| Каталог документации / Раздел "Сети, протоколы, сервисы" / Оглавление документа |
| |
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
4.5.6 WWW
Семенов Ю.А. (ГНЦ ИТЭФ) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
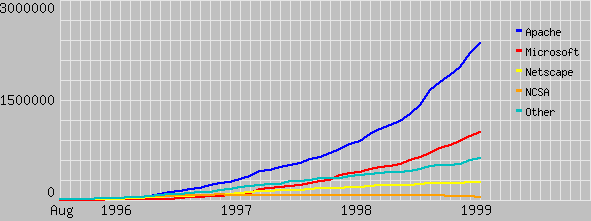
Определения и понятия Прежде чем передать что-то, надо это иметь. Люди общаются, используя естественные языки, ЭВМ обмениваются нуликами и единицами. Но даже в привычном для всех нас общении на родном языке иногда возникают проблемы, и тогда мы переспрашиваем партнера (это прием используют и коммуникационные системы). Когда же мы читаем, перед нами возникает последовательность символов из хорошо известного с детства алфавита. Символы эти могут существенно варьироваться по форме своего изображения, но мы их все равно без труда распознаем. Получаемая нами информация поступает не только от общения с людьми, книгами или телевизором. Не мало крайне важных для жизни данных мы получаем о себе и окружающем мире по имеющимся у нас каналам органов чувств. Мы научились сопоставлять и перепроверять эти данные, когда это требуется. Успешное функционирование этих каналов передачи данных и средств их обработки позволяет нам прожить относительно долгую жизнь. Любые же сбои могут повлиять на нашу судьбу самым драматическим образом. Человечество научилось усовершенствовать данные нам природой каналы информационного обмена. Сначала это были примитивные сигнальные системы типа костров на вершинах холмов (пропускная способность 0,5 бит/час). Появление письменности открыло возможность общения уже умерших людей с живыми, обеспечив процесс накопления знаний. Довольно большие объемы информации могли уже передаваться с использованием лошадей и кораблей на практически неограниченные расстояния. Но скорость такого обмена была ничтожна, доставка сообщения занимала часы, дни, а иногда и годы (никакого намека на работу современной почты я здесь не делаю). Гигантским шагом вперед стало изобретение электрического телеграфа, а позднее радио. Сегодня же мы узнаем о землетрясении в 20000 км от нас максимум через час из очередного телевизионного сборника новостей. Люди объясняются в любви с использованием электронной почты и делают покупки, не выходя из дома. На нас обрушилась лавина информации. Диабетик узнает о прелестях сникерса, мужчины маются, слушая информацию о потрясающих особенностях прокладок с крылышками, о несмываемой губной помаде и т.д. и т.д. Мы стали получать слишком много совершенно ненужной информации. Миллионером станет человек, который предложит покупателям телевизор, отфильтровывающий информацию согласно требованиям зрителя. Таким образом, мы уже сталкиваемся с новыми информационными проблемами, хотя нельзя сказать, что мы решили все старые. Сплошь и рядом мы узнаем слишком поздно о своих болезнях, об угрозах стихийных бедствий или об истинных свойствах того или иного политика. Эти же проблемы относятся и к Интернет. По электронной почте вы получаете сообщения от совершенно незнакомых людей, которые утверждают, что очень хотят вашего быстрого обогащения (хотя их цели диаметрально противоположны), или предлагающих вам какие-то товары или услуги, хотя вы их об этом не просили. К Интернет получили доступ десятки миллионов людей. Если в издательствах редакторы, заботясь о доходах и избегая убытков, блокируют доступ графоманов к широким массам читателей, такого механизма в Интернет не существует. Таким образом, программные средства, фильтрующие поток данных на входе вашего почтового или web-сервера, здесь также весьма актуальны. Ниже даются некоторые определения понятий, используемых в разделах о протоколе http, www и информационном поиске. Рассмотрим некоторые свойства информации, например структурированность и ценность. Структурированность - это свойство, которое позволяет принимающей стороне выделить информацию в виде некоторого сигнала, обладающего некоторыми свойствами. Ценность данных выражается через содержательность, полноту, оперативность и достоверность. При обработке и передаче данных важную роль играют знаки и знаковые системы. Знак - это материальный объект, который служит для обозначения другого объекта и используется для передачи информации о последнем. Примерами знаков могут служить ноты, цифры, жесты азбуки глухонемых, знаки регулирования уличного движения и т.д. Одной из разновидностей знака является символ. Разновидностью знаковых систем являются языки, самым сложным из которых является естественный человеческий язык. Все проявления и применения знаков и знаковых систем изучает семиотика. Предметом семиотики является связь знаков друг с другом, с обозначаемыми ими объектами и явлениями, а также с субъектами их использующими для целей коммуникаций. Семиотика содержит в себе три раздела: семантика, синтактика и прагматика. Семантика изучает отношения между знаком и тем, что он обозначает или замещает. Синтактика знаковых систем изучает их структуру и правила соединения знаков.Прагматика изучает законы функционирования знаковой системы, как средства коммуникации субъектов. С прагматикой связаны такие понятия как ценность и цель. World Wide Web (всемирная сеть, WWW или 3W) представляет собой информационную систему, базирующуюся на использовании гипертекста. Разработка этой системы была начата Тимом Бернерс-Ли, которому в 1989 году пришла в голову мысль объединить гипертекст с Интернет. Идея впервые реализована в ЦЕРН (Женева). Доступ к WWW возможен только в рамках протоколов TCP/IP, но для использования 3w необязательно иметь сервер-клиент (browser) на вашей машине. С некоторыми ограничениями возможен доступ и через электронную почту (listserv@info.cern.ch). Если WWW-клиент-сервер не установлен, можно работать в режиме удаленного терминала. Весьма удобным программным интерфейсом для WWW является ms explorer, netscape и некоторые другие. Для подготовки документов в рамках HTML (Hypertext Markup Language) пригоден любой текстовый редактор (например, emacs в UNIX-машинах, ME в MS-DOS или Winword, в последних версиях которого уже допускаются гиперссылки). При подготовке гипертекстов вы можете использовать язык HTML или взять одно из множества доступных программных средств, которые позволяют преобразовать ваш документ в необходимый формат. Документы в гипертексте связываются друг с другом определенным набором слов. Пользователю не нужно знать, где находится тот или иной документ. Часто ссылки на серверы WWW начинаются с сокращения http:// (Hypertext Transfer Protocol). Гипертекст позволяет осуществлять ссылки-разъяснения на статьи, хранящиеся на удаленном сервере. Гипертекст подразумевает не только текстовые объекты (но и графические или звуковые), поэтому термин гиперсреда (hypermedia) более правилен. WWW может проводить поиск ключевых слов и в специфических документах-индексах, в этом случае выдаются указатели на искомые документы. WWW может использовать различные форматы документов и работать с разнообразными структурами информации, обеспечивая доступ к информационной вселенной. На рис. 4.5.6.1 показан рост числа WEB-серверов, базирующихся на разных программных продуктах (www.netcraft.com). В 2000 году скорость регистрации web-серверов достигла 1 в секунду.
Рис. 4.5.6.1. Рост числа web-серверов в период 1995-99 годов На февраль 1999 года число www-серверов равнялось 4.301.512. Что же такое гипертекст? Прежде всего, следует отметить, что гипертекст - это текст, состоящий из ascii-символов. Для обеспечения верстки и организации перекрестных ссылок в гипертексте используются слова-метки. Основу гипертекста составляют HTML-элементы. Такой элемент включает в себя имя, атрибуты, текст или гипертекст. HTML-элемент записывается в документ в виде (более подробное описание смотри в статье о html): <имя_метки> текст </имя_метки> html-документ состоит из одного элемента: <html> .... </html>, который состоит из html-элементов: <head> ... </head> и <body> ... </body>, последние в свою очередь могут содержать различные списки, внутренние и внешние метки и т.д.. Элементы <html>, <head> и <body> для совместимости с более старыми текстами сделаны пока необязательными. В html имеется 6 уровней заголовков (<h1>, .... <h6>), из них первый - главный. В версии HTML+ (и более поздних версиях) предусмотрены операторы позиционирования текста, например, <p align="center">. head-элементы могут содержать в себе: <isindex> говорит о том, что данный документ допускает индексный поиск (база данных). <title> . . . </title> описывает заголовок документа, этот заголовок характеризует содержимое окна. <base href="url"> сообщает имя файла, в котором хранится данный документ. <link rev="relationship" rel="relationship" href="url"> этот элемент позволяет установить связь между документом, содержащим метку (якорь), и документом, указанным в URL (Uniform Resource Locator). Атрибут rel устанавливает связь между HTML-файлом и URL. Атрибут rev (reverse) описывает взаимоотношения между URL и HTML-файлом. Элементы body могут содержать элементы: Текстовые элементы: <p> индицирует конец параграфа и начало нового. <pre> . . . </pre> выделяет текст, который уже был сформатирован ранее (таблицы, программы, стихи, ...). <blockquote> . . . </blockquote> ограничивает часть текста, который должен быть выделен кавычками. Гиперсвязи или якоря <a name="anchor_name"> . . . </a> определяет заданную позицию в документе. <a href="#anchor_name"> . . . </a> описывает ссылку на определенное место текущего документа. <a href="url"> . . . </a> устанавливает связь с другим файлом или ресурсом. <a href="url#anchor_name"> . . . </a> устанавливает связь с заданным местом в другом документе. <a href="url?search_word+search_word"> . . . </a> посылает серверу эталонную строку для поиска. Различные системы поиска могут интерпретировать эту строку по-разному. Для того чтобы читатель незнакомый с гипертекстом, получил некоторое представление о том, как он выглядит, приведу пример: <title> Протоколы и ресурсы Интернет </title> Вам уже ясно, что подготовка гипертекстов "вручную" изнурительная задача и вспомогательные программные средства не повредят, особенно если вы хотите, чтобы ваш текст выглядел привлекательно. Заметим, что управляющие слова-метки могут записываться как строчными, так и прописными буквами (<H1> = <H1>), но они могут восприниматься различными программами просмотра по-разному (могут и игнорироваться вовсе). HTML поддерживает нумерованные (OL), ненумерованные (UL), и описательные списки (DL). Пример нумерованного списка:
<ol>
</ol> Примером описательного списка может служить: <dl> На экране это будет выглядеть примерно так: ИТЭФ Институт Теоретической и Экспериментальной Физики, Москва. ИФВЭ Институт Физики Высоких Энергий, Протвино. <dt> - метка определения, а <dd> - метка данных описания. Как <dt> так и <dd> могут содержать много параграфов, разделенных меткой <p>. Допускается вложение списков друг в друга, например <fsu.html>: <ul> Некоторые символы являются служебными для html и для их отображения на экране требуются определенные ухищрения. Например:
Символ ; (точка с запятой) является составной частью описания. Все предшествующее относилось к описанию представления текстов на экране. Теперь рассмотрим, как можно обозначить смысловые связи и ссылки друг на друга различных частей текста. Собственно именно ради этого и создавалась идеология гипертекстов. Метка, означающая наличие связи, имеет вид <a> и происходит от слова anchor (якорь). В общем виде ссылка имеет следующий формат: <a href="url"> текст </a> URL (universal resource locator) в простейшем случае может быть именем файла. Текст обозначает действительный текст в документе, который может быть подсвечен, выделен другим цветом или помечен цифрой. Этот текст говорит программе просмотра, что в URL можно найти связанную с данным документом информацию или изображение. При использовании программы типа MS IE (или Netscape) для вызова этой информации или изображения на экран достаточно указать мышкой на текст и нажать кнопку. Если URL указывает на объект, находящийся не в вашей сети эта процедура может занять некоторое время. Чтобы вас как-то развлечь, программа показывает вам вращающийся земной шар в верхнем правом углу экрана. Метка <A> может использоваться и для ссылки на определенный раздел документа: <a name="refname"> текст </a>, где refname является меткой в вашем документе. Пусть в файле fsu.html определена следующая ссылка-якорь: <a name="итэф"> ИТЭФ </a> тогда, находясь в пределах этого документа, можно попасть в нужную точку с помощью: <a href=#итэф> У-10 </a> протонный синхротрон. В другом документе может присутствовать встречная ссылка, например: У-10 в <a href="fsu.html#итэф"> ИТЭФ>/a> Теперь, при нажатии кнопки мышки на слове ИТЭФ, программа отобразит fsu.html и отметит позицию со словом ИТЭФ (ссылка name=итэф). Вообще говоря, вы можете ссылаться на метки-якоря в файлах, находящихся на другой машине (на другом конце земли :-) ), приводя полное наименование URL. В общем случае url указывает тип и место расположения ресурса: сервер://host.domain[:port]/path/объект, где в качестве сервера может стоять: FTP, Telnet, HTTP, Gopher, Wais, News. Path описывает проход к каталогу, где лежит объект. Если программа просмотра (Netscape) способна воспроизводить изображения, можно ввести ссылки на файлы, содержащие нужные для пояснения текста картинки, например: <img src="имя_файла.gif"> Обратите внимание, что здесь используется графический стандарт gif (Graphics Interchange Format). Приемлемы также графические форматы tiff, jpeg, rgb и hdf. Читатели, желающие сформировать титульную страницу (home page) своего института, фирмы или проекта, должны изучить предмет более углубленно, обратившись, например по адресу: http://info.cern.ch/hypertext/www/provider/overview.html. После этого недолгого экскурса в гипертекст, который является основой многих поисковых систем, вернемся к проблематике www. Следует заметить, что публично доступные клиент-серверы существуют для сред MS-DOS, VMS, MVS, UNIX, X-windows, Macintosh, NEXT. Это математическое обеспечение доступно через анонимный FTP из депозитария info.cern.ch секции /pub/www (или www.earn.net gnrt/www.html). Графические клиент-серверы доступны для UNIX, Windows, Macintosh, X-windows, Next. Режим удаленного терминала можно реализовать через telnet по адресу info.cern.ch (при этом не требуется иметь авторизацию на какой-либо ЭВМ ЦЕРН). Многие серверы при старте выходят на приглашение login. Обычно для входа в WWW при этом достаточно напечатать WWW. Никакого слова-пропуска не требуется. Программный пакет PCTCP (и некоторые другие) допускает настройку на эмуляцию того или иного терминала, например: tn -x vt100 info.cern.ch, где info.cern.ch - адрес WWW-сервера, который предполагает работу с терминалом VT-100 (или его эмулятором). При работе в строчном режиме (режим меню) вам предлагается возможность выбора одного из пунктов меню. Для этого вы печатаете номер этого пункта и нажимаете клавишу <enter>. Если все меню на экране не помещается, вы можете перемещаться по нему в любом направлении. Пояснения, содержащиеся на экране, позволяют работать c системой даже новичку. WWW-сервер в простом варианте выполняет лишь команды get имя_файла, приходящие от клиент-сервера пользователя. Остальная работа выполняется www-клиентом. Существует достаточно много "удаленных" тематических серверов, например:
Список этот не является исчерпывающим, существуют клиент-серверы и в России. Появились и первые зеркальные www-депозитарии в России (например, xxx.itep.ru ("зеркало" сервера LANL - Лос-Аламос, США), store.in.ru (зеркальный сервер по Linux - Red Hat и RFC) и т.д.. Хотя в вышеприведенной таблице указана тематика серверов, не следует думать, что этим ограничивается содержимое депозитариев. ЦЕРН является базовой организацией для справочных запросов (здесь работают многие авторы этой системы, www-bug@info.cern.ch). Для получения нужного файла по электронной почте следует послать mail по адресу listserv@info.cern.ch с командой send. Команда send присылает документ с данным www-адресом. Но следует иметь в виду ряд ограничений. Гипертекстные документы имеют стандартную ширину в 72 символа. В конце документа обычно имеется список других адресов документов по данной или близкой тематике. Гипертекстный документ имеет связи, которые помещаются в квадратные скобки. Обратите внимание на то, что, несмотря на наличие имени listserv в начале, - это не listserv-сервер. Максимальное число строк, получаемое пользователем, при этом не превышает 1000 (хотя сегодня найдется немного желающих пользоваться такой услугой, если имеется прямой доступ в Интернет). Все запросы мониторируются. При работе с графикой выбор того или иного объекта производится мышкой. Работая со строчным сервером, следует набрать номер строки меню и нажать клавишу <enter>. В WWW доступны некоторые команды (параметры команд помещаются в угловые скобки <>, в квадратных скобках приведены сокращенные названия команд для построчного просмотра; используется полное или сокращенное имя команды.):
Стандартная форма обращения к www имеет вид: www <option> <docaddress <ключевое слово>>, где docaddress - гипертекстный адрес документа, который вы хотите просмотреть; а ключевое слово - объект поиска в индексе, предоставляемом docaddress. По умолчанию на экран вызывается первый документ. В нижней части экрана отображается строка выполнимых команд. Команды могут набираться как строчными, так и заглавными буквами. Имеются следующие возможности (опции):
Для перехода к следующей странице достаточно нажать клавишу <enter>. Ниже приведен пример меню World Wide Web (в настоящее время данный вид доступа представляет скорее исторический интерес): the world-wide web virtual library: subject catalogue this is a distributed subject catalogue. see also arrangement by service type [1], and other
subject catalogues of network information [2]. Цифры в квадратных скобках представляют собой пункты меню. Для выбора одного из них достаточно напечатать его номер (после двоеточия) и нажать клавишу <enter>. Поиск возможен только в случае, когда в меню в нижней части экрана присутствует слово find. Рассмотренная выше версия является устаревшей, но она дает представление о том как работает WEB-сервер. URL (uniform resource locator) идентифицирует ресурс Internet. В общем виде URL имеет вид: access://host/path где access = {FTP, Gopher, Telnet, ...}; host = имя ЭВМ-сервера; path = имя файла, имя каталога, или другая информация о ресурсе. Например, url для анонимного FTP: ftp.rpi.edu/pub/communications/internet-cmc.txt означает:
Если вы не имеете WWW-клиент-сервера типа NetScape (где можно задать HTTP ресурс, который вы хотите получить), HTTP-ресурс может стать доступным для вас через электронную почту. Пошлите через e-mail запрос по адресу listserv@info.cern.ch с текстом в теле сообщения (вариант сегодня достаточно архаичный): www URL и вы получите welcome.html страницу по электронной почте. Вы можете получить доступ к HTTP-документам с помощью telnet. Команда: telnet info.cern.ch вызовет базовую страницу WWW в ЦЕРН. Для того чтобы достичь нужного URL, введите команду: go http://cnidr.org/welcome.html В ЦЕРН WWW-команду возглавляет Tim Berners-Lee. Обнаруженные ошибки или предложения шлите по адресу www-bug@info.cern.ch. Почтовый подписной лист: www-talk@info.cern.ch. Для подписки пошлите запрос по адресу: www-talk-request@info.cern.ch. В ЦЕРН работа WWW успешно дополняется другими информационными системами, например, библиотечной системой ALICE. Группа новостей в USENET: comp.infosystem.www. Особенности гипертекста с его межуровневыми связями приводят к циклам при просмотре меню (возврат осуществляется по тому же маршруту, по какому вы пришли в данную точку). Это снижает эффективность поиска. Отчасти эти недостатки устранены в графическом интерфейсе NetScape. Графические интерфейсы требуют большой пропускной способности от информационных каналов (желательно > 64 Кб/с). Именно NetScape и MS Explorer стали наиболее популярными интерфейсами поисковых информационных систем и источником наибольших загрузок в телекоммуникационных каналах. Этот интерфейс наиболее естественно позволяет работать и с графическими объектами. Публично доступны версии NetScape для Windows, Unix и т.д. Если у вас уже работает WWW-сервер, нет необходимости заводить серверы GOPHER, Archie или WAIS - их услуги обычно доступны через WWW. Сейчас существует несколько разновидностей программ-надстроек типа NetScape, например MS Explorer, LYNX и некоторые другие. Сегодня трудно найти какую-либо фирму, организацию или общественную группу, не представленную в Интернет своей Web-страницей. Эта технология широко используется в сфере рекламы и даже продажи товаров. Следствием этого стала актуальность проблем безопасности для Web-серверов. Большинство этих проблем происходят от несовершенства программ. Несмотря на общеизвестный совет не использовать программы версии 1.0, ошибки и "дыры" встречаются и в более поздних версиях (например, в Apache V.1.1.1 или Netscape Navigator 2.0, MS Internet Explorer 3.0 и т.д.). Хотя функция Web-сервера принципиально проста: найти запрошенный URL и послать его заказчику, реально практически все существующие сервера "обросли" конфигурационными опциями, интерфейсами для различных баз данных, снабжены адаптерами для разных версий HTTP и HTML, скриптами и модулями API. В результате исполняемый модуль WWW-сервера в несколько раз больше, чем для FTP-сервера, что оставляет достаточно пространства для ошибок и возможностей для реализации хакерских замыслов. 4.5.6.1 Программное обеспечение WEB Существует достаточно широкий список программного обеспечения для формирования WEB-сервера. Структура и конфигурация этих серверов варьируется в широких пределах, но есть у них и немало общего. Рассмотрим основные каталоги, которые возникают при установке WEB-сервера. Каталог конфигурации. Здесь содержатся файлы, которые определяют рабочие характеристики сервера. Этот каталог жизненно важен, и необходимо максимально возможно ограничить круг лиц, которым разрешено изменять здесь что-либо. Инструментальный каталог администратора. Этот каталог содержит утилиты, которыми пользуется администратор сервера. Здесь могут располагаться программы управления доступом, генерации криптографических ключей и формирования поисковых индексов. Каталог файла регистрации операций (LOG-файла). Здесь фиксируются все процедуры доступа к серверу, а также все происходящие сбои и ошибки. Каталог CGI. В этом каталоге располагаются CGI-скрипты, которые используются для формирования документов с динамически изменяющимся содержимым, для организации доступа к базам данных и выполнения интерактивных задач. Здесь же могут находиться средства, которые позволяют администратору-программисту добавлять свои собственные функции сервера, расширяя его возможности. Каталог документов (корневой каталог документов). Этот каталог составляет основу иерархического дерева каталогов документов сервера. Каталог может включать субкаталоги типа html, java, icons и т.д. Помимо перечисленных может присутствовать каталог security, где лежат параметры доступа (имена и пароли) авторизованных клиентов сервера. Современные WEB-серверы трудно себе представить без CGI-скриптов (Common Gateway Interface). Эти скрипты позволяют существенно расширить возможности сервера, обеспечить доступ к базам данных, работать с документами, содержимое которых изменяется динамически, организовать игры в реальном масштабе времени, обрабатывать запросы клиентов, посылать сообщения по электронной почте и многое другое. CGI-скрипты обеспечивают интерфейс между WEB-сервером и серверами GOPHER или FTP. Привлекательность CGI-скриптов и легкость их написания, к сожалению, дополняется тем, что совсем не просто написать их безошибочно. CGI-скрипты (ISO 9636) представляют собой небольшие программы, которые являются независимыми от основной программы сервера. Когда удаленный пользователь запрашивает URL, который указывает на CGI-скрипт, сервер исполняет скрипт, передавая информацию о состоянии сессии. CGI-скрипт обрабатывает эти данные и выдает документ, который, вообще говоря, может быть и не только HTML-страницей. Среди информации, которую передает сервер CGI-скрипту, обычно присутствует строка запроса, содержащая данные, которые поступили от удаленного пользователя. Форма строки запроса произвольна. Она может содержать ключевые слова для поиска или SQL-предложение для обращения к серверу базы данных. Строка запроса может быть передана CGI-скрипту двумя способами. В первом случае она прикрепляется к URL. Например: http://www.altavista.com/cgi-bin/query?pg=q&what=web&fmt=.&q=question Все, что следует после знака вопроса, представляет собой строку запроса. В этой версии строка запроса должна следовать требованиям записи URL, т.е. пробелы должны заменяться символом + (ключевым словом в приведенном запросе является question). CGI-скрипт извлекает строку запроса с учетом переменной конфигурации (environment). Альтернативой этому является посылка строки запроса CGI методом HTTP POST. Этот метод обычно используется при заполнении пользователем форм и отправке их удаленному серверу. В этом случае WEB-сервер направляет строку запроса непосредственно на стандартный вход скрипта. Желательно пользоваться хорошо проверенными скриптами, а при написании новых следить за тем, чтобы они ни при каких обстоятельствах не допускали исполнения команд на машине сервера и не производили несанкционированной модификации файлов. Пользователи WEB сервера, которые имеют доступ к документам и файлам поддержки обычно делятся на четыре категории: хозяин, автор, разработчик и администратор. Каждая их этих категорий имеет разные права доступа, показанные в таблице 4.5.6.1. Таблица 4.5.6.1. Возможности различных категорий пользователей WEB-сервера
R - разрешено чтение. W - разрешена запись и уничтожение. Хозяином в данном случае считается администратор узла, где размещен WEB-сервер. Автор занимается подготовкой документов и рисунков. Разработчик имеет сходные функции с автором, но в его обязанности входит также разработка и модификация CGI-скриптов и модулей сервера. Клиент (посетитель) может запускать скрипты и читать любые документы. Приведенная иерархия возможностей для пользователей гарантирует устойчивую работу и безопасность WEB-сервера. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Previous:
4.5.5 Протокол X-Windows
UP:
4.5 Процедуры Интернет
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||



|
Закладки на сайте Проследить за страницей |
Created 1996-2024 by Maxim Chirkov Добавить, Поддержать, Вебмастеру |