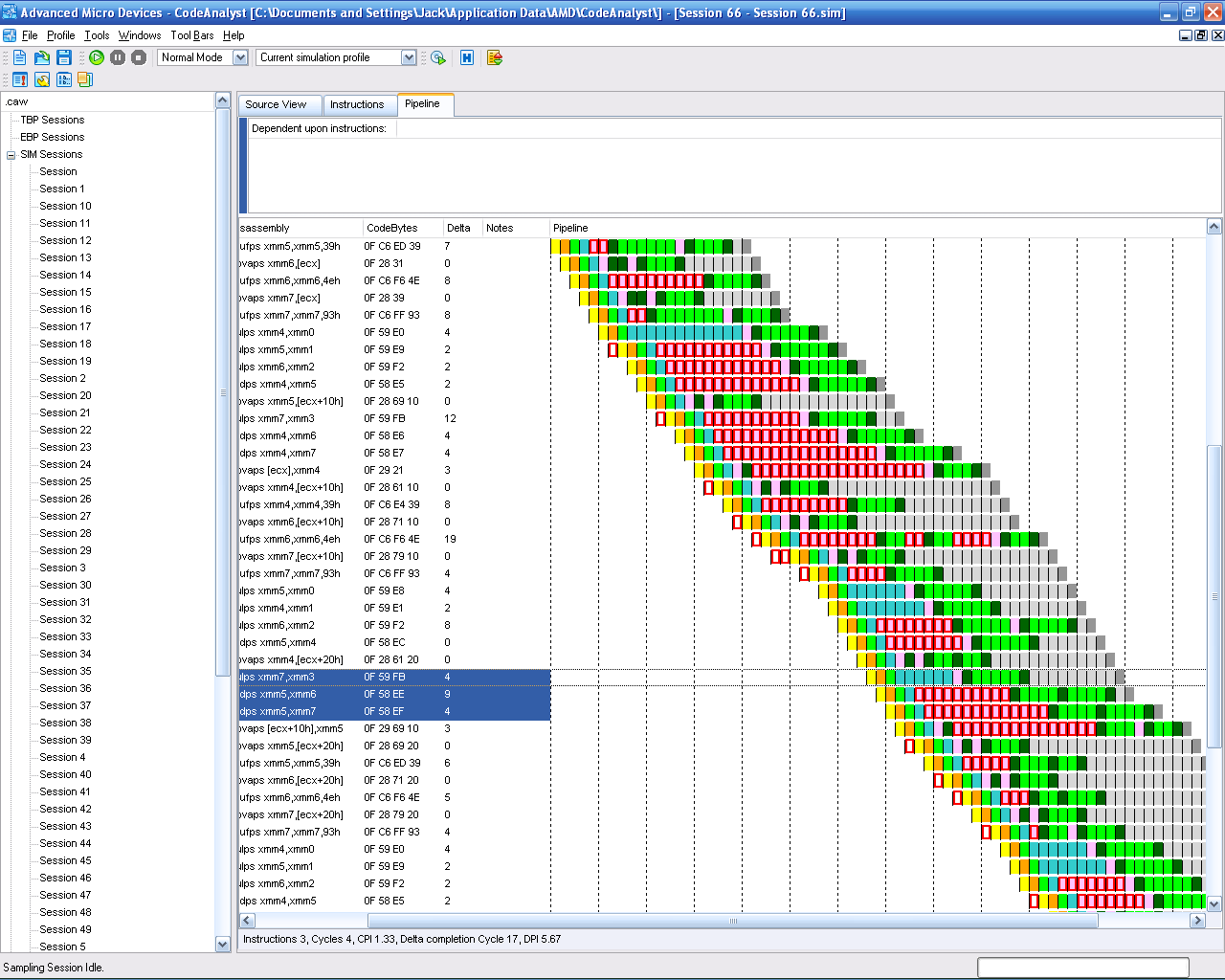
Когда приходилось заниматься оптимизациями, использовал специальную утилиту. Вот эти цветные прямоугольники на иллюстрации https://studfile.net/html/1357/248/html_3EGMhmYyJl.RtCl/img-...
стадии исполнения команд процессором. То есть можно (было) вполне точно посчитать до тактов без использования команды rdtsc. Ныне процессоры сложнее и подобная симуляция не производится, но профилировщики позволяют находить узкие места. Вот им и стоит уделять внимание. Если узким местом окажется вычисление чисел Фибоначчи, вероятно, эффективнее не измерять цикл, а заполнить предвычисленную таблицу.
{kind=link}


