Оригинал: skif.bas-net.by
Настоящий перевод выполнен по тексту стандарта MPI-1.1 с использованием некоторых разделов стандарта MPI-2:
Тексты этих стандартов в форматах PostScript и HTML размещены в Интернет на основном сайте разработчиков MPI по адресу: http://www-unix.mcs.anl.gov/mpi. Версия HTML для MPI-1.1 представлена 1 ноября 2000 года, а для MPI-2.0 - 10 сентября 2001 года.
Основным документом для перевода являлся стандарт MPI-1.1. Стандарт MPI-2 является расширением стандарта MPI-1, предоставляя пользователю новые возможности (такие, как динамические процессы, односторонние коммуникации, параллельный ввод-вывод и др.). Однако в стандарте MPI-2 содержатся некоторые уточнения и добавления, относящиеся к стандарту MPI-1, которые учтены в настоящем переводе:
Перевод выполнили:
Г.И.Шпаковский
Н.В.Серикова
А.С.Липницкий
А.Е.Верхотуров
А.Н.Гришанович
А.В.Орлов
под общей редакцией
Г.И.Шпаковского
80ptРеспублика Беларусь, Минск, Белорусский государственный
университет
20 декабря 2001 года
Стандарт не описывает:
Имеется много особенностей, которые были рассмотрены, но не включены в этот стандарт. Это произошло по ряду причин, основная из них - ограниченное время для завершения стандарта. Эти особенности всегда могут быть выполнены в виде расширения для некоторой реализации. Возможно, будущие версии MPI будут адресованы решению некоторых из этих прблем.
Синтаксис функции MPI_GROUP_SIZE для определения размера группы представлен ниже.
MPI_GROUP_SIZE (group, size)
| IN | group | группа (дескриптор) | |
| OUT | size | количество процессов в группе (целое) |
int MPI_Group_size(MPI_Group group, int *size)
MPI_GROUP_SIZE(GROUP, SIZE, IERROR)
INTEGER GROUP, SIZE, IERROR
int MPI::Group::Get_size() const
Синтаксис функции MPI_GROUP_RANK для определения номера процесса в группе представлен ниже.
MPI_GROUP_RANK (group, rank)
| IN | group | группа (дескриптор) | |
| OUT | rank | номер процесса в группе или MPI_UNDEFINED, если процесс не является членом группы (целое) |
int MPI_Group_rank(MPI_Group group, int *rank)
MPI_GROUP_RANK(GROUP, RANK, IERROR)
INTEGER GROUP, RANK, IERROR
int MPI::Group::Get_rank() const
Синтаксис функции MPI_GROUP_TRANSLATE_RANKS представлен ниже.
MPI_GROUP_TRANSLATE_RANKS(group1, n, ranks1, group2, ranks2)
| IN | group1 | группа1 (дескриптор) | |
| IN | n | число номеров в массивах ranks1 и ranks2 (целое) | |
| IN | ranks1 | массив из нуля или более правильных номеров в группе1 | |
| IN | group2 | группа2 (дескриптор) | |
| OUT | ranks2 | массив соответствующих номеров в группе2, MPI_UNDEFINED, если соответствие отсутствует. |
int MPI_Group_translate_ranks(MPI_Group group1, int n,
int *ranks1, MPI_Group group2, int *ranks2)
MPI_GROUP_TRANSLATE_RANKS(GROUP1, N, RANKS1, GROUP2, RANKS2, IERROR)
INTEGER GROUP1, N, RANKS1(*), GROUP2, RANKS2(*), IERROR
static void MPI::Group::Translate_ranks(const MPI::Group& group1,
int n, const int ranks[], const MPI::Group& group2, int ranks2[])
Эта функция важна для определения относительной нумерации одинаковых процессов в двух различных группах. Например, если известны номера некоторых процессов в группе коммуникатора MPI_COMM_WORLD, то можно узнать их номера в подмножестве этой группы.
Синтаксис функции MPI_GROUP_COMPARE представлен ниже.
MPI_GROUP_COMPARE(group1, group2, result)
| IN | group1 | первая группа (дескриптор) | |
| IN | group2 | вторая группа (дескриптор) | |
| OUT | result | результат (целое) |
int MPI_Group_compare(MPI_Group group1, MPI_Group group2, int *result)
MPI_GROUP_COMPARE(GROUP1, GROUP2, RESULT, IERROR)
INTEGER GROUP1, GROUP2, RESULT, IERROR
static int MPI::Group::Compare(const MPI::Group& group1,
const MPI::Group& group2)
Если члены группы и их порядок в обеих группах совершенно одинаковы, возвращается результат MPI_IDENT. Это происходит, например, если group1 и group2 имеют тот же самый дескриптор. Если члены группы одинаковы, но порядок различен, то возвращается результат MPI_SIMILAR. В остальных случаях возвращается значение MPI_UNEQUAL.
Конструкторы групп применяются к подмножеству и расширенному множеству существующих групп. Эти конструкторы создают новые группы на основе существующих групп. Данные операции являются локальными и различные группы могут быть определены на различных процессах; процесс может также определять группу, которая не включает саму себя. MPI не имеет механизма для формирования группы с нуля, группа может формироваться только на основе другой, предварительно определенной группы. Базовая группа, на основе которой определены все другие группы, является группой, связанной с начальным коммуникатором MPI_COMM_WORLD (доступна через функцию MPI_COMM_GROUP).
Объяснение: Отсюда следует, что не имеется никакой функции дублирования группы, аналогичной MPI_COMM_DUP, описываемой позже в этой главе. Нет необходимости в дубликаторе группы. Группа, когда-либо созданная, может иметь несколько ссылок, путем копирования дескриптора. Следующие конструкторы предназначены для создания подмножеств и расширенных множеств существующих групп.[]
Совет разработчикам: Каждый конструктор группы ведет себя так, как будто он возвращает новый объект группы. Если эта новая группа является копией существующей группы, то можно избежать создания таких новых объектов, используя механизм ссылок.[]
Синтаксис функции MPI_COMM_GROUP представлен ниже.
MPI_COMM_GROUP(comm, group)
| IN | comm | коммуникатор (дескриптор) | |
| OUT | group | группа, соответствующая comm (дескриптор) |
int MPI_Comm_group(MPI_Comm comm, MPI_Group *group)
MPI_COMM_GROUP(COMM, GROUP, IERROR)
INTEGER COMM, GROUP, IERROR
MPI::Group MPI::Comm::Get_group() const
ФункцияMPI_COMM_GROUP возвращает в group дескриптор группы из comm.
Синтаксис функции MPI_GROUP_UNION представлен ниже.
MPI_GROUP_UNION(group1, group2, newgroup)
| IN | group1 | первая группа (дескриптор) | |
| IN | group2 | вторая группа (дескриптор) | |
| OUT | newgroup | объединенная группа (дескриптор) |
int MPI_Group_union(MPI_Group group1, MPI_Group group2, MPI_Group *newgroup)
MPI_GROUP_UNION(GROUP1, GROUP2, NEWGROUP, IERROR)
INTEGER GROUP1, GROUP2, NEWGROUP, IERROR
static MPI::Group MPI::Group::Union(const MPI::Group& group1,
const MPI::Group& group2)
Синтаксис функции MPI_GROUP_INTERSECTION представлен ниже.
MPI_GROUP_INTERSECTION(group1, group2, newgroup)
| IN | group1 | первая группа (дескриптор) | |
| IN | group2 | вторая группа (дескриптор) | |
| OUT | newgroup | группа, образованная пересечением (дескриптор) |
int MPI_Group_intersection(MPI_Group group1, MPI_Group group2, MPI_Group *newgroup)
MPI_GROUP_INTERSECTION(GROUP1, GROUP2, NEWGROUP, IERROR)
INTEGER GROUP1, GROUP2, NEWGROUP, IERROR
static MPI::Group MPI::Group::Intersect(const MPI::Group& group1,
const MPI::Group& group2)
Синтаксис функции MPI_GROUP_DIFFERENCE представлен ниже.
MPI_GROUP_DIFFERENCE(group1, group2, newgroup)
| IN | group1 | первая группа(дескриптор) | |
| IN | group2 | вторая группа (дескриптор) | |
| OUT | newgroup | исключенная группа (дескриптор) |
int MPI_Group_difference(MPI_Group group1, MPI_Group group2, MPI_Group *newgroup)
MPI_GROUP_DIFFERENCE(GROUP1, GROUP2, NEWGROUP, IERROR)
INTEGER GROUP1, GROUP2, NEWGROUP, IERROR
static MPI::Group MPI::Group::Difference(const MPI::Group& group1,
const MPI::Group& group2)
Операции над множествами определяются следующим образом:
Заметим, что для этих операций порядок процессов в результирующей группе определен прежде всего в соответствии с порядком в первой группе (если возможно) и затем, в случае необходимости, в соответствии с порядком во второй группе. Ни объединение, ни пересечение не коммутативны, но оба ассоциативны.
Новая группа может быть пуста, то есть эквивалентна MPI_GROUP_EMPTY.
Синтаксис функции MPI_GROUP_INCL представлен ниже.
MPI_GROUP_INCL(group, n, ranks, newgroup)
| IN | group | группа (дескриптор) | |
| IN | n | количество элементов в массиве номеров (и размер newgroup, целое) | |
| IN | ranks | номера процессов в group, перешедших в новую группу (массив целых) | |
| OUT | newgroup | новая группа, полученная из прежней, упорядоченная согласно ranks (дескриптор) |
int MPI_Group_incl(MPI_Group group, int n,
int *ranks, MPI_Group *newgroup)
MPI_GROUP_INCL(GROUP, N, RANKS, NEWGROUP, IERROR)
INTEGER GROUP, N, RANKS(*), NEWGROUP, IERROR
MPI::Group MPI::Group::Incl(int n, const int ranks[]) const
Функция MPI_GROUP_INCL создает группу newgroup, которая состоит из n процессов из group с номерами ranks[0],..., ranks[n-1]; процесс с номером i в newgroup есть процесс с номером ranks[i] в group. Каждый из n элементов ranks должен быть правильным номером в group, и все элементы должны быть различными, иначе программа будет неверна. Если n = 0, то newgroup имеет значение MPI_GROUP_EMPTY. Эта функция может использоваться, например, для переупорядочения элементов группы (см. также MPI_GROUP_COMPARE).
Синтаксис функции MPI_GROUP_EXCL представлен ниже.
MPI_GROUP_EXCL(group, n, ranks, newgroup)
| IN | group | группа (дескриптор) | |
| IN | n | количество элементов в массиве номеров (целое) | |
| IN | ranks | массив целочисленных номеров в group, не входящих в newgroup | |
| OUT | newgroup | новая группа, полученная из прежней, сохраняющая порядок, определенный group (дескриптор) |
int MPI_Group_excl(MPI_Group group, int n, int *ranks, MPI_Group *newgroup)
MPI_GROUP_EXCL(GROUP, N, RANKS, NEWGROUP, IERROR)
INTEGER GROUP, N, RANKS(*), NEWGROUP, IERROR
MPI::Group MPI::Group::Excl(int n, const int ranks[]) const
Функция MPI_GROUP_EXCL создает группу процессов newgroup, которая получена путем удаления из group процессов с номерами ranks[0],..., ranks[n-1]. Упорядочивание процессов в newgroup идентично упорядочиванию в group. Каждый из n элементов ranks должен быть правильным номером в group, и все элементы должны быть различными; в противном случае, программа неверна. Если n = 0, то newgroup идентична group.
Синтаксис функции MPI_GROUP_RANGE_INCL представлен ниже.
MPI_GROUP_RANGE_INCL(group, n, ranges, newgroup)
| IN | group | группа (дескриптор) | |
| IN | n | число триплетов в массиве ranges (целое) | |
| IN | ranges | массив целочисленных триплетов формы (первый номер, последний номер, шаг), указывающий номера в group процессов, которые включены в newgroup | |
| OUT | newgroup | новая группа, полученная из прежней, упорядоченная согласно ranges (дескриптор) |
int MPI_Group_range_incl(MPI_Group group, int n, int ranges[][3], MPI_Group *newgroup)
MPI_GROUP_RANGE_INCL(GROUP, N, RANGES, NEWGROUP, IERROR)
INTEGER GROUP, N, RANGES(3,*), NEWGROUP, IERROR
MPI::Group MPI::Group::Range_incl(int n,
const int ranges[][3]) const
Если аргументы ranges состоят из триплетов
![]()
то newgroup состоит из последовательности процессов с номерами
![]()
![]()
Каждый вычисленный номер должен быть правильным номером в group, и все
вычисленные номера должны быть различным, иначе программа будет неверной.
Заметим, что возможен случай, когда
![]() , и
, и ![]() может быть
отрицательным, но не может быть равным нулю.
может быть
отрицательным, но не может быть равным нулю.
Функциональные возможности этой процедуры позволяют расширить массив номеров до массива включенных номеров и передать результирующий массив номеров и другие аргументы в MPI_GROUP_INCL. Запрос к MPI_GROUP_INCL эквивалентен запросу к MPI_GROUP_RANGE_INCL с каждым номером i в ranks, замененным триплетом (i, i, 1) в аргументе ranges.
Синтаксис функции MPI_GROUP_RANGE_EXCL представлен ниже.
MPI_GROUP_RANGE_EXCL(group, n, ranges, newgroup)
| IN | group | группа (дескриптор) | |
| IN | n | количество элементов в массиве номеров (целое) | |
| IN | ranges | одномерный массив целочисленных триплетов формы (первый номер, последний номер, шаг), отображающий номера в group процессов, которые исключаются из выходной группы newgroup. | |
| OUT | newgroup | новая группа, образованная из прежней, сохраняющая порядок в group (дескриптор) |
int MPI_Group_range_excl(MPI_Group group, int n, int ranges[][3], MPI_Group *newgroup)
MPI_GROUP_RANGE_EXCL(GROUP, N, RANGES, NEWGROUP, IERROR)
INTEGER GROUP, N, RANGES(3,*), NEWGROUP, IERROR
MPI::Group MPI::Group::Range_excl(int n,
const int ranges[][3]) const
Каждый вычисленный номер должен быть правильным номером в group, и все вычисленные номера должны быть различными, иначе программа будет неверной.
Функциональные возможности этой процедуры позволяют расширить массив номеров до массива исключенных номеров и передать результирующий массив номеров и другие аргументы в MPI_GROUP_EXCL. Запрос к MPI_GROUP_EXCL эквивалентен запросу к MPI_GROUP_RANGE_EXCL с каждым номером i в ranks, замененным триплетом (i, i, 1) в аргументе ranges.
Совет пользователям: Диапазонные операции не перечисляют номера явно, и поэтому являются более масштабируемыми, если реализованы эффективно. Поэтому программистам MPI рекомендуется использовать их всегда, когда это возможно, поскольку в хороших реализациях это повышает эффективность.[]
Совет разработчикам: Диапазонные операции должны быть реализованы, если возможно, без перечисления членов группы, чтобы получить большую масштабируемость (временную и простран-ственную).[]
Синтаксис функции MPI_GROUP_FREE представлен ниже.
MPI_GROUP_FREE(group)
| INOUT | group | идентификатор группы (дескриптор) |
int MPI_Group_free(MPI_Group *group)
MPI_GROUP_FREE(GROUP, IERROR)
INTEGER GROUP, IERROR
void MPI::Group::Free()
Эта операция маркирует объект группы для удаления. Дескриптор group установливается вызовом в состояние MPI_GROUP_NULL. Любая выполняющаяся операция, использующая эту группу, завершитcя нормально.
Совет разработчикам: Можно сохранять индекс ссылки, который увеличивается при каждом обращении к MPI_COMM_CREATE и MPI_COMM_DUP, и уменьшается при каждом обращении к MPI_GROUP_FREE или MPI_COMM_FREE; объект группы в конечном счете удаляется, когда индекс ссылки уменьшается до нуля.[]
Этот раздел описывает управление коммуникаторами в MPI. Операции обращения к коммуникаторам являются локальными, их выполнение не требует обмена между процессами. Операции, которые создают коммуникаторы, являются коллективными и могут потребовать обмена между процессами.
Совет разработчикам: Хорошие реализации должны снижать накладные расходы, связанные с созданим коммуникаторов (для той же группы или ее подмножества) для нескольких вызовов путем создания множественных контекстов для одной коллективной коммуникации.[]
Все следующие операции являются локальными.
Синтаксис функции MPI_COMM_SIZE представлен ниже
MPI_COMM_SIZE(comm, size)
| IN | comm | коммуникатор (дескриптор) | |
| OUT | size | количество процессов в группе comm (целое) |
int MPI_Comm_size(MPI_Comm comm, int *size)
MPI_COMM_SIZE(COMM, SIZE, IERROR)
INTEGER COMM, SIZE, IERROR
int MPI::Comm::Get_size() const
Объяснение: Функция MPI_COMM_SIZE эквивалентна:
функции MPI_COMM_GROUP по доступу к группе коммуникатора;
функции MPI_GROUP_SIZE по вычислению размера; функции
MPI_GROUP_FREE по удалению временной группы. Совокупность этих
операций используется так часто, что понадобилось сокращение в виде функции
MPI_COMM_SIZE.[]
Совет пользователям: Функция MPI_COMM_SIZE указывает число процессов в коммуникаторе. Для MPI_COMM_WORLD она указывает общее количество доступных процессов (для этой версии MPI не имеется никакого стандартного способа изменить число процессов после инициализации).
Запрос MPI_COMM_RANK указывает номер вызывающего процесса, который располагается в диапазоне от 0 до size-1, где size - возвращаемое значение MPI_COMM_SIZE.[]
Синтаксис функции MPI_COMM_RANK представлен ниже
MPI_COMM_RANK(comm, rank)
| IN | comm | коммуникатор (дескриптор) | |
| OUT | rank | номер вызывающего процесса в группе comm (целое) |
int MPI_Comm_rank(MPI_Comm comm, int *rank)
MPI_COMM_RANK(COMM, RANK, IERROR)
INTEGER COMM, RANK, IERROR
int MPI::Comm::Get_rank() const
Объяснение: Эта функция эквивалентна: по доступу к группе коммуникатора - функции MPI_COMM_GROUP; по вычислению номера - функции MPI_GROUP_RANK; по удалению временной группы - MPI_GROUP_FREE. Совокупность этих операций используется так часто, что оказалось полезным ввести функцию MPI_COMM_RANK.[]
Совет пользователям: Функция MPI_COMM_RANK возвращает номер процесса в частной группе коммуникатора. Это удобно использовать, как отмечено выше, cовместно с MPI_COMM_SIZE.
В модели клиент-сервер создается много программ, где один процесс (обычно
процесс ноль) играет роль распорядителя, а другие процессы служат
вычислительными узлами. В такой структуре два предшествующих запроса полезны
для определения ролей различных процессов коммуни-
катора.[]
Синтаксис функции MPI_COMM_COMPARE представлен ниже
MPI_COMM_COMPARE(comm1, comm2, result)
| IN | comm1 | первый коммуникатор (дескриптор) | |
| IN | comm2 | второй коммуникатор (дескриптор) | |
| OUT | result | результат (целое) |
int MPI_Comm_compare(MPI_Comm comm1, MPI_Comm comm2, int *result)
MPI_COMM_COMPARE(COMM1, COMM2, RESULT, IERROR)
INTEGER COMM1, COMM2, RESULT, IERROR
static int MPI::Comm::Compare(const MPI::Comm& comm1, const MPI::Comm& comm2)
Результат MPI_IDENT появляется тогда и только тогда, когда comm1 и comm2 являются дескрипторами одного и того же объекта (идентичные группы и одинаковые контексты). Результат MPI_CONGRUENT появляется, если исходные группы идентичны по компонентам и нумерации; эти коммуникаторы отличаются только контекстом. Результат MPI_SIMILAR имеет место, если члены группы обоих коммуникаторов являются одинаковыми, но порядок их нумерации различен. В противном случае выдается результат MPI_UNEQUAL.
Нижеперечисленные функции являются коллективными и вызываются всеми процессами в группе, связанной с comm.
Объяснение: Заметим, что в MPI для создания нового коммуникатора необходим исходный коммуникатор. Основным коммуникатором для всех MPI коммуникаторов является коммуникатор MPI_COMM_WORLD, он предопределен извне независимо от MPI. Эта модель была достигнута после больших дебатов, и была выбрана для увеличения ``безопасности'' программ, написанных в MPI.[]
Синтаксис функции MPI_COMM_DUP представлен ниже
MPI_COMM_DUP(comm, newcomm)
| IN | comm | коммуникатор (дескриптор) | |
| OUT | newcomm | копия comm (дескриптор) |
int MPI_Comm_dup(MPI_Comm comm, MPI_Comm *newcomm)
MPI_COMM_DUP(COMM, NEWCOMM, IERROR)
INTEGER COMM, NEWCOMM, IERROR
MPI::Intracomm MPI::Intracomm::Dup() const
MPI::Intercomm MPI::Intercomm::Dup() const
MPI::Cartcomm MPI::Cartcomm::Dup() const
MPI::Graphcomm MPI::Graphcomm::Dup() const
Функция MPI_COMM_DUP дублирует существующий коммуникатор comm вместе со связанными с ним значениями ключей. Для каждого значения ключа соответствующая функция обратного вызова для копирования определяет значение атрибута, связанного с этим ключом в новом коммуникаторе; одно частное действие, которое может сделать вызов для копирования, состоит в удалении атрибута из нового коммуникатора. Операция MPI_COMM_DUP возвращает в аргументе newcomm новый коммуникатор с той же группой, любой скопированной кэшированной информацией, но с новым контекстом (см. раздел 5.7.1).
Совет пользователям: Эта операция используется, чтобы предоставить вызовам параллельных библиотек дублированное коммуникационное пространство, которое имеет те же самые свойства, что и первоначальный коммуникатор. Обращение к MPI_COMM_DUP имеет силу, даже если имеются ждущие парные обмены, использующие коммуникатор comm. Типичный вызов мог бы запускать MPI_COMM_DUP в начале параллельного обращения и MPI_COMM_FREE этого дублированного коммуникатора - в конце вызова. Возможны также и другие модели управления коммуникаторами. Этот запрос применим как к интра-коммуникаторам, так и к интер-коммуникаторам.[]
Совет разработчикам: Производить фактическое копирование информации о группе не обязательно, достаточно добавить новую ссылку и нарастить счетчик ссылок.[]
Синтаксис функции MPI_COMM_CREATE представлен ниже
MPI_COMM_CREATE(comm, group, newcomm)
| IN | comm | коммуникатор (дескриптор) | |
| IN | group | группа, являющаяся подмножеством группы comm (дескриптор) | |
| OUT | newcomm | новый коммуникатор (дескриптор) |
int MPI_Comm_create(MPI_Comm comm, MPI_Group group, MPI_Comm *newcomm)
MPI_COMM_CREATE(COMM, GROUP, NEWCOMM, IERROR)
INTEGER COMM, GROUP, NEWCOMM, IERROR
MPI::Intercomm MPI::Intercomm::Create(const MPI::Group& croup) const
MPI::Intracomm MPI::Intracomm::Create(const MPI::Group& croup) const
Эта функция создает новый коммуникатор newcomm с коммуникационной группой, определенной аргументом group и новым контекстом. Из comm в newcomm не передается никакой кэшированной информации. Функция возвращает MPI_COMM_NULL для процессов, не входящих в group. Запрос неверен, если не все аргументы в group имеют одинаковое значение, или если group не является подмножеством группы, связанной с comm. Заметим, что запрос должен быть выполнен всеми процессами в comm, даже если они не принадлежат новой группе. Этот запрос применяется только к интра-коммуникаторам.
Объяснение: Требование, чтобы вся группа из comm участвовала в запросе, основано на следующих соображениях:
Совет пользователям: MPI_COMM_CREATE обеспечивает
возможность для подмножества процессов группы выполнять отдельные MIMD
вычисления, с отдельным пространством связи. newcomm, который
создается MPI_COMM_CREATE, может использоваться в последующих
обращениях к
MPI_COMM_CREATE (или к другим конструкторам
коммуникаторов), чтобы разделить вычисление на параллельные подвычисления.
Более общие возможности реализует функция MPI_COMM_SPLIT.[]
Совет разработчикам: Поскольку все процессы, вызываемые либо MPI_COMM_DUP, либо
MPI_COMM_CREATE используют тот
же самый аргумент group, теоретически возможно cоздать на размере группы
уникальный контекст без всякого обмена. Однако, локальное выполнение этих
функций требует использования большего пространства контекстных наименований
и уменьшает возможности контроля ошибок. Реализации MPI могут
использовать различные компромиссы между этими противоречивыми целями, такие
как объемное распределение множественных контекстов в одной коллективной
операции.
Важное замечание: если новые коммуникаторы создаются без синхронизации процессов, то коммуникационная система должна быть способна справиться с сообщениями, прибывающими в контексте, который еще не был установлен на процессе-получателе.[]
Синтаксис функции MPI_COMM_SPLIT представлен ниже
MPI_COMM_SPLIT(comm, color, key, newcomm)
| IN | comm | коммуникатор (дескриптор) | |
| IN | color | управление соданием подмножества (целое) | |
| IN | key | управление назначением номеров (целое) | |
| OUT | newcomm | новый коммуникатор (дескриптор) |
int MPI_Comm_split(MPI_Comm comm, int color, int key, MPI_Comm *newcomm)
MPI_COMM_SPLIT(COMM, COLOR, KEY, NEWCOMM, IERROR)
INTEGER COMM, COLOR, KEY, NEWCOMM, IERROR
MPI::Intercomm MPI::Intercomm::Split(int color, int key) const
MPI::Intracomm MPI::Intracomm::Split(int color, int key) const
Эта функция делит группу, связанную с comm на непересекающиеся подгруппы, по одной для каждого значения цвета color. Каждая подгруппа содержит все процессы того же самого цвета. В пределах каждой подгруппы процессы пронумерованы в порядке, определенном значением аргументаkey, со связями, разделенными согласно их номеру в старой группе. Для каждой подгруппы создается новый коммуникатор и возвращается в аргументе newcomm. Процесс может иметь значение цвета MPI_UNDEFINED, тогда newcomm возвращает MPI_COMM_NULL. Это коллективная операция, но каждому процессу разрешается иметь различные значения для color и key.
Обращение к MPI_COMM_CREATE (сomm, group, newcomm) эквивалентно
обращению
к MPI_COMM_SPLIT(comm, color, key, newcomm), где
все члены group имеют color = 0 и key = номеру в group,
и все процессы, которые не являются членами group, имеют color =
MPI_UNDEFINED. Функция MPI_COMM_SPLIT допускает более общее
разделение группы на одну или несколько подгрупп с необязательным
переупорядочением. Этот запрос могут использовать только интра-комму-никаторы.
Значение color должно быть неотрицательным.
Совет пользователям: Это чрезвычайно мощный механизм для разделения единственной коммуникационной группы процессов на k подгрупп, где k неявно выбрано пользователем (количеством цветов для раскраски процессов). Полученные коммуникаторы будут не перекрывающимися. Такое деление полезно для организации иерархии вычислений, например для линейной алгебры.
Чтобы преодолеть ограничение на перекрытие создаваемых коммуникаторов, можно использовать множественные обращения к MPI_COMM_SPLIT. Этим способом можно создавать множественные перекрывающиеся коммуникационные структуры.
Заметим, что для фиксированного цвета ключи не должны быть уникальными. MPI_COMM_SPLIT сортирует процессы в возрастающем порядке согласно этому ключу, и разделяет связи непротиворечивым способом. Если все ключи определены таким же образом, то все процессы одинакового цвета будут иметь относительный порядок номеров такой же, как и в породившей их группе. (В общем случае они будут иметь различные номера.)
Если значение ключа для всех процессов данного цвета сделано нулевым, то это означает, что порядок номеров процессов в новом коммуникаторе безразличен.[]
Объяснение: Аргумент сolor не может иметь отрицательного значения, чтобы не конфликтовать со значением, присвоенным MPI_UNDEFINED.[]
Синтаксис функции MPI_COMM_FREE представлен ниже.
MPI_COMM_FREE(comm)
| INOUT | comm | удаляемый коммуникатор (дескриптор) |
int MPI_Comm_free(MPI_Comm *comm)
MPI_COMM_FREE(COMM, IERROR) INTEGER COMM, IERROR
void MPI::Comm:Free()
Эта коллективная операция маркирует коммуникационный объект для удаления. Дескриптор устанавливается в MPI_COMM_NULL. Любые ждущие операции, которые используют этот коммуникатор, будут завершаться нормально; объект фактически удаляется только в том случае, если не имеется никаких других активных ссылок на него. Это обращение используется в интра- и интер-коммуникаторах. Удаляемые функции обратного вызова для всех кэшируемых атрибутов (см. раздел 5.7) вызываются в произвольном порядке.
Совет разработчикам: Можно использовать механизм подсчета ссылок: число ссылок увеличивается c каждым вызовом MPI_COMM_DUP и уменьшается c каждым вызовом MPI_COMM_FREE. Объект окончательно удаляется, когда число ссылок достигает нуля.
Функция MPI_COMM_FREE является коллективной, но ожидается, что она как правило будет реализовываться как локальная, хотя отладочная версия библиотеки MPI может использовать синхронизацию.[]
Пример 1а:
main(int argc, char **argv)
{
int me, size;
...
MPI_Init (&argc, &argv);
MPI_Comm_rank (MPI_COMM_WORLD, &me);
MPI_Comm_size (MPI_COMM_WORLD, &size);
(void)printf ("Process %d size %d\n", me, size);
...
MPI_Finalize();
}
Пример 1a является программой, которая инициализируется, обращается к ``общему'' коммуникатору и печатает сообщение.
Пример 1b (предполагается, что аргумент size четный):
main(int argc, char **argv)
{
int me, size;
int SOME_TAG = 0;
...
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &me); /* локально */
MPI_Comm_size(MPI_COMM_WORLD, &size); /* локально */
if((me % 2) == 0)
{
/* посылать вплоть до процесса с самым старшим номером */
if((me + 1) < size)
MPI_Send(..., me + 1, SOME_TAG, MPI_COMM_WORLD);
}
else
MPI_Recv(..., me - 1, SOME_TAG, MPI_COMM_WORLD);
...
MPI_Finalize();
}
Пример 1b схематично иллюстрирует обмены сообщениями между ``четными'' и ``нечетными'' процессами в ``общем'' коммуникаторе.
main(int argc, char **argv)
{
int me, count;
void *data;
...
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &me);
if(me == 0)
{
/* получить входные данные, создать буфер ``data'' */
...
}
MPI_Bcast(data, count, MPI_BYTE, 0, MPI_COMM_WORLD);
...
MPI_Finalize();
}
Этот пример иллюстрирует использование коллективного обмена.
Дальше идет перечень оставшихся глав этого документа вместе с кратким описанием каждой.
main(int argc, char **argv)
{
int me, count, count2;
void *send_buf, *recv_buf, *send_buf2,
*recv_buf2;
MPI_Group MPI_GROUP_WORLD, grprem;
MPI_Comm commslave;
static int ranks[] = {0};
...
MPI_Init(&argc, &argv);
MPI_Comm_group(MPI_COMM_WORLD, &MPI_GROUP_WORLD);
MPI_Comm_rank(MPI_COMM_WORLD, &me); /* локально */
MPI_Group_excl(MPI_GROUP_WORLD, 1, ranks,
&grprem);/* локально */
MPI_Comm_create(MPI_COMM_WORLD, grprem, &commslave);
if(me != 0)
{
/* вычисления на подчиненном процессе */
...
MPI_Reduce(send_buf,recv_buff,count, MPI_INT,
MPI_SUM, 1, commslave);
...
}
/* процесс нуль останавливается немедленно после выполнения этого
reduce, другие процессы - позже... */
MPI_Reduce(send_buf2, recv_buff2, count2,
MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);
MPI_Comm_free(&commslave);
MPI_Group_free(&MPI_GROUP_WORLD);
MPI_Group_free(&grprem);
MPI_Finalize();
}
Этот пример иллюстрирует, как из исходной группы создается группа, содержащая все процессы, кроме процесса нуль, и затем, как формируется коммуникатор (commslave) для этой новой группы. Новый коммуникатор используется в коллективном обращении и все процессы выполняются в контексте MPI_COMM_WORLD. Пример иллюстрирует, как эти два коммуникатора (которые обязательно обладают различными контекстами) защищают обмен. Это означает, что обмен в MPI_COMM_WORLD изолирован от обмена в commslave и наоборот.
В общем, ``безопасность группы'' достигается через коммуникаторы, потому что различные контексты в пределах коммуникаторов являются уникальными на любом процессе.
Следующий пример иллюстрирует ``безопасное'' выполнение парного и коллективного обменов в единственном коммуникаторе.
#define TAG_ARBITRARY 12345
#define SOME_COUNT 50
main(int argc, char **argv)
{
int me;
MPI_Request request[2];
MPI_Status status[2];
MPI_Group MPI_GROUP_WORLD, subgroup;
int ranks[] = {2, 4, 6, 8};
MPI_Comm the_comm;
...
MPI_Init(&argc, &argv);
MPI_Comm_group(MPI_COMM_WORLD, &MPI_GROUP_WORLD);
MPI_Group_incl(MPI_GROUP_WORLD,4,ranks,
&subgroup);/*локально */
MPI_Group_rank(subgroup, &me); /* локально */
MPI_Comm_create(MPI_COMM_WORLD, subgroup, &the_comm);
if(me != MPI_UNDEFINED)
{
MPI_Irecv(buff1, count, MPI_DOUBLE, MPI_ANY_SOURCE,
TAG_ARBITRARY, the_comm, request);
MPI_Isend(buff2, count, MPI_DOUBLE, (me+1)%4,
TAG_ARBITRARY, the_comm, request+1);
}
for(i = 0; i < SOME_COUNT, i++)
MPI_Reduce(..., the_comm);
MPI_Waitall(2, request, status);
MPI_Comm_free(&the_comm);
MPI_Group_free(&MPI_GROUP_WORLD);
MPI_Group_free(&subgroup);
MPI_Finalize();
}
Головная программа:
main(int argc, char **argv)
{
int done = 0;
user_lib_t *libh_a, *libh_b;
void *dataset1, *dataset2;
...
MPI_Init(&argc, &argv);
...
init_user_lib(MPI_COMM_WORLD, &libh_a);
init_user_lib(MPI_COMM_WORLD, &libh_b);
...
user_start_op(libh_a, dataset1);
user_start_op(libh_b, dataset2);
...
while(!сделано)
{
/* выполнение */
...
MPI_Reduce(..., MPI_COMM_WORLD);
...
/* проверка окончания цикла */
...
}
user_end_op(libh_a);
user_end_op(libh_b);
uninit_user_lib(libh_a);
uninit_user_lib(libh_b);
MPI_Finalize();
}
Код инициализации библиотеки пользователя:
void init_user_lib(MPI_Comm comm, user_lib_t **handle)
{
user_lib_t *save;
user_lib_initsave(&save); /* локально */
MPI_Comm_dup(comm, &(save->comm));
...
*handle = save;
}
Пользовательский код запуска:
void user_start_op(user_lib_t *handle, void *data)
{
MPI_Irecv(..., handle->comm, &(handle->irecv_handle));
MPI_Isend(..., handle->comm, &(handle->isend_handle));
}
Пользовательский код очистки связи:
void user_end_op(user_lib_t *handle)
{
MPI_Status *status;
MPI_Wait(handle -> isend_handle, status);
MPI_Wait(handle -> irecv_handle, status);
}
Код очистки обьекта пользователя:
void uninit_user_lib(user_lib_t *handle)
{
MPI_Comm_free(&(handle -> comm));
free(handle);
}
Головная программа:
main(int argc, char **argv)
{
int ma, mb;
MPI_Group MPI_GROUP_WORLD, group_a, group_b;
MPI_Comm comm_a, comm_b;
static int list_a[] = {0, 1};
#if defined(EXAMPLE_2B) | defined(EXAMPLE_2C)
static int list_b[] = {0, 2 ,3};
#else/* EXAMPLE_2A */
static int list_b[] = {0, 2};
#endif
int size_list_a = sizeof(list_a)/sizeof(int);
int size_list_b = sizeof(list_b)/sizeof(int);
...
MPI_Init(&argc, &argv);
MPI_Comm_group(MPI_COMM_WORLD, &MPI_GROUP_WORLD);
MPI_Group_incl(MPI_GROUP_WORLD, size_list_a, list_a, &group_a);
MPI_Group_incl(MPI_GROUP_WORLD, size_list_b, list_b, &group_b);
MPI_Comm_create(MPI_COMM_WORLD, group_a, &comm_a);
MPI_Comm_create(MPI_COMM_WORLD, group_b, &comm_b);
if(comm_a != MPI_COMM_NULL)
MPI_Comm_rank(comm_a, &ma);
if(comm_b != MPI_COMM_NULL)
MPI_Comm_rank(comm_b, &mb);
if(comm_a != MPI_COMM_NULL)
lib_call(comm_a);
if(comm_b != MPI_COMM_NULL)
{
lib_call(comm_b);
lib_call(comm_b);
}
if(comm_a != MPI_COMM_NULL)
MPI_Comm_free(&comm_a);
if(comm_b != MPI_COMM_NULL)
MPI_Comm_free(&comm_b);
MPI_Group_free(&group_a);
MPI_Group_free(&group_b);
MPI_Group_free(&MPI_GROUP_WORLD);
MPI_Finalize();
}
Библиотека:
void lib_call(MPI_Comm comm)
{
int me, done = 0;
MPI_Comm_rank(comm, &me);
if(me == 0)
while(!сделано)
{
MPI_Recv(..., MPI_ANY_SOURCE, MPI_ANY_TAG, comm);
...
}
else
{
/* работа */
MPI_Send(..., 0, ARBITRARY_TAG, comm);
....
}
#ifdef EXAMPLE_2C
/* include (resp, exclude) for safety
(resp, no safety): */
MPI_Barrier(comm);
#endif
}
Приведенный выше пример - это на самом деле три примера, зависящих от того, включен или не включен процесс номер 3 в list_b, включена или не включена синхронизация в lib_call. Пример показывает, что нет необходимости защищать друг от друга последовательные обращения к lib_call с тем же самым контекстом. Безопасность будет реализована, еcли добавлена функция MPI_Barrier. Это демонстрирует тот факт, что библиотеки должны быть тщательно разработаны, даже при наличии контекстов.
Алгоритмы с недетерминированной широковещательной операцией или другие обращения с произвольными номерами поцессов-отправителей в общем случае будут уступать детерминированным реализациям ``reduce'', ``allreduce'', и ``broadcast''. Таким алгоритмам следовало бы использовать монотонно возрастающие тэги (в пределах контекста коммуникатора), чтобы сохранить корректность вычислений.
Все предшествующее формирует гипотезу ``коллективных обращений'', реализованных на основе парных обменов. Реализации MPI могут использовать для реализации коллективных операций парные обмены, хотя это и не обязательно. Парные обмены используются здесь, чтобы иллюстрировать проблемы правильности и безопасности, независимо от того, как MPI осуществляет коллективные запросы. См. также раздел 5.8.
Этот раздел представляет концепцию интер-коммуникации и описывает средства MPI, которые ее поддерживают.
В приложениях, содержащих много исполнительных модулей, различные группы процессов выполняют отличающиеся модули, и процессы из этих модулей связываются друг с другом по принципу конвейера или по более общей схеме графа связей между модулями. В этих приложениях для процесса наиболее естественным способом описания целевого процесса является указание номера целевого процесса в пределах целевой группы. В приложениях, которые содержат внутренние серверы уровня пользователя, каждый сервер может быть группой процессов, которая обеспечивает услуги для одного или большего количества клиентов, и каждый клиент может быть группой процессов, которая использует услуги одного или большего количества серверов. В таких приложениях снова проще всего будет определить целевой процесс его номером в пределах целевой группы. Этот тип связи называется ``интер-коммуникация'' и используемый коммуникатор называется ``интер-коммуникатор''.
Интер-коммуникация является обменом типа ``точка-точка'' между процессами в различных группах (парный обмен). Группа, содержащая процесс, который инициализирует операцию интеркоммуникации, называется ``локальной группой'', то есть отправителем при посылке и получателем при приеме. Группа, содержащая целевой процесс, называется ``удаленной группой'', этот процесс является получателем при отправке и отправителем при приеме. Как и в интра-коммуникации, целевой процесс определяется парой (communicator, rank). В отличие от интра-коммуникации, номер указывается относительно второй, отдаленной группы.
Все конструкторы интер-коммуникаторов являются блокирующими и требуют, чтобы локальные и удаленные группы были непересекающимися, чтобы избежать тупиковых ситуаций.
Обобoщенные свойства интер- и интра-коммуникаторов:
Чтобы определить, является ли коммуникатор интер- или интра-коммуникатором, используется функция MPI_COMM_TEST_INTER. Интер-коммуникаторы могут использоваться как аргументы для некоторых функций доступа к коммуникаторам. Интер-коммуникаторы не могут использоваться как вход для некоторых процедур создания интра-коммуникаторов (например, MPI_COMM_CREATE).
Совет разработчикам: Для целей парного обмена коммуникаторы могут быть представлены в каждом процессе кортежем, состоящим из:
Для интер-коммуникаторов аргумент group описывает удаленную группу, а source - номер процесса в локальной группе. Для интра-коммуникаторов group является коммуникаторной группой, source - номером процесса в этой группе, а send_context и receive_context идентичны. Группа представлена таблицей ``номер - абсолютный адрес''.
При обсуждении интер-коммуникатора важно изучить процессы в локальных и
удаленных группах. Рассмотрим процесс P в группе ![]() , которая имеет интеркоммуникатор Cp, и процесс Q в группе Q, которая имеет интеркоммуникатор С
, которая имеет интеркоммуникатор Cp, и процесс Q в группе Q, которая имеет интеркоммуникатор С![]() Тогда
Тогда
Cp.receive_context = C![]() .
send_context и этот контекст уникален в P.
.
send_context и этот контекст уникален в P.
Пусть P посылает сообщение Q, используя интер-коммуникатор. Тогда P использует таблицу group, чтобы найти абсолютный адрес Q; source и send_context добавлены в конец сообщения.
Пусть Q запускает прием с явным аргументом отправителя, используя интер-коммуникатор. Тогда Q сопоставляет receive_context с контекстом сообщения, а аргумент источника - с источником сообщения.
Такой же алгоритм пригоден и для интракоммуникаторов.
Чтобы поддерживать конструкторы и средства доступа к интер-коммуникаторам, необходимо расширить эту модель дополнительными структурами, которые сохраняют информацию о локальной коммуникационной группе, и дополнительными контекстами защиты.[]
Синтаксис функции MPI_COMM_TEST_INTER представлен ниже.
MPI_COMM_TEST_INTER(comm, flag)
| IN | comm | коммуникатор (дескриптор) | |
| OUT | flag | (логическое значение) |
int MPI_Comm_test_inter(MPI_Comm comm, int *flag)
MPI_COMM_TEST_INTER(COMM, FLAG, IERROR)
INTEGER COMM, IERROR
LOGICAL FLAG
bool MPI::Comm::Is_inter() const
Эта локальная функция позволяет вызывающему процессу определять, является ли коммуникатор интер-коммуникатором или интра-коммуникатором. Она возвращает true, если это интер-коммуникатор, и false в противном случае.
Когда интер-коммуникатор используется как входной аргумент к средствам доступа коммуникатора, поведение функции описывается следующей таблицей.
|
MPI_COMM_*
|
|
|
Поведение функции |
|
| MPI_COMM_SIZE | возвращает размер локальной группы. |
| MPI_COMM_GROUP | возвращает локальную группу. |
| MPI_COMM_RANK | возвращает номер в локальной группе. |
Кроме того, операция MPI_COMM_COMPARE применима и для интер-коммуникаторов. Оба коммуникатора должны быть или интра- или интер-коммуникаторами, иначе возвращается значение MPI_UNEQUAL. Локальная и удаленная группы должны соответствовать друг другу, чтобы получить в результате MPI_CONGRUENT и MPI_SIMILAR. В частности, результат MPI_SIMILAR возможен в случае, когда локальная и удаленная группы были похожими, но не идентичными.
Следующие средства обеспечивают непротиворечивый доступ к удаленной группе интеркоммуникатора (операции являются локальными).
Синтаксис функции MPI_COMM_REMOTE_SIZE представлен ниже.
MPI_COMM_REMOTE_SIZE(comm, size)
| IN | comm | интеркоммуникатор (дескриптор) | |
| OUT | size | количество процессов в удаленной группе comm (целое) |
int MPI_Comm_remote_size(MPI_Comm comm, int *size)
MPI_COMM_REMOTE_SIZE(COMM, SIZE, IERROR)
INTEGER COMM, SIZE, IERROR
int MPI::Intercomm::Get_remote_size() const
Синтаксис функции MPI_COMM_REMOTE_GROUP представлен ниже.
MPI_COMM_REMOTE_GROUP(comm, group)
| IN | comm | интеркоммуникатор (дескриптор) | |
| OUT | group | удаленная группа, соответствующая comm (дескриптор) |
int MPI_Comm_remote_group(MPI_Comm comm, MPI_Group *group)
MPI_COMM_REMOTE_GROUP(COMM, GROUP, IERROR)
INTEGER COMM, GROUP, IERROR
MPI::Group MPI::Intercomm::Get_remote_group() const
Объяснение: Важно, чтобы доступ к локальным и удаленным группам
интер-коммуникатора был симметричным, поэтому была введена функция
MPI_COMM_REMOTE_GROUP в дополнение к
MPI_COMM_REMOTE_SIZE.[]
Этот раздел представляет четыре блокирующих операции интер-коммуникатора.
Фунция
MPI_INTERCOMM_CREATE используется для объединения двух
интра-коммуникаторов в интер-комму-никатор; функция MPI_INTERCOMM_MERGE создает интра-коммуникатор, объединяя локальную и
удаленную группы интер-коммуникатора. Функции MPI_COMM_DUP и
MPI_COMM_FREE, введенные ранее, соответственно дублируют и
удаляют интер-коммуникатор.
Перекрытие локальной и удаленной групп, которые связаны в интер-коммуникатор, запрещено. Если имеется перекрытие, то программа неверна и вероятен дедлок. (Если процесс многопоточный и запросы MPI блокируют только поток, а не процесс, то может быть поддержано ``двойное членство''. Это возможно тогда, когда пользователь гарантирует, что вызовы от имени двух ``ролей'' процесса выполнены двумя независимыми потоками.)
Функция MPI_INTERCOMM_CREATE может использоваться для создания интер-коммуникатор из двух существующих интра-коммуникаторов в следующей ситуации: по крайней мере один выделенный член от каждой группы (``лидер группы'') имеет способность обмениваться с выделенным членом от другой группы; то есть существует коммуникатор, в котором оба лидера равноправны и каждый лидер знает номер другого лидера в этом коммуникаторе (эти два лидера могут быть одним и тем же процессом). Кроме того, члены каждой группы знают номер их лидера.
Конструирование интер-коммуникатора из двух интра-коммуникаторов требует отдельных коллективных операций в локальной и удаленной группах, также как и парного обмена между процессами в локальной и удаленной группах.
В стандартной реализации MPI (со статическим распределением процессов при инициализации) коммуникатор MPI_COMM_WORLD (или специализированный коммуникатор, дублирующий его, что предпочтительнее) может быть этим коммуникатором, обеспечивающим равноправие. В динамических реализациях MPI, где процесс может порождать новые дочерние процессы во время выполнения программы MPI, родительский процесс может быть ``мостом'' между старой и новой областью обмена.
Прикладные функции топологии, описанные в главе 6, не применимы к интер-коммуникаторам. Пользователи, которым это нужно, должны использовать MPI_INTERCOMM_MERGE, чтобы построить интра-коммуникатор, а затем уже применять древовидную или декартову топологию к этому интра-коммуникатору, создавая соответствующий настроенный на выбранную топологию интра-коммуникатор. Пользователь имеет возможность создавать для этого случая и собственные прикладные топологические механизмы.
Синтаксис функции MPI_INTERCOMM_CREATE представлен ниже.
MPI_INTERCOMM_CREATE(local_comm,local_leader,peer_comm,remote_leader,tag,newintercomm)
| IN | local_comm | локальный интракоммуникатор (дескриптор) | |
| IN | local_leader | номер лидера локальной группы в local_comm (целое) | |
| IN | peer_comm | ``уравнивающий коммуникатор'', используется только на local_leader (дескриптор) | |
| IN | remote_leader | номер лидера удаленной группы в peer_comm, используется только на local_leader (целое) | |
| IN | tag | тэг <безопасности> (целое) | |
| OUT | newintercomm | новый интеркоммуникатор (дескриптор) |
int MPI_Intercomm_create(MPI_Comm local_comm,
int local_leader, MPI_Comm peer_comm,
int remote_leader, int tag, MPI_Comm *newintercomm)
MPI_INTERCOMM_CREATE(LOCAL_COMM, LOCAL_LEADER, PEER_COMM,
REMOTE_LEADER, TAG, NEWINTERCOMM, IERROR)
INTEGER LOCAL_COMM, LOCAL_LEADER, PEER_COMM,
REMOTE_LEADER, TAG, NEWINTERCOMM, IERROR
MPI::Intercomm MPI::Intracomm::Create_intercomm(
int local_leader, const MPI::Comm& peer_comm,
int remote_leader, int tag) const
Функция MPI_INTERCOMM_CREATE создает интер-коммуникатор. Это коллективная операция над объединением локальной и удаленной групп. Процессы должны обеспечить идентичные аргументы local_comm и local_leader в пределах каждой группы. Неопределенность в задании номеров процессов не допускается для remote_leader, local_leader, и тэга.
Этот запрос использует двухточечный обмен между лидерами через коммуникатор peer_comm с тэгом tag. Поэтому нужно принять меры, чтобы на peer_comm отсутствовали ждущие обмены, которые могли бы взаимодействовать с этим обменом.
Совет пользователям: Рекомендуется использовать выделенный peer-коммуникатор, например, дубликат коммуникатора MPI_COMM_WORLD, чтобы избежать неприятностей с peer-коммуника-торами.[]
Синтаксис функции MPI_INTERCOMM_MERGE представлен ниже.
MPI_INTERCOMM_MERGE(intercomm, high, newintracomm)
| IN | intercomm | интеркоммуникатор (дескриптор) | |
| IN | high | (логическое значение) | |
| OUT | newintracomm | новый интракоммуникатор (дескриптор) |
int MPI_Intercomm_merge(MPI_Comm intercomm,
int high, MPI_Comm *newintracomm)
MPI_INTERCOMM_MERGE(INTERCOMM, HIGH, INTRACOMM, IERROR)
INTEGER INTERCOMM, INTRACOMM, IERROR
LOGICAL HIGH
MPI::Intracomm MPI::Intercomm::Merge(bool high) const
Эта функция создает интра-коммуникатор путем объединения двух групп, которые связаны с intercomm. Все процессы должны обеспечить одинаковое значение high в пределах каждой из этих двух групп. Если процессы в одной группе имеют значение high = false, а процессы в другой группе - значение high = true, тогда объединение помещает ``low'' группу перед ``high'' группой. Если все процессы имеют одинаковый аргумент high, тогда порядок объединения произвольный. Этот запрос является блокирующим и коллективен в пределах объединения из этих двух групп.
Совет разработчикам: Выполнение MPI_INTERCOMM_MERGE, MPI_COMM_FREE и MPI_COMM_DUP похоже на реализацию MPI_INTERCOMM_CREATE, за исключением того, что для обмена между лидерами группы чаще используются контексты, частные по отношению ко входному интер-коммуникатору, а не контексты внутри коммуникатора-моста.[]
Обмениваются группы 0 и 1, затем группы 1 и 2. Поэтому, группа 0 требует один интер-коммуникатор, группа 1 требует два интер-коммуникатора и группа 2 требует 1 интер-коммуникатор.
main(int argc, char **argv)
{
MPI_Comm myComm; /* интракоммуникатор локальной
подгруппы */
MPI_Comm myFirstComm; /* интеркоммуникатор */
MPI_Comm mySecondComm; /* второй интеркоммуникатор
(только группа 1) */
int membershipKey;
int rank;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
/* код пользователя обязан генерировать ключ
принадлежности в диапазоне [0, 1, 2] */
membershipKey = rank % 3;
/* формирование интра-коммуникатора для локальной подгруппы */
MPI_Comm_split(MPI_COMM_WORLD, membershipKey, rank, &myComm);
/* формирование интер-коммуникаторов
*/
if (membershipKey == 0)
{ /* Группа 0 связывается с группой 1 */
MPI_Intercomm_create(myComm, 0,
MPI_COMM_WORLD, 1, 1, &myFirstComm);
}
else if (membershipKey == 1)
{ /* Группа 1 связывается с группами 0 и 2. */
MPI_Intercomm_create(myComm, 0, MPI_COMM_WORLD,
0, 1, &myFirstComm);
MPI_Intercomm_create(myComm, 0, MPI_COMM_WORLD,
2, 12, &mySecondComm);
}
else if (membershipKey == 2)
{ /* Группа 2 связывается с группой 1. */
MPI_Intercomm_create(myComm, 0, MPI_COMM_WORLD,
1, 12, &myFirstComm);
}
/* рабочий участок ... */
switch(membershipKey) /* удаление коммуникаторов
*/
{
case 1:
MPI_Comm_free(&mySecondComm);
case 0:
case 2:
MPI_Comm_free(&myFirstComm);
break;
}
MPI_Finalize();
}
Пример 2: Кольцо из трех групп
Обмениваются группы 0 и 1, группы 1 и 2, группы 0 и 2. Следовательно, каждая группа требует два интеркоммуникатора.
main(int argc, char **argv)
{
MPI_Comm myComm; /* интра-коммуникатор для локальной
подгруппы */
MPI_Comm myFirstComm; /* интер-коммуникатор */
MPI_Comm mySecondComm;
MPI_Status status;
int membershipKey;
int rank;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
...
/* код пользователя должен генерировать ключ принадлежности в
диапазоне [0, 1, 2] */
membershipKey = rank % 3;
/* формирование интра-коммуникатора для локальной подгруппы */
MPI_Comm_split(MPI_COMM_WORLD, membershipKey, rank, &myComm);
/* формирование интер-коммуникаторов. */
if (membershipKey == 0)
{ /* Группа 0 связывается с группами 1 и 2. */
MPI_Intercomm_create(myComm, 0, MPI_COMM_WORLD, 1,
1, &myFirstComm);
MPI_Intercomm_create(myComm, 0, MPI_COMM_WORLD, 2,
2, &mySecondComm);
}
else if (membershipKey == 1)
{ /* Группа 1 связывается с группами 0 и 2. */
MPI_Intercomm_create(myComm, 0, MPI_COMM_WORLD, 0,
1, &myFirstComm);
MPI_Intercomm_create(myComm, 0, MPI_COMM_WORLD, 2,
12, &mySecondComm);
}
else if (membershipKey == 2)
{ /* Группа 1 связывается с группами 0 и 1. */
MPI_Intercomm_create(myComm, 0, MPI_COMM_WORLD, 0,
2, &myFirstComm);
MPI_Intercomm_create(myComm, 0, MPI_COMM_WORLD, 1,
12, &mySecondComm);
}
/* выполнение некоторой работы ... */
/* Теперь освобождаем коммуникаторы перед окончанием... */
MPI_Comm_free(&myFirstComm);
MPI_Comm_free(&mySecondComm);
MPI_Comm_free(&myComm);
MPI_Finalize();
}
Пример 3: Формирование службы имен для интер-коммуникации
Следующие подпрограммы показывают, как пользователь может создавать службу имен (name service) для интер-коммуникаторов на основе протокола рандеву (rendezvous) с использованием серверного коммуникатора и имени тэга, выбранного обеими группами.
После того, как все процессы MPI выполнят MPI_INIT, каждый процесс вызывает функцию Init_server(), определенную ниже. Тогда, если new_world возвращает NULL, необходим процесс, получающий NULL, чтобы осуществить функцию сервера в цикле Do_server(). Все остальные процессы делают только предписанные им вычисления, используя new_world как новый эффективный ``глобальный'' коммуникатор. Один определенный процесс вызывает Undo_Server(), чтобы избавиться от сервера, когда он больше не требуется.
Особенности этого подхода включают:
#define INIT_SERVER_TAG_1 666
#define UNDO_SERVER_TAG_1 777
static int server_key_val;
/* для управления атрибутами на server_comm
используется функция копирования: */
void handle_copy_fn(MPI_Comm *oldcomm, int *keyval,
void *extra_state, void *attribute_val_in,
void **attribute_val_out, int *flag)
{
/* копирование дескриптора */
*attribute_val_out = attribute_val_in;
*flag = 1; /* указывает, что копирование произошло */
}
int Init_server(peer_comm, rank_of_server,
server_comm, new_world)
MPI_Comm peer_comm;
int rank_of_server;
MPI_Comm *server_comm;
MPI_Comm *new_world;
{
MPI_Comm temp_comm, lone_comm;
MPI_Group peer_group, temp_group;
int rank_in_peer_comm, size, color, key = 0;
int peer_leader, peer_leader_rank_in_temp_comm;
MPI_Comm_rank(peer_comm, &rank_in_peer_comm);
MPI_Comm_size(peer_comm, &size);
if ((size < 2)||(0 > rank_of_server)
||(rank_of_server >= size))
return (MPI_ERR_OTHER);
/* создаются два коммуникатора путем разбиния peer_comm на
процесс сервера и какой-либо еще */
/* произвольный выбор */
peer_leader = (rank_of_server + 1) % size;
if ((color = (rank_in_peer_comm == rank_of_server)))
{
MPI_Comm_split(peer_comm, color, key, &lone_comm);
MPI_Intercomm_create(lone_comm, 0, peer_comm,
peer_leader, INIT_SERVER_TAG_1, server_comm);
MPI_Comm_free(&lone_comm);
*new_world = MPI_COMM_NULL;
}
else
{
MPI_Comm_Split(peer_comm, color, key, &temp_comm);
MPI_Comm_group(peer_comm, &peer_group);
MPI_Comm_group(temp_comm, &temp_group);
MPI_Group_translate_ranks(peer_group, 1, &peer_leader,
temp_group, &peer_leader_rank_in_temp_comm);
MPI_Intercomm_create(temp_comm,
peer_leader_rank_in_temp_comm,
peer_comm, rank_of_server,
INIT_SERVER_TAG_1, server_comm);
/* присоединяется коммуникационный атрибут new_world к
server_comm: */
/* КРИТИЧЕСКАЯ СЕКЦИЯ ДЛЯ MULTITHREADING */
if(server_keyval == MPI_KEYVAL_INVALID)
{
/* получить локальное имя процесса для
значения ключа сервера */
MPI_keyval_create(handle_copy_fn, NULL,
&server_keyval, NULL);
}
*new_world = temp_comm;
/* кэшировать дескриптор интра-коммуникатора на
интер-коммуникаторе: */
MPI_Attr_put(server_comm, server_keyval, (void*)
(*new_world));
}
return (MPI_SUCCESS);
}
Фактический процесс сервера передал бы на выполнение следующий код:
int Do_server(server_comm)
MPI_Comm server_comm;
{
void init_queue();
int en_queue(), de_queue();
/* Сохранить триплеты целых чисел для
последующего cравнения */
MPI_Comm comm;
MPI_Status status;
int client_tag, client_source;
int client_rank_in_new_world,
pairs_rank_in_new_world;
int buffer[10], count = 1;
void *queue;
init_queue(&queue);
for (;;)
{
MPI_Recv(buffer, count, MPI_INT, MPI_ANY_SOURCE,
MPI_ANY_TAG, server_comm, &status);
/* прием от любого клиента */
/* Определяется клиент: */
client_tag = status.MPI_TAG;
client_source = status.MPI_SOURCE;
client_rank_in_new_world = buffer[0];
if (client_tag == UNDO_SERVER_TAG_1)
/* Клиент, который завершает работу сервера */
{
while(de_queue(queue,MPI_ANY_TAG,
&pairs_rank_in_new_world, &pairs_rank_in_server));
MPI_Intercomm_free(&server_comm);
break;
}
if (de_queue(queue, client_tag, &pairs_rank_in_new_world,
&pairs_rank_in_server))
{
/* согласованная пара с одинаковым тэгом, необходимо
сообщить им друг о друге! */
buffer[0] = pairs_rank_in_new_world;
MPI_Send(buffer, 1, MPI_INT, client_src, client_tag,
server_comm);
buffer[0] = client_rank_in_new_world;
MPI_Send(buffer, 1, MPI_INT, pairs_rank_in_server,
client_tag, server_comm);
}
else
en_queue(queue, client_tag, client_source,
client_rank_in_new_world);
}
}
Особый процесс отвечает за окончание работы сервера, когда он больше не нужен, вызывая Undo_server.
int Undo_server(server_comm)
/* пример клиента, который заканчивает
работу сервера */
MPI_Comm *server_comm;
{
int buffer = 0;
MPI_Send(&buffer,1, MPI_INT, 0, UNDO_SERVER_TAG_1, *server_comm);
MPI_Intercomm_free(server_comm);
}
Следующий код - это код блокирования сервисов имен для интер-коммуникации с теми же самыми семантическими ограничениями, как в MPI_Intercomm_create, но с упрощенным синтаксисом. Он использует функциональные возможности, определенные только для создания службы имен.
int Intercomm_name_create(local_comm, server_comm, tag, comm)
MPI_Comm local_comm, server_comm;
int tag;
MPI_Comm *comm;
{
int error;
int found; /* получение атрибута mgmt для new_world */
void *val;
MPI_Comm new_world;
int buffer[10], rank;
int local_leader = 0;
MPI_Attr_get(server_comm, server_keyval,
&val, &found);
new_world = (MPI_Comm)val;
/* восстановление кэшированного
дескриптора */
MPI_Comm_rank(server_comm, &rank);
/* номер в локальной группе */
if (rank == local_leader)
{
buffer[0] = rank;
MPI_Send(&buffer, 1, MPI_INT, 0, tag, server_comm);
MPI_Recv(&buffer, 1, MPI_INT, 0, tag, server_comm);
}
error = MPI_Intercomm_create(local_comm, local_leader, new_world,
buffer[0], tag, comm);
return(error);
}
В MPI используется ``кэширование'' - средство, которое позволяет приложению присоединять произвольные единицы информации, называемые атрибутами, к коммуникаторам. Если быть более точным, кэширование позволяет мобильной библиотеке делать следующее:
Возможности кэширования в некоторой форме используются встроенными в MPI процедурами, например, процедурами коллективного обмена и топологии. Включение интерфейса этих возможностей в стандарт MPI полезно, поскольку это позволяет реализовать процедуры, например, для коллективного обмена или прикладной топологии в виде мобильного кода, а также потому, что это позволяет пользовательским процедурам использовать стандартные последовательности вызовов MPI.
Совет пользователям: Коммуникатор MPI_COMM_SELF - подходящий выбор для регистрации локальных для процесса атрибутов через механизм кэширования атрибутов.[]
В этом разделе определяются термины и соглашения, используемые в настоящем документе, и причины выбора некоторых из них.
Атрибуты присоединяются к коммуникаторам. Они локальны по отношению к процессу и специфичны по отношению к коммуникатору, к которому подключены. Атрибуты не передаются MPI от одного коммуникатора к другому кроме случая, когда коммуникатор дублируется с помощью MPI_COMM_DUP (и даже тогда приложение должно дать специальное разрешение через функции обратного вызова для копирования атрибута).
Совет пользователям: Атрибуты в языке Си имеют тип void *. Как правило, такой атрибут будет указателем на структуру, которая содержит дальнейшую информацию, или дескриптором для объекта MPI. В языке ФОРТРАН атрибуты имеют тип integer. Такой атрибут может быть дескриптором для объекта MPI или просто целочисленным атрибутом.[]
Совет разработчикам: Атрибуты являются скалярными величинами, равными или большими по размеру, чем указатель в языке Си. Атрибуты могут всегда хранить дескриптор MPI.[]
Интерфейс кэширования, определенный здесь, предполагает, что атрибуты хранятся в MPI скрытыми внутри коммуникатора. Функции доступа включают следующее:
Совет разработчикам: Кэширование и функции обратного вызова вызываются только синхронно, в ответ на явные запросы приложения. Это избавляет от проблем, которые возникают из-за повторных пересечений между пространствоми системы и пользователя. (Правило синхронного вызова - общее свойство MPI.)
Выбор значений ключей находится под контролем MPI. Это позволяет MPI оптимизировать реализацию наборов атрибутов и позволяет избежать конфликта между независимыми модулями, которые выполняют кэширование информации на одинаковых коммуникаторах.
Полные возможности кэширования можно реализовать и с минимальным интерфейсом, состоящим только из средств обратного вызова. Но такой минимальный интерфейс требует для обработки произвольных коммуникаторов некоторой формы табличного поиска. Напротив, более законченный интерфейс, определенный здесь, разрешает быстрый доступ к атрибутам с помощью указателей в коммуникаторах (чтобы найти таблицу атрибута) и разумно выбранных значений ключей (чтобы восстановить индивидуальные атрибуты).[]
MPI предоставляет следующие средства, связанные с кэшированием. Все они локальны для процессов.
Синтаксис функции MPI_KEYVAL_CREATE представлен ниже.
MPI_KEYVAL_CREATE(copy_fn, delete_fn, keyval, extra_state)
| IN | copy_fn | функция обратного вызова для копирования keyval | |
| IN | delete_fn | функция обратного вызова для удаления keyval | |
| OUT | keyval | значение ключа для будущего доступа (целое) | |
| IN | extra_state | дополнительное состояние для функций обратного вызова |
int MPI_Keyval_create(MPI_Copy_function *copy_fn,
MPI_Delete_function *delete_fn,
int *keyval, void *extra_state)
MPI_KEYVAL_CREATE(COPY_FN, DELETE_FN, KEYVAL, EXTRA_STATE, IERROR)
EXTERNAL COPY_FN, DELETE_FN
INTEGER KEYVAL, EXTRA_STATE, IERROR
Функция MPI_KEYVAL_CREATE генерирует новый ключ атрибута. Ключи локально уникальны в процессе и скрыты от пользователя, хотя они явно хранятся как целые числа. Однажды созданное значение ключа может использоваться для связывания атрибутов и обращения к ним на любом локально определенном коммуникаторе.
Функция copy_fn вызывается, когда коммуникатор дублируется функцией MPI_COMM_DUP. Функция сopy_fn должна иметь тип MPI_Copy_function, который определяется следующим образом:
typedef int MPI_Copy_function(MPI_Comm oldcomm, int keyval, void *extra_state,
void *attribute_val_in, void *attribute_val_out, int *flag)
Объявление в языке ФОРТРАН для такой функции следующее:
SUBROUTINE COPY_FUNCTION(OLDCOMM, KEYVAL, EXTRA_STATE,
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT, FLAG, IERR)
INTEGER OLDCOMM, KEYVAL, EXTRA_STATE, ATTRIBUTE_VAL_IN,
ATTRIBUTE_VAL_OUT, IERR
LOGICAL FLAG
Функция обратного вызова на копирование вызывается для каждого значения ключа в oldcomm в произвольном порядке. Каждый запрос на копирование делается с ключевым значением и соответствующим ему атрибутом. Если вызов возвращает flag = 0, то атрибут в дублированном коммуникаторе удален. В противном случае (flag = 1) новое значение атрибута принимает значение, возвращенное в attribute_val_out. Функция возвращает MPI_SUCCESS при успехе и код ошибки при отказе (когда MPI_COMM_DUP не может быть выполнен).
Функция сopy_fn может быть определена как MPI_NULL_COPY_FN или MPI_DUP_FN из Си или ФОРТРАН;
MPI_NULL_COPY_FN есть функция, которая не
делает ничего другого, кроме возвращения flag = 0 и MPI_SUCCESS. MPI_DUP_FN есть простая функция копирования,
которая устанавливает flag = 1, возвращает значение attribute_val_in в attribute_val_out и возвращает
MPI_SUCCESS.
Совет пользователям: Несмотря на то, что формальные параметры attribute_val_in и attribute_val_out имеют тип void *, их использование отличается. Функция копирования в языке Си передает с помощью MPI в attribute_val_in значение атрибута и в attribute_val_out - адрес атрибута, чтобы позволить функции возвращать (новое) значение атрибута. Использование типа void * для обеих функций необходимо, чтобы избежать беспорядочных приведений типа.
Правильная функция копирования есть функция, которая полностью дублирует информацию, делая полную копию структур данных, соответствующих атрибуту; другая функция копирования может только делать другую ссылку на эту структуру данных, используя механизм счета ссылок.[]
Совет разработчикам: Для копирования и удаления функций, связанных со значениями ключей, созданных в Си, должен использоваться интерфейс языка Си; интерфейс языка ФОРТРАН должен использоваться для ключевых значений, созданных в языке ФОРТРАН.[]
Аналогичной copy_fn является функция обратного вызова для удаления. Функция delete_fn вызывается, когда коммуникатор удаляется функцией MPI_COMM_FREE. Функция delete_fn должна иметь тип MPI_Delete_function, который определяется следующим образом:
typedef int MPI_Delete_function(MPI_Comm comm, int keyval,
void *attribute_val, void *extra_state);
Декларация для такой функции в языке ФОРТРАН следующая:
SUBROUTINE DELETE_FUNCTION(COMM, KEYVAL, ATTRIBUTE_VAL,
EXTRA_STATE, IERR)
INTEGER COMM, KEYVAL, ATTRIBUTE_VAL, EXTRA_STATE, IERR
Эта функция вызывается функциями MPI_COMM_FREE, MPI_ATTR_DELETE и MPI_ATTR_PUT, чтобы, когда это необходимо, удалить атрибут. Функция возвращает MPI_SUCCESS при успехе и код ошибки при неудаче (когда MPI_COMM_FREE не может быть выполнена.).
Функция delete_fn может быть определена как MPI_NULL_DELETE_FN в Си и ФОРТРАН; это тип функции, которая не делает ничего другого, кроме возвращения MPI_SUCCESS.
Функция MPI_KEYVAL_CREATE никогда не возвращает специальное
ключевое значение
MPI_KEYVAL_INVALID, поэтому она может
использоваться для статической инициализации значений ключей.
Синтаксис функции MPI_KEYVAL_FREE представлен ниже.
MPI_KEYVAL_FREE(keyval)
| INOUT | keyval | освобождает целочисленное значение ключа (целое) |
int MPI_Keyval_free(int *keyval)
MPI_KEYVAL_FREE(KEYVAL, IERROR)
INTEGER KEYVAL, IERROR
Функция MPI_KEYVAL_FREE освобождает существующий ключ атрибута. Эта функция устанавливает значение keyval в MPI_KEYVAL_INVALID. Заметим, что освобождение ключа атрибута, который находится в использовании, не является ошибкой, потому что фактически свободным он не cтановится, пока все ссылки (в других коммуникаторах на этом процессе) на этот ключ не будут освобождены. Эти ссылки должны быть явно удалены программой или через запросы к MPI_ATTR_DELETE, которые освобождают один экземпляр атрибута, или запросами к MPI_COMM_FREE, которые освобождают все экземпляры атрибута, связанные с удаленным коммуникатором.
Синтаксис функции MPI_ATTR_PUT представлен ниже.
MPI_ATTR_PUT(comm, keyval, attribute_val)
| IN | comm | коммуникатор, к которому будет присоединен атрибут (дескриптор) | |
| IN | keyval | ключевое значение, возвращаемое MPI_KEYVAL_CREATE (целое) | |
| IN | attribute_val | значение атрибута |
int MPI_Attr_put(MPI_Comm comm, int keyval, void *attribute_val)
MPI_ATTR_PUT(COMM, KEYVAL, ATTRIBUTE_VAL, IERROR)
INTEGER COMM, KEYVAL, ATTRIBUTE_VAL, IERROR
Функция MPI_ATTR_PUT сохраняет предусмотренное значение атрибута attribute_val для последующего восстановления функцией MPI_ATTR_GET. Если значение уже представлено, то результат будет таким, как если бы MPI_ATTR_DELETE сначала вызывалась, чтобы удалить предыдущее значение (и функция delete_fn была выполнена), и затем было сохранено новое значение. Запрос неверен, если отсутствует ключ со значением keyval; в частности MPI_KEYVAL_INVALID - неверное значение ключа. Запрос не выполнится, если функция delete_fn возвратила код ошибки вместо MPI_SUCCESS.
Синтаксис функции MPI_ATTR_GET представлен ниже.
MPI_ATTR_GET(comm, keyval, attribute_val, flag)
| IN | comm | коммуникатор, к которому будет присоединен атрибут (дескриптор) | |
| IN | keyval | значение ключа (целое) | |
| OUT | attribute_val | значение атрибута, пока не станет flag = false | |
| OUT | flag | true, если значение атрибута было извлечено; false, если ни один атрибут не связан с ключом |
int MPI_Attr_get(MPI_Comm comm, int keyval, void *attribute_val, int *flag)
MPI_ATTR_GET(COMM, KEYVAL, ATTRIBUTE_VAL, FLAG, IERROR)
INTEGER COMM, KEYVAL, ATTRIBUTE_VAL, IERROR
LOGICAL FLAG
Функция MPI_ATTR_GET восстанавливает значение атрибута по ключу. Запрос ошибочен, если отсутствует ключ со значением keyval. С другой стороны, запрос правилен, если значение ключа существует, но ни один атрибут не присоединен к comm для этого ключа; в этом случае, запрос возвращает flag = false. В частности MPI_KEYVAL_INVALID - неверное значение ключа.
Совет пользователям: Запрос к MPI_ATTR_PUT передает в attribute_val значение атрибута; запрос к MPI_ATTR_GET передает в attribute_val адрес ячейки, куда должно быть возвращено значение атрибута. Таким образом, если само значение атрибута является указателем типа void*, фактический attribute_val параметр для MPI_ATTR_PUT будет иметь тип void*, и фактический attribute_val параметр для MPI_ATTR_PUT будет иметь тип void **.[]
Объяснение: Использование формального параметра attribute_val или типа void* (а не void**) позволяет избежать неупорядоченного приведения типа, которое было бы необходимо, если бы тип значения атрибута отличался от void*.[]
Синтаксис функции MPI_ATTR_DELETE представлен ниже.
MPI_ATTR_DELETE(comm, keyval)
| IN | comm | коммуникатор, к которому будет присоединен атрибут (дескриптор) | |
| IN | keyval | значение ключа удаленного атрибута (целое) |
int MPI_Attr_delete(MPI_Comm comm, int keyval)
MPI_ATTR_DELETE(COMM, KEYVAL, IERROR)
INTEGER COMM, KEYVAL, IERROR
Функция MPI_ATTR_DELETE удаляет атрибут из кэша с помощью ключа. Эта функция вызывает функцию удаления атрибута delete_fn, определенную во время создания keyval. Вызов не будет выполнен, если функция delete_fn возвращает код ошибки, а не MPI_SUCCESS.
Всякий раз, когда коммуникатор копируется функцией MPI_COMM_DUP, вызываются (в произвольном порядке) все установленные на этот момент функции обратного вызова для копирования атрибутов. Всякий раз, когда коммуникатор удаляется функцией MPI_COMM_FREE, вызываются все установленные функции обратного вызова для удаления атрибутов.
Совет пользователям: Этот пример показывает, как написать коллективную операцию обмена, которая использует кэширование для повышения эффективности после первого вызова. Стиль кодирования предполагает, что в результатах функции MPI возвращаются только ошибочные статусы.[]
/* ключ для этого модуля: */
static int gop_key = MPI_KEYVAL_INVALID;
typedef struct
{
int ref_count; /* счетчик ссылок */
/* другие обьявления, если они понадобятся */
} gop_stuff_type;
Efficient_Collective_Op (comm, ...)
MPI_Comm comm;
{
gop_stuff_type *gop_stuff;
MPI_Group group;
int foundflag;
MPI_Comm_group(comm, &group);
if (gop_key == MPI_KEYVAL_INVALID) /* Получение ключа на первом
вызове */
{
if (! MPI_Keyval_create(gop_stuff_copier,
gop_stuff_destructor,
&gop_key, (void *)0));
/* Получение ключа при назначении его копии, и исключение
действия обратного вызова. */
MPI_Abort (comm, 99);
}
MPI_Attr_get (comm, gop_key, &gop_stuff, &foundflag);
if (foundflag)
/* Этот модуль уже выполнился в этой группе.
Далее будет использоватся кэшируемая информация */
}
else
{/* Эта группа еще не была кэширована.
Это будет сделано сейчас. */
/* Во-первых, следует выделить память для нужных данных
и инициализировать cчетчик ссылки */
gop_stuff = gop_stuff_type *) malloc (sizeof(gop_stuff_type));
if (gop_stuff == NULL) { /* прерывается по ошибке нехватки
памяти */}
gop_stuff -> ref_count = 1;
/* Во вторых, следует заполнить *gop_stuff желаемым значени
ем.Эта часть здесь не показана */
/* Третье, следует сохранить gop_stuff как значение атрибута
*/
MPI_Attr_put (comm, gop_key, gop_stuff);
}
/* Затем, в любом случае, следует использовать значение
*gop_stuff, чтобы выполнить глобальную op ... */
}
/* Следующая подпрограмма вызывается MPI, когда группа удаляется
*/
gop_stuff_destructor (comm, keyval, gop_stuff, extra)
MPI_Comm comm;
int keyval;
gop_stuff_type *gop_stuff;
void *extra;
{
if (keyval != gop_key) { /* Прекращение работы из-за ошибки
программы*/ }
/* Освобождаемая группа удаляет одну ссылку на gop_stuff */
gop_stuff -> ref_count -= 1;
/* Если не осталось ни одной ссылки, то освобождаетcя память*/
if (gop_stuff -> ref_count == 0) {
free((void *)gop_stuff);
}
}
/* Следующая подпрограмма вызывается MPI, когда группа скопирована
*/
gop_stuff_copier (comm, keyval, extra, gop_stuff_in,
gop_stuff_out, flag)
MPI_Comm comm;
int keyval;
gop_stuff_type *gop_stuff_in, *gop_stuff_out;
void *extra;
{
if (keyval != gop_key) { /* Прекращение работы из-за ошибки
программы*/ }
/* Новая группа добавляет одну ссылку к gop_stuff */
gop_stuff -> ref_count += 1;
gop_stuff_out = gop_stuff_in;
}
MPI-2 вводит новые функции кэширования атрибутов по следующим двум причинам:
Прежние функции кэширования, хотя они и устарели, по-прежнему являются частью стандарта MPI.
Устаревшие функции кэширования для MPI-I перечислены ниже. Нейтральные по отношению к языку определения и привязки для Си те же самые. Привязки для языка ФОРТРАН отличаются тем, что все аргументы в новых функциях имеют тип INTEGER (KIND=MPI_INTEGER_KIND).
1) Функция MPI_KEYVAL_CREATE (даны представления для языков Си и ФОРТРАН)
MPI_KEYVAL_CREATE (copy_fn, delete_fn, keyval, extra_state)
int MPI_Keyval_create (MPI_Copy_fmiction *copy_fn,
MPI_Delete_fmiction *delete_fn, int *keyval, void* extra_state)
MPI_KEYVAL_CREATE (COPY_FN, DELETE_FN, KEYVAL, EXTRA_STATE, IERROR)
EXTERNAL COPY_FN, DELETE_FN
INTEGER KEYVAL, EXTRA_STATE, IERROR
замещается новой функцией MPI_COMM_CREATE_KEYVAL, синтаксис которой приведен ниже.
MPI_COMM_CREATE_KEYVAL(comm_copy_attr_fn,
comm_delete_attr_fn, comm_keyval, extra_state)
| IN | comm_copy_attr_fn | функция копирования для comm_keyval (функция) | |
| IN | comm_delete_attr_fn | функция удаления для comm_keyval (функция) | |
| OUT | comm_keyval | значения ключа для будущего обращения (целое) | |
| IN | extra_state | дополнительное состояние для функций обратного вызова |
int MPI_Comm_create_keyval(
MPI_Comm_copy_attr_function *comm_copy_attr_fn,
MPI_Comm_delete_attr_function *comm_delete_attr_fn,
int *comm_keyval, void *extra_state)
MPI_COMM_CREATE_KEYVAL(COMM_COPY_ATTR_FN, COMM_DELETE_ATTR_FN,
COMM_KEYVAL,
EXTRA_STATE, IERROR)
EXTERNAL COMM_COPY_ATTR_FN, COMM_DELETE_ATTR_FN
INTEGER COMM_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) EXTRA_STATE
static int MPI::Comm::Create_keyval(
MPI::Comm::Copy_attr_function* comm_copy_attr_fn,
MPI::Comm::Delete_attr_function* comm_delete_attr_fn, void* extra_state)
2) Функция MPI_KEYVAL_FREE (даны представления для языков Си и ФОРТРАН)
MPI_KEYVAL_FREE(keyval)
int MPI_Keyval_free(int *keyval)
MPI_KEYVAL_FREE(KEYVAL, IERROR)
INTEGER KEYVAL, IERROR
замещается функцией MPI_COMM_FREE_KEYVAL, синтаксис которой приведен ниже.
MPI_COMM_FREE_KEYVAL(comm_keyval)
| INOUT | comm_keyval | значение ключа (целое) |
int MPI_Comm_free_keyval(int *comm_keyval)
MPI_COMM_FREE_KEYVAL(COMM_KEYVAL, IERROR)
INTEGER COMM_KEYVAL, IERROR
static void MPI::Comm::Free_keyval(int& comm_keyval)
3) Функция MPI_ATTR_PUT (даны представления для языков Си и ФОРТРАН)
MPI_ATTR_PUT(comm, keyval, attribute_val)
int MPI_Attr_put (MPI_Conim comm, int keyval, void* attribute_val)
MPI_ATTR_PUT (COMM, KEYVAL, ATTRIBUTE_VAL, IERROR)
INTEGER COMM, KEYVAL, ATTRIBUTE_VAL, IERROR
замещается функцией MPI_COMM_SET_ATTR, синтаксис которой приведен ниже.
MPI_COMM_SET_ATTR(comm, comm_keyval, attribute_val)
| INOUT | comm | коммуникатор, из которого будут подключаться атрибуты (дескриптор) | |
| IN | comm_keyval | значение ключа (дескриптор) | |
| IN | attribute_val | значение атрибута |
int MPI_Comm_set_attr(MPI_Comm comm,
int comm_keyval, void *attribute_val)
MPI_COMM_SET_ATTR(COMM, COMM_KEYVAL, ATTRIBUTE_VAL, IERROR)
INTEGER COMM, COMM_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
void MPI::Comm::Set_attr(int comm_keyval,
const void* attribute_val) const
4) Функция MPI_ATTR_GET (даны представления для языков Си и ФОРТРАН)
MPI_ATTR_GET(comm, keyval, attribute_val, flag)
int MPI_Attr_get (MPI_Comm comm, int keyval,
void *attribute_val, int *flag)
MPI_ATTR_GET(COMM, KEYVAL, ATTRIBUTE_VAL, FLAG, IERROR)
INTEGER COMM, KEYVAL, ATTRIBUTE_VAL, IERROR LOGICAL FLAG
замещается функцией MPI_COMM_GET_ATTR, синтаксис которой представлен ниже.
MPI_COMM_GET_ATTR(comm, comm_keyval, attribute_val, flag)
| IN | comm | коммуникатор, к которому подключаются атрибуты (дескриптор) | |
| IN | comm_keyval | значение ключа (целое) | |
| OUT | attribute_val | значение атрибута, пока отсутствует состояние flag = false | |
| OUT | flag | false, если никакой атрибут не связан с ключом (логическое значение) |
int MPI_Comm_get_attr(MPI_Comm comm,
int comm_keyval, void *attribute_val, int *flag)
MPI_COMM_GET_ATTR(COMM, COMM_KEYVAL, ATTRIBUTE_VAL, FLAG, IERROR)
INTEGER COMM, COMM_KEYVAL, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ATTRIBUTE_VAL
LOGICAL FLAG
bool MPI::Comm::Get_attr(int comm_keyval,
void* attribute_val) const
5) Функция MPI_ATTR_DELETE (даны представления для языков Си и ФОРТРАН)
MPI_ATTR_DELETE(comm, keyval)
int MPI_Attr_delete(MPI_Comm comm, int keyval)
MPI_ATTR_DELETE(COMM, KEYVAL, IERROR)
INTEGER COMM, KEYVAL, IERROR
замещается функцией MPI_COMM_DELETE_ATTR, синтаксис которой представлен ниже.
MPI_COMM_DELETE_ATTR(comm, comm_keyval)
| INOUT | comm | коммуникатор, из которого удаляются атрибуты (дескриптор) | |
| IN | comm_keyval | значение ключа (целое) |
int MPI_Comm_delete_attr(MPI_Comm comm, int comm_keyval)
MPI_COMM_DELETE_ATTR(COMM, COMM_KEYVAL, IERROR)
INTEGER COMM, COMM_KEYVAL, IERROR
void MPI::Comm::Delete_attr(int comm_keyval)
В этой главе описываются топологические механизмы MPI. Топология является необязательным атрибутом, который дополняет систему интра-коммуникаторов и не применяется в интер-коммуникаторах. Топология обеспечивает удобный способ обозначения процессов в группе (внутри коммуникатора) и оказывает помощь исполнительной системе при размещении процессов в аппаратной среде.
Как было сказано в главе 5, группа процессов в MPI - это объединение n процессов. Каждому процессу в группе соответствует номер в диапазоне от 0 до n-1. Во многих параллельных приложениях линейное распределение номеров не отражает в полной мере логическую структуру обменов между процессами, которая зависит от структуры задачи и ее математического алгоритма. Часто процессы описываются в двух- и трехмерных топологических средах. Наиболее общим видом топологии является организация процессов, описываемая графовой структурой. В этой главе логическая организация процессов будет именоваться ``виртуальной топологией''.
Следует различать виртуальную топологию процессов и физическую топологию процессов. Виртуальная топология должна применяться для назначения процессов физическим процессорам, если это позволит увеличить производительность обменов на данной машине. С другой стороны, описание виртуальной топологии зависит от конкретного приложения и является машинно-независимым. Функции, предложенные в этой части, относятся только к машинно-независимым расчетам.
Объяснение: Хотя физическое размещение в настоящем стандарте не обсуждается, наличие информация о виртуальной топологии может быть использовано как подсказка для исполнительной системы. Имеются широко известные методы для размещения многомерных структур данных (матрицы, тороиды) в физической среде, такой как гиперкубы. Для более сложных графовых структур используются эвристические алгоритмы, которые дают результаты, близкие к оптимальным [20]. С другой стороны, если пользователь не может описать логическое размещение процессов как ``виртуальную топологию'', наиболее подходящим будет случайное размещение этих процессов. На некоторых машинах это может привести к конфликтам в аппаратной переключательной сети. Некоторые подробности о предсказанном и измеренном приросте производительности в результате хорошего размещения процессов по процессорам можно найти в [10,9].
Кроме возможности получить выгоду в производительности, виртуальная топология может быть использована как средство обозначения процессов, которое значительно улучшает читаемость программ.[]
Взаимосвязь процессов может быть представлена графом. Узлы такого графа представляют процессы, а ребра соответствуют связям между процессами. Стандарт MPI предусматривает передачу сообщений между любой парой процессов в группе. Не обязательно указывать канал связи явно. Следовательно, отсутствие канала связи в граф-схеме процессов не запрещает соответствующим процессам обмениваться сообщениями. Из этого следует , что такая связь в виртуальной топологии может отсутствовать, например, из-за того, что топология не представляет удобного способа обозначения этого канала обмена. Возможным следствием такого отсутствия может быть то, что автоматическая программа для размещения процессов по процессорам (если такая будет существовать) не будет учитывать эту связь, и уменьшится эффективность вычислений.
Ребра в графе не взвешены, поэтому процесс может изображаться только подключенным или не подключенным.
Объяснение: Опыт с подобными методами в PARMACS [5,8] показывает, что графовое представление вполне достаточно для построения хороших схем. Более подробное описание излишне сложно для пользователя и сделало бы интерфейсные функции MPI существенно сложнее.[]
Графовое представление топологии пригодно для всех приложений. Однако во многих приложениях графовая структура является регулярной и довольно простой, поэтому использование всех деталей графового представления будет неудобным и малоэффективным в использовании.
Большая доля всех параллельных приложений использует топологию колец, двумерных массивов или массивов большей размерности. Эти структуры полностью определяются числом размерностей и количеством процессов для каждой координаты. Кроме того, отображение решеток и торов на аппаратуру обычно более простая задача, чем отображение сложных графов.
Координаты в декартовой системе нумеруются от 0. Это означает, например, что
соотношение между номером процесса в группе и координатами в решетке
(![]() ) для четырех процессов будет следующим:
) для четырех процессов будет следующим:
| coord (0,0): | rank 0 |
| сoord (0,1): | rank 1 |
| сoord (1,0): | rank 2 |
| сoord (1,1): | rank 3 |
Средства виртуальной топологии совместимы с другими средствами MPI. Топологическая информация связана с коммуникаторами. Она вводится в коммуникатор с использованием механизма кэширования, описанного в главе 5.
Функции MPI_GRAPH_CREATE и MPI_CART_CREATE используются для создания универсальной (графовой) и декартовой топологий соответственно. Эти функции являются коллективными. Как и для других коллективных обращений, программа для работы с топологией должна быть написана корректно, вне зависимости от того, являются ли обращения синхронизированными или нет.
Функции создания топологии используют в качестве входа существующий
коммуникатор
comm_old, который определяет множество
процессов, для которых и создается топология. Новый коммуникатор comm_topol хранит топологическую структуру как кэшируемую информацию (см.
главу 5). По аналогии с функцией MPI_COMM_CREATE никакой кэшируемой
информации не передается от comm_old к comm_topol.
Функция MPI_CART_CREATE может использоваться для описания декартовой системы произвольной размерности. Для каждой координаты она определяет, является ли структура процессов периодической или нет. Таким образом, никакой специальной поддержки для структур типа гиперкуб не нужно. Локальная вспомогательная функция MPI_DIMS_CREATE используется для вычисления сбалансированности процессов для заданного количества размерностей.
Объяснение: Подобные функции содержатся в EXPRESS [22] и PARMACS.[]
Функция MPI_TOPO_TEST может использоваться для запроса о топологии, связанной с коммуникатором. Информация о топологии может быть извлечена из коммуникаторов с помощью функций MPI_GRAPHDIMS_GET и MPI_GRAPH_GET для графов и MPI_CARTDIM_GET и MPI_CART_GET - для декартовой топологии.
Несколько дополнительных функций обеспечивают работу с декартовой топологией: функции MPI_CART_RANK и MPI_CART_COORDS переводят декартовы координаты в номер группы и обратно; функция MPI_CART_SUB может использоваться для выделения декартова подпространства (аналогично функции MPI_COMM_SPLIT). Функция MPI_CART_SHIFT обеспечивает необходимую информацию для обмена между соседними процессами в декартовой системе координат.
Две функции MPI_GRAPH_NEIGHBORS_COUNT и MPI_GRAPH_NEIGHBORS используются для выделения соседних процессов на топологической схеме. Функция MPI_CART_SUB является коллективной для группы входного коммуникатора, остальные функции локальные.
В последнем разделе описаны две дополнительные функции: MPI_GRAPH_MAP и MPI_CART_MAP. В ообщем случае функции не вызываются пользователем непосредственно. Тем не менее, совместно с функциями управления коммуникаторами, представленными в главе 5, они достаточны для реализации всех других топологических функций.
Синтаксис функции CART_CREATE представлен ниже.
MPI_CART_CREATE(comm_old, ndims, dims, periods, reorder, comm_cart)
| IN | comm_old | исходный коммуникатор (дескриптор) | |
| IN | ndims | размерность создаваемой декартовой решетки (целое) | |
| IN | dims | целочисленный массив размера ndims, хранящий количество процес-сов по каждой координате | |
| IN | periods | массив логических элементов размера ndims, определяющий, перио-дична (true) или нет (false) решетка в каждой размерности | |
| IN | reorder | нумерация может быть сохранена (false) или переупорядочена (true) (логическое значение) | |
| OUT | comm_cart | коммуникатор новой декартовой топологии (дескриптор) |
int MPI_Cart_create(MPI_Comm comm_old, int ndims, int *dims,
int *periods,
int reorder, MPI_Comm *comm_cart)
MPI_CART_CREATE(COMM_OLD, NDIMS, DIMS,
PERIODS, REORDER, COMM_CART, IERROR)
INTEGER COMM_OLD, NDIMS, DIMS(*), COMM_CART, IERROR
LOGICAL PERIODS(*), REORDER
MPI::Cartcomm MPI::Intracomm::Create_cart(
int ndims, const int dims[], const bool periods[],
bool reorder) const
Функция MPI_CART_CREATE возвращает дескриптор нового коммуникатора, к которому подключается топологическая информация. Если reorder = false, то номер каждого процесса в новой группе идентичен номеру в старой группе. В противном случае функция может переупорядочивать процессы (возможно, чтобы обеспечить хорошее наложение виртуальной топологии на физическую систему). Если полная размерность декартовой решетки меньше, чем размер группы коммуникаторов, то некоторые процессы возвращаются с результатом MPI_COMM_NULL по аналогии с MPI_COMM_SPLIT. Вызов будет неверным, если он задает решетку большего размера, чем размер группы.
Объяснение: Во всем документе объяснение проектных выборов представлено в формате этого абзаца. Некоторые читатели могут пропустить эти разделы, в то время как другим читателям, интересующимся проектированием интерфейса, они будут необходимы.[]
Совет пользователям: Во всем документе материал, обращенный к пользователям, представлен в формате этого абзаца. Он может быть пропущен, но полезен для тех, кто интересуется программированием для MPI.[]
Совет разработчикам: Во всем документе этот материал, обращенный к разработчикам, представлен в формате этого абзаца. Полезен для разработчиков реализаций MPI.[]
В декартовой топологии функция MPI_DIMS_CREATE помогает пользователю выбрать выгодное распределение процессов по каждой координате в зависимости от числа процессов в группе и некоторых ограничений, определеных пользователем. Эта функция используется, чтобы распределить все процессы (размер группы MPI_COMM_WORLD) в n-мерную топологическую среду.
Синтаксис функции MPI_DIMS_CREATE представлен ниже.
MPI_DIMS_CREATE(nnodes, ndims, dims)
| IN | nnodes | количество узлов решетки (целое) | |
| IN | ndims | число размерностей декартовой решетки(целое) | |
| INOUT | dims | целочисленный массив размера ndims, указывающий количество вершин в каждой размерности. |
int MPI_Dims_create(int nnodes, int ndims, int *dims)
MPI_DIMS_CREATE(NNODES, NDIMS, DIMS, IERROR)
INTEGER NNODES, NDIMS, DIMS(*), IERROR
void MPI::Compute_dims(int nnodes, int ndims, int dims[])
Элементы массива dims описывают декартову решетку координат с числом размерностей ndims и общим количеством узлов nnodes. Количество узлов по размерностям нужно сделать насколько возможно близкими друг другу, используя соответствующий алгоритм делимости. Вызывающая подпрограмма может дальше ограничить выполнение этой функции, задавая количество элементов массива dims. Если размерность dims[i] есть положительное число, функция не будет изменять число узлов в направлении i; будут изменены только те элементы, для которых dims[i] = 0.
Отрицательные значения dims[i] неверны. Также будет неверно, если значение nnodes не кратно произведению dims[i].
Аргументdims[i], установленный вызывающей программой, будет упорядочен по убыванию. Массив dims удобен для использования в качестве входного для функции MPI_CART_CREATE. Функцией MPI_DIMS_CREATE является локальной.
Пример 6.1
| dims перед вызовом | вызов функции | dims после возврата управления |
| (0,0) | MPI_DIMS_CREATE(6, 2, dims) | (3,2) |
| (0,0) | MPI_DIMS_CREATE(7, 2, dims) | (7,1) |
| (0,3,0) | MPI_DIMS_CREATE(6, 3, dims) | (2,3,1) |
| (0,3,0) | MPI_DIMS_CREATE(7, 3, dims) | неверный вызов |
Синтаксис функции MPI_GRAPH_CREATE представлен ниже.
MPI_GRAPH_CREATE(comm_old, nnodes, index, edges, reorder, comm_graph)
| IN | comm_old | входной коммуникатор (дескриптор) | |
| IN | nnodes | количество узлов графа (целое) | |
| IN | index | массив целочисленных значений, описывающий степени вершин (смотри ниже) | |
| IN | edges | массив целочисленных значений, описывающий ребра графа (смотри ниже) | |
| IN | reorder | номера могут быть переупорядочены (true) или нет (false) | |
| OUT | comm_graph | построенный коммуникатор с графовой топологией (дескриптор) |
int MPI_Graph_create(MPI_Comm comm_old, int nnodes,
int *index, int *edges, int reorder, MPI_Comm *comm_graph)
MPI_GRAPH_CREATE(COMM_OLD, NNODES, INDEX,
EDGES, REORDER, COMM_GRAPH, IERROR)
INTEGER COMM_OLD, NNODES, INDEX(*), EDGES(*), COMM_GRAPH, IERROR
LOGICAL REORDER
Graphcomm Intracomm::Create_graph(int nnodes,
const int index[], const int edges[], bool reorder) const
Функция MPI_GRAPH_CREATE передает дескриптор новому коммуникатору, к которому присоединяется информация о графовой топологии. Если reorder = false, то номер каждого процесса в новой группе идентичен его номеру в старой группе. В противном случае функция может переупорядочивать процессы. Если размер декартовой решетки nnodes меньше, чем размер группы коммуникатора, то некоторые процессы возвращаются значение MPI_COMM_NULL, по аналогии с MPI_CART_SPLIT и MPI_COMM_SPLIT. Вызов будет неверным, если он определяет граф большего размера, чем размер группы исходного коммуникатора.
Структуру графа определяют три параметра nnodes, index и edges. nnodes - число узлов графа, узлы маркируются от 0 до nnodes-1. i-ый элемент массива index хранит общее число соседей первых i вершин графа. Списки соседей вершин 0, 1, ..., nnodes-1 хранятся в последовательности ячеек массива edges. Общее число элементов в index есть nnodes, а общее число элементов в edges равно числу ребер графа.
Определения аргументов nnodes, index, и edges иллюстрируются следующим простым примером.
Пример 6.2. Пусть имеются четыре процесса 0, 1, 2, 3 со следующей матрицей смежности:
| process | neighbors |
| 0 | 1, 3 |
| 1 | 0 |
| 2 | 3 |
| 3 | 0, 2 |
Тогда исходными аргументами являются:
| nnodes = |
4 |
| index = |
2, 3, 4, 6 |
| еdges = |
1, 3, 0, 3, 0, 2 |
Таким образом в языке Си index[0] есть степень вершины
нуль, а index [i] - index[i-1] есть степень вершины
i, i = 1, ..., nnodes-1; список соседей узла нуль хранится
в edges[j], где
![]() , a
список соседей верщины i, i > 0 хранится в edges[j], где
index[i-1]
, a
список соседей верщины i, i > 0 хранится в edges[j], где
index[i-1]
![]() .
.
В языке ФОРТРАН index (1) есть степень вершины нуль, а index (i+1) - index(i) есть степень вершины i, i = 1, ..., nnodes-1;
список соседей вершины нуль хранится в edges(j), где 1 ![]() j
j ![]() index(1), а список
соседей вершины i, i> 0 хранится в edges(j), где index(i) + 1
index(1), а список
соседей вершины i, i> 0 хранится в edges(j), где index(i) + 1 ![]() j
j ![]() index(i +1).
index(i +1).
Совет разработчикам: С коммуникатором в общем случае должна храниться следующая топологическая информация:
Для графовой структуры число вершин равно числу процессов в группе. Следовательно, число вершин не обязательно хранить явно. Дополнительный нулевой элемент в начале массива index упрощает доступ к топологической информации.[]
Если топология была определена одной из вышеупомянутых функций, то информация об этой топологии может быть получена с помощью функций запроса. Все они являются локальными вызовами.
Синтаксис функции MPI_TOPO_TEST представлен ниже.
MPI_TOPO_TEST(comm, status)
| IN | comm | коммуникатор (дескриптор) | |
| OUT | status | тип топологии коммуникатора comm (альтернатива) |
int MPI_Topo_test(MPI_Comm comm, int *status)
MPI_TOPO_TEST(COMM, STATUS, IERROR)
INTEGER COMM, STATUS, IERROR
int MPI::Comm::Get_topology() const
Функция MPI_TOPO_TEST возвращает тип топологии, переданной коммуникатору. Выходное значение status имеет одно из следующих значений:
| MPI_GRAPH | топология графа |
| MPI_CART | декартова топология |
| MPI_UNDEFINED | топология не определена |
Синтаксис функции MPI_GRAPHDIMS_GET представлен ниже.
MPI_GRAPHDIMS_GET(comm, nnodes, nedges)
| IN | comm | коммуникатор группы с графовой топологией (дескриптор) | |
| OUT | nnodes | число вершин графа (целое, равно числу процессов в группе) | |
| OUT | nedges | число ребер графа (целое) |
int MPI_Graphdims_get(MPI_Comm comm, int *nnodes, int *nedges)
MPI_GRAPHDIMS_GET(COMM, NNODES, NEDGES, IERROR)
INTEGER COMM, NNODES, NEDGES, IERROR
void MPI::Graphcomm::Get_dims(int nnodes[],
int nedges[]) const
Функции MPI_GRAPHDIMS_GET и MPI_GRAPH_GET отыскивают графо-топологическую информацию, которая была связана с коммуникатором с помощью функции MPI_GRAPH_CREATE.
Информация, предоставляемая MPI_GRAPHDIMS_GET, может быть использована для корректного определения размера векторов index и edges для последующего вызова функции MPI_GRAPH_GET.
Синтаксис функции MPI_GRAPH_GET представлен ниже.
MPI_GRAPH_GET(comm, maxindex, maxedges, index, edges)
| IN | comm | коммуникатор с графовой топологией (дескриптор) | |
| IN | maxindex | длина вектора index (целое) | |
| IN | maxedges | длина вектора edges (целое) | |
| OUT | index | целочисленный массив, содержащий структуру графа (подробнее в описании функции MPI_GRAPH_CREATE) | |
| OUT | edges | целочисленный массив,содержащий структуру графа |
int MPI_Graph_get(MPI_Comm comm, int maxindex,
int maxedges, int *index, int *edges)
MPI_GRAPH_GET(COMM, MAXINDEX, MAXEDGES, INDEX, EDGES, IERROR)
INTEGER COMM, MAXINDEX, MAXEDGES, INDEX(*), EDGES(*), IERROR
void MPI::Graphcomm::Get_topo(int maxindex,
int maxedges, int index[], int edges[]) const
Синтаксис функции MPI_CARTDIM_GET представлен ниже.
MPI_CARTDIM_GET(comm, ndims)
| IN | comm | коммуникатор с декартовой топологией (дескриптор) | |
| OUT | ndims | число размерностей в декартовой топологии системы (целое) |
int MPI_Cartdim_get(MPI_Comm comm, int *ndims)
MPI_CARTDIM_GET(COMM, NDIMS, IERROR)
INTEGER COMM, NDIMS, IERROR
int MPI::Cartcomm::Get_dim() const
Функции MPI_CARTDIM_GET и MPI_CART_GET возвращают информацию о декартовой топологии, которая была связана с функцией MPI_CART_CREATE.
Синтаксис функции MPI_CART_GET представлен ниже.
MPI_CART_GET(comm, maxdims, dims, periods, coords)
| IN | comm | коммуникатор с декартовой топологией (дескриптор) | |
| IN | maxdims | длина векторов dims, periods и coords (целое) | |
| OUT | dims | число процессов по каждой декартовой размерности (целочисленный
массив) |
|
| OUT | periods | периодичность (true / false) для каждой декартовой размерности (массив логических элементов) | |
| OUT | coords | координаты вызываемых процессов в декартовой системе координат (целочисленный массив) |
int MPI_Cart_get(MPI_Comm comm, int maxdims,
int *dims, int *periods, int *coords)
MPI_CART_GET(COMM, MAXDIMS, DIMS, PERIODS, COORDS, IERROR)
INTEGER COMM, MAXDIMS, DIMS(*), COORDS(*), IERROR
LOGICAL PERIODS(*)
void MPI::Cartcomm::Get_topo(int maxdims, int dims[],
bool periods[], int coords[]) const
Синтаксис функции MPI_CART_RANK представлен ниже.
MPI_CART_RANK(comm, coords, rank)
| IN | comm | коммуникатор с декартовой топологией (дескриптор) | |
| IN | coords | целочисленный массив (размера ndims), описывающий декартовы координаты процесса | |
| OUT | rank | номер указанного процесса (целый) |
int MPI_Cart_rank(MPI_Comm comm, int *coords, int *rank)
MPI_CART_RANK(COMM, COORDS, RANK, IERROR)
INTEGER COMM, COORDS(*), RANK, IERROR
int MPI::Cartcomm::Get_cart_rank(const int coords[]) const.
Для группы процессов с декартовой структурой, функция MPI_CART_RANK переводит логические координаты процессов в номера, которые используются в процедурах парного обмена.
Для размерности i с periods(i) = true, если координата cords(i) выходит за границу диапазона, то есть когда coords(i) < 0
или coords(i) ![]() dims(i), то она
автоматически сдвигается назад к интервалу 0
dims(i), то она
автоматически сдвигается назад к интервалу 0 ![]() coords(i) < dims(i). Выход координат за пределы диапазона
неверен для непериодических размерностей.
coords(i) < dims(i). Выход координат за пределы диапазона
неверен для непериодических размерностей.
Синтаксис функции MPI_CART_COORDS представлен ниже.
MPI_CART_COORDS(comm, rank, maxdims, coords)
| IN | comm | коммуникатор с декартовой топологией (дескриптор) | |
| IN | rank | номер процесса внутри группы comm (целое) | |
| IN | maxdims | длина вектора coord (целое) | |
| OUT | coords | целочисленный массив (размера ndims), содержащий декартовы координаты указанного процесса (целое) |
int MPI_Cart_coords(MPI_Comm comm, int rank, int maxdims, int *coords)
MPI_CART_COORDS(COMM, RANK, MAXDIMS, COORDS, IERROR)
INTEGER COMM, RANK, MAXDIMS, COORDS(*), IERROR
void MPI::Cartcomm_Get_coords(int rank,
int maxdims, int coords[]) const
Функция MPI_CART_COORDS используется для перевода номера в координату.
Синтаксис функции MPI_GRAPH_NEIGHBORS_COUNT представлен ниже.
MPI_GRAPH_NEIGHBORS_COUNT(comm, rank, nneighbors)
| IN | comm | коммуникатор с графовой топологией (дескриптор) | |
| IN | rank | номер процесса в группе comm (целое) | |
| OUT | nneighbors | номера процессов, являющихся соседними указанному процессу (целочисленный массив) |
int MPI_Graph_neighbors_count(MPI_Comm comm,
int rank, int *nneighbors)
MPI_GRAPH_NEIGHBORS_COUNT(COMM, RANK, NNEIGHBORS, IERROR)
INTEGER COMM, RANK, NNEIGHBORS, IERROR
int MPI::Graphcomm::Get_neighbors_count(int rank) const
Функции MPI_GRAPH_NEIGHBORS_COUNT и MPI_GRAPH_NEIGHBORS предоставляют похожую информацию для графической топологии.
Синтаксис функции MPI_GRAPH_NEIGHBORS представлен ниже.
MPI_GRAPH_NEIGHBORS(comm, rank, maxneighbors, neighbors)
| IN | comm | коммуникатор с графовой топологией (дескриптор) | |
| IN | rank | номер процесса в группе comm (целое) | |
| IN | maxneighbors | размер массива neighbors (целое) | |
| OUT | neighbors | номера процессов, соседних данному (целочисленный массив) |
int MPI_Graph_neighbors(MPI_Comm comm,
int rank, int maxneighbors, int *neighbors)
MPI_GRAPH_NEIGHBORS(COMM, RANK, MAXNEIGHBORS, NEIGHBORS, IERROR)
INTEGER COMM, RANK, MAXNEIGHBORS, NEIGHBORS(*), IERROR
void MPI::Graphcomm::Get_neighbors(int rank,
int maxneighbors, int neighbors[]) const
Пример 6.3 Предположим, что comm является коммуникатором с топологией типа
``тасовка''. Пусть группа содержит ![]() процессов. Каждый процесс задан
двоичным n - разрядным кодом
процессов. Каждый процесс задан
двоичным n - разрядным кодом
![]() , где
, где
![]() и имеет трех соседей:
exchange
и имеет трех соседей:
exchange
![]() ;
shuffle
;
shuffle
![]() и unshuffle
и unshuffle
![]() .
Таблица связей каждого процесса с соседями представлена ниже для n=3.
.
Таблица связей каждого процесса с соседями представлена ниже для n=3.
| node | exchange
neighbors(1) |
shuffle
neighbors(2) |
unshuffle
neighbors(3) |
| 0 (000) | 1 | 0 | 0 |
| 1 (001) | 0 | 2 | 4 |
| 2 (010) | 3 | 4 | 1 |
| 3 (011) | 2 | 6 | 5 |
| 4 (100) | 5 | 1 | 2 |
| 5 (101) | 4 | 3 | 6 |
| 6 (110) | 7 | 5 | 3 |
| 7 (111) | 6 | 7 | 7 |
Предположим, что коммуникатор comm имеет эту топологию. Представленный ниже фрагмент программы в цикле обходит трех соседей и делает соответствующую перестановку для каждого соседа.
C пусть каждый процесс хранит действительное число А
C получение информации о соседях
CALL MPI_COMM_RANK(comm, myrank, ierr)
CALL MPI_GRAPH_NEIGHBORS(comm, myrank, 3, neighbors, ierr)
C выполнение перестановки для exchange
CALL MPI_SENDRECV_REPLACE(A, 1, MPI_REAL, neighbors(1), 0,
+ neighbors(1), 0, comm, status, ierr)
C выполнение перестановки для shuffle
CALL MPI_SENDRECV_REPLACE(A, 1, MPI_REAL, neighbors(2), 0,
+ neighbors(3), 0, comm, status, ierr)
C выполнение перестановки для unshuffle
CALL MPI_SENDRECV_REPLACE(A, 1, MPI_REAL, neighbors(3), 0,
+ neighbors(2), 0, comm, status, ierr)
Если используется декартова топология, то операцию MPI_SENDRECV можно выполнить путем сдвига данных вдоль направления координаты. В качестве входного параметра MPI_SENDRECV использует номер процесса-отправителя для приема и номер процесса-получателя - для передачи. Если функция MPI_CART_SHIFT выполняется для декартовой группы процессов, то она передает вызывающему процессу эти номера, которые затем могут быть использованы для MPI_SENDRECV. Пользователь определяет направление координаты и величину шага (положительный или отрицательный). Эта функция является локальной.
Синтаксис функции MPI_CART_SHIFT представлен ниже.
MPI_CART_SHIFT(comm, direction, disp, rank_source, rank_dest)
| IN | comm | коммуникатор с декартовой топологией (дескриптор) | |
| IN | direction | координата сдвига (целое) | |
| IN | disp | направление смещения (> 0: смещение вверх, < 0: смещение вниз) (целое) | |
| OUT | rank_source | номер процесса-отправителя (целое) | |
| OUT | rank_dest | номер процесса-получателя (целое) |
int MPI_Cart_shift(MPI_Comm comm, int direction,
int disp, int *rank_source, int *rank_dest)
MPI_CART_SHIFT(COMM, DIRECTION, DISP,
RANK_SOURCE, RANK_DEST, IERROR)
INTEGER COMM, DIRECTION, DISP, RANK_SOURCE, RANK_DEST, IERROR
void MPI::Cartcomm::Shift(int direction, int disp,
int& rank_source, int& rank_dest) const
Аргумент direction указывает размерность, то есть координату, по которой сдвигаются данные. Координаты маркируются от 0 до ndims-1, где ndims - число размерностей.
В зависимости от периодичности декартовой группы в указанном направлении координаты, MPI_CART_SHIFT указывает признаки для кольцевого сдвига или для сдвига без переноса. В случае сдвига без переноса в rank_source или rank_dest может быть возвращено значение MPI_PROC_NULL для указания, что процесс-отправитель или процесс-получатель при сдвиге вышли из диапазона.
Пример 6.4 Коммуникатор comm имеет двумерную периодическую декартову топологию. Двумерная матрица элементов типа REAL хранит один элемент на процесс в переменной A. Нужно выполнить скошенное преобразование матрицы путем сдвига столбца i (вертикально, то есть вдоль столбца) i раз.
....
C определяется номер процесса
CALL MPI_COMM_RANK(comm, rank, ierr)
C опеределяются декартовы координаты
CALL MPI_CART_COORDS(comm, rank, maxdims, coords, ierr)
C вычисляются номера процесса-отправителя и процесса-получателя при сдвиге
CALL MPI_CART_SHIFT(comm, 0, coords(2), source, dest, ierr)
C "скошенный" массив
CALL MPI_SENDRECV_REPLACE(A, 1, MPI_REAL, dest, 0, source, 0,
comm, status, ierr)
Совет пользователям: В языке ФОРТРАН размерность, обозначенная как DIRECTION = i, имеет DIMS (i + 1) узлов, где DIMS - массив, который был использован для создания решетки. В языке Си размерность, обозначенная DIRECTION =i есть размерность, указаная DIMS [i].[]
Синтаксис функции MPI_CART_SUB представлен ниже.
MPI_CART_SUB(comm, remain_dims, newcomm)
| IN | comm | коммуникатор с декартовой топологией (дескриптор) | |
| IN | remain_dims | i-ый элемент в remain_dims показывает, содержится ли i-ая размерность в подрешетке (true) или нет (false) (вектор логических элементов) | |
| OUT | newcomm | коммуникатор, содержащий подрешетку, которая включает вызываемый процесс (дескриптор) |
int MPI_Cart_sub(MPI_Comm comm,
int *remain_dims, MPI_Comm *newcomm)
MPI_CART_SUB(COMM, REMAIN_DIMS, NEWCOMM, IERROR)
INTEGER COMM, NEWCOMM, IERROR
LOGICAL REMAIN_DIMS(*)
MPI::Cartcomm MPI::Cartcomm::Sub(const bool remain_dims[]) const
Если декартова топология была создана с помощью MPI_CART_CREATE, то функция MPI_CART_SUB может использоваться для декомпозиции группы в подгруппы, которые являются декартовыми подрешетками, и для построения для каждой подгруппы коммуникаторов с подрешеткой с декартовой топологией. (Эта функция близка к MPI_COMM_SPLIT).
Пример 6.5 Допустим, что функция MPI_CART_CREATE(...,
comm) создала решетку размером (2 ![]() 3
3 ![]() 4). Пусть remain_dims = (true, false, true). Тогда обращение к
4). Пусть remain_dims = (true, false, true). Тогда обращение к
MPI_CART_SUB (comm, remain_dims, comm_new),
создаст три коммуникатора, каждый с восьмью процессами размерности 2![]() 4 в декартовой топологии. Если remain_dims = (false, false, true),
то обращение к MPI_CART_SUB (comm,
4 в декартовой топологии. Если remain_dims = (false, false, true),
то обращение к MPI_CART_SUB (comm,
remain_dims,
comm_new) создает шесть непересекающихся коммуникаторов, каждый с
четырьмя процессами в одномерной декартовой топологии.
Для выполнения всех других функций топологии могут использоваться две дополнительные функции, представленные в этом разделе. В общем случае они не вызываются пользователем, пока ему хватает обычных возможностей MPI.
Синтаксис функции MPI_CART_MAP представлен ниже.
MPI_CART_MAP(comm, ndims, dims, periods, newrank)
| IN | comm | исходный коммуникатор (дескриптор) | |
| IN | ndims | размерность декартовой структуры (целое) | |
| IN | dims | целочисленный массив размером ndims , обозначающий количество процессов в каждом измерении декартовой топологии. | |
| IN | periods | массив логических элементов размера ndims, обозначающих периодичность по каждому измерению | |
| OUT | newrank | переупорядоченный номер вызывающего процесса; MPI_UNDEFINED, если вызывающий процесс не принадлежит решетке (целое) |
int MPI_Cart_map(MPI_Comm comm, int ndims,
int *dims, int *periods, int *newrank)
MPI_CART_MAP(COMM, NDIMS, DIMS, PERIODS, NEWRANK, IERROR)
INTEGER COMM, NDIMS, DIMS(*), NEWRANK, IERROR
LOGICAL PERIODS(*)
int MPI::Cartcomm::Map(int ndims, const int dims[], const bool periods[]) const
Функция MPI_CART_MAP вычисляет ``оптимальное'' размещение вызывающего процесса на физической машине. Возможная реализация этой функции состоит в том, чтобы всегда возвращать номер вызывающего процесса, то есть, чтобы не выполнять переупорядочивание.
Совет разработчикам: Функция MPI_CART_CREATE(
comm, ndims, dims, periods,reorder, comm_cart) с reorder =
true может быть реализована обращением к MPI_CART_MAP(
comm, ndims, dims, периоды, newrank) с последующим вызовом MPI_COMM_SPLIT(comm, color, key,
comm_cart), с color =
0, если newrank ![]() MPI_UNDEFINED, и color =
MPI_UNDEFINED в противном случае, и key = newrank. Все другие
декартовы функции топологии могут быть реализованы локально, используя
топологическую информацию, кэшируемую с коммуникатором.[]
MPI_UNDEFINED, и color =
MPI_UNDEFINED в противном случае, и key = newrank. Все другие
декартовы функции топологии могут быть реализованы локально, используя
топологическую информацию, кэшируемую с коммуникатором.[]
Новая функция MPI_GRAPH_MAP для графовых структур представлена ниже:
MPI_GRAPH_MAP(comm, nnodes, index, edges, newrank)
| IN | comm | исходный коммуникатор (дескриптор) | |
| IN | nnodes | количество вершин графа (целое) | |
| IN | index | целочисленный массив,описывающий структуру графа, смотри MPI_GRAPH_CREATE | |
| IN | edges | целочисленный массив, описывающий структуру графа | |
| OUT | newrank | переупорядоченный номер вызывающего процесса; MPI_UNDEFINED, если процесс не принадлежит графу (целое) |
int MPI_Graph_map(MPI_Comm comm, int nnodes,
int *index, int *edges, int *newrank)
MPI_GRAPH_MAP(COMM, NNODES, INDEX, EDGES, NEWRANK, IERROR)
INTEGER COMM, NNODES, INDEX(*), EDGES(*), NEWRANK, IERROR
int MPI::Graphcomm::Map(int nnodes, const int index[],
const int edges[]) const
Совет разработчикам: Функция MPI_CART_CREATE(
comm, ndims, dims, periods, reorder,
comm_cart) с reorder =
true может быть реализована обращением к MPI_CART_MAP(comm, ndims, dims, периоды, newrank) с последующим вызовом MPI_COMM_SPLIT(comm, color, key,
comm_cart), с color =
0, если newrank = MPI_UNDEFINED, и color =
MPI_UNDEFINED в противном случае, и key = newrank.[]
Пример 6.6 Этот пример показывает, как могут использоваться в прикладной программе функции формирования решетки и функции запроса. Дифференциальные уравнения в частных производных, например, уравнение Пуассона, могут быть решены на прямоугольной решетке. Сначала процессы располагаются в двумерной структуре. Каждый процесс затем запрашивает номера соседей в четырех направлениях (вверх, вниз, вправо, влево). Числовая задача решается итерационным методом, детали которого скрыты в подпрограмме.
На каждой итерации каждый процесс вычисляет новые значения для функции в области решетки, за которую он ответственен. Затем процесс на своих границах должен обменяться значениями функции с соседними процессами. Например, подпрограмма обмена может содержать вызов функции MPI_SEND(..., neigh_rank (1), ...) , чтобы затем послать модифицированные значения функции левому соседу (i-1, j).
Integer ndims, num_neihg
Logical reorder
Parameter (ndims=2,num_neigh=4,reorder=.true.)
Integer comm, comm_cart, dims (ndims), neigh_def (ndims), ierr
Integer neigh_rank (num_neigh), own_position (ndims), i,j
Logical periods (ndims)
Real*8 u(0:101,0:101), f(0:101,0:101)
Data dims /ndims*0/
Comm = MPI_COMM_WORLD
C устанавливает размер решетки и периодичность
Call MPI_DIMS_CREATE (comm, ndims, dims, ierr)
Periods (1) = .TRUE.
Periods (2) = .TRUE.
C создает структуру решетки в группе WORLD
C и запрашивает собственную позицию
Call MPI_CART_CREATE (comm, ndims, dims,
periods, reorder, comm_cart, ierr)
Call MPI_CART_GET (comm_cart, ndims, dims, periods, own_position, ierr)
C просматривает номера соседей. Собственные координаты есть
C (i,j). Соседями являются процессы с номерами
C (i-1,j), (i+1,j), (i,j-1), (i,j+1)
I = own_position(1)
J = own_position(2)
Neigh_def(1)= i-1
Neigh_def(2)= j
Call MPI_CART_RANK (comm_cart, neigh_def, neigh_rank(1), ierr)
Neigh_def(1)= i+1
Neigh_def(2)= j
Call MPI_CART_RANK (comm_cart, neigh_def, neigh_rank(2), ierr)
Neigh_def(1)= i
Neigh_def(2)= j-1
Call MPI_CART_RANK (comm_cart, neigh_def, neigh_rank(3), ierr)
Neigh_def(1)= i
Neigh_def(2)= j+1
Call MPI_CART_RANK (comm_cart, neigh_def, neigh_rank(4), ierr)
C инициализация функций решеток и начало итерации
Call init (u,f)
Do 10 it=1,100
Call relax (u,f)
C обмен данными с соседними процессами
сall exchange (u, comm_cart, neigh_rank, num_neigh)
10 continue
call output (u)
end
В этой главе описываются процедуры для получения и установки различных параметров, связанных с реализацией MPI и исполнительной средой. Здесь также описаны процедуры для входа и выхода из исполнительной среды MPI.
Набор атрибутов, которые описывают исполнительную среду, подключается к коммуникатору MPI_COMM_WORLD во время инициализации MPI. Значение этих атрибутов можно узнать, используя функцию MPI_ATTR_GET, описанную в главе 5. Удаление этих атрибутов, освобождение их ключей или изменение их значений является ошибкой.
Список предопределенных ключей атрибутов включает:
Поставщики реальных систем могут добавлять определенные параметры (такие, как номер узла, реальный размер памяти, размер виртуальной памяти, и т.д.).
Эти предопределенные атрибуты не изменяют свое значение между MPI инициализацией (MPI_INIT) и MPI завершением (MPI_FINALIZE) и не могут быть модифицированы или удалены пользователями.
Совет пользователям: Заметим, что в языке Си значение, возвращаемое этими атрибутами, является указателем на int, содержащем запрошенную величину.[]
Запрашиваемые значения параметров более детально обсуждаются ниже:
Значения тэга. Величина тэга изменяется в диапазоне от 0 до
величины, возвращенной MPI_TAG_UB включительно. Эти значения не
должны изменяться в течение выполнения программы MPI. Кроме того,
верхнее значение границы тэга должно быть по крайней мере 32767.
Реализация
MPI вправе делать величину MPI_TAG_UB больше, чем это
значение;
например, значение ![]() - также разрешенное значение для MPI_TAG_UB.
- также разрешенное значение для MPI_TAG_UB.
Атрибут MPI_TAG_UB имеет одно и то же значение на всех процессах MPI_COMM_WORLD.
Номер хост процесса. Значение, возвращенное MPI_HOST, дает номер хост-процесса в группе, связанной с коммуникатором MPI_COMM_WORLD, если такой имеется. Если хост-процесса нет, возвращается MPI_PROC_NULL. MPI не определяет, что значит хост-процесс, и не требует, чтобы хост-процесс существовал.
Атрибут MPI_HOST имеет одно и то же значение во всех процессах MPI_COMM_WORLD.
Номер процесса ввода/вывода. Значение, возвращенное MPI_IO, есть номер процесса, который может обеспечивать стандартные для некоторого языка операторы ввода/вывода. Для языка ФОРТРАН это означает, что поддерживаются все операции ввода/вывода (например,OPEN, REWIND, WRITE). Для языка Си это означает, что поддерживаются все ANSI-коды операторов ввода/вывода (например, open, fprintf, lseek).
Если каждый процесс может обеспечивать стандартный для языка ввод/вывод, то будет возвращено значение MPI_ANY_SOURCE. В противном случае, если этот вызывающий процесс может обеспечивать стандартный для языка ввод/вывод, то будет возвращен номер этого процесса. Другими словами, если некоторый процесс может обеспечивать стандартный для языка ввод/вывод, то будет возвращен номер одного такого процесса. Одно и то же значение не обязательно должно возвращаться всем процессам. Если ни один из процессов не может обеспечить стандартный для языка ввод/вывод, то будет возвращено значение MPI_PROC_NULL.
Совет пользователям: Заметим, что ввод данных не является коллективной операцией и этот атрибут не указывает, какой процесс может выполнять или выполняет ввод.[]
Синхронизация часов. Значение, возвращаемое MPI_WTIME_IS_GLOBAL равно 1, если часы для всех процессах в MPI_COMM_WORLD синхронизированы, в противном случае - 0. Совокупность часов рассматривается синхронизированной, если была явная попытка синхронизировать их. Погрешность измерения времени при обращении к MPI_WTIME должна быть меньше половины полного времени для MPI сообщения нулевой длины. Если время в процессе измеряется точно перед отправкой сообщения и в другом процессе точно после приема, то второе время должно быть всегда больше, чем первое. Атрибут MPI_WTIME_IS_GLOBAL может не присутствовать, когда часы не синхронизированы (однако, ключ атрибута MPI_WTIME_IS_GLOBAL всегда имеет силу). Этот атрибут может быть связан с коммуникатором, отличным от MPI_COMM_WORLD. Атрибут MPI_WTIME_IS_GLOBAL имеет то же самое значение во всех процессах MPI_COMM_WORLD.
Синтаксис функции MPI_GET_PROCESSOR_NAME представлен ниже.
MPI_GET_PROCESSOR_NAME(name, resultlen)
| OUT | name | уникальный описатель для фактического (в противоположность виртуальному) узла. | |
| OUT | resultlen | длина (в печатных знаках) результата, возвращаемого в name |
int MPI_Get_processor_name(char *name, int *resultlen)
MPI_GET_PROCESSOR_NAME(NAME, RESULTLEN, IERROR)
CHARACTER*(*) NAME
INTEGER RESULTLEN,IERROR
void MPI::Get_processor_name(char* name, int& resulten)
Эта процедура возвращает имя процессора, на котором был выполнен вызов. Для максимальной гибкости имя является символьной строкой. От этого значения обязательно требуется конкретное описание единицы оборудования, например: ``процессор 9 в стойке 4 из mpp.cs.org'' и ``231'' (где 231 - фактический номер процессора в текущей однородной системе).
Аргумент name должно иметь длину не менее MPI_MAX_PROCESSOR_NAME знаков.
MPI_GET_PROCESSOR_NAME может добавить к этому много символов в
name. Фактическое число символов возвращается в выходном параметре
resultlen.
Объяснение: Эта функция разрешает реализациям MPI процессов, допускающих миграцию процессов, возвратить имя текущего процессора. Заметим, что ничто в MPI не требует определения мигрирующих процессов; определение MPI_GET_PROCESSOR_NAME просто допускает такую реализацию.[]
Совет пользователям: Пользователь должен обеспечить место размером по крайней мере MPI_MAX_PROCESSOR_NAME для записи имени процессора. Пользователь должен проверить выходной параметр resultlen, чтобы определить фактическую длину имени.[]
Процедуры MPI описываются с помощью независимых от языка обозначений. Аргументы процедурных вызовов маркируются через IN, OUT или INOUT. Это означает, что:
Имеется один специальный случай: если аргумент является дескриптором скрытого объекта (этот термин определен в разделе 2.4.1) и объект модифицируется процедурой, тогда аргумент маркируется как OUT. Он маркируется таким образом, даже если сам дескриптор не модифицируется - здесь атрибут OUT используется, чтобы указать, что модифицирована дескрипторная ссылка.
Из-за повышенной возможности ошибок в MPI избегают использования аргумента INOUT для самых больших экстентов, особенно для скалярных аргументов.
Общим явлением для функций MPI является аргумент, который используется как IN некоторыми процессами и как OUT - другими процессами. Такой аргумент синтаксически является и маркируется как INOUT аргумент, хотя семантически он не используется ни в одном вызове одновременно как входной и выходной.
Часто возникает другая ситуация, когда значение аргумента необходимо только части процессов. Когда аргумент не является существенным для процесса, тогда в качестве аргумента может быть передано произвольное значение.
Аргументы типа OUT или типа INOUT не могут заменяться любым другим аргументом, посланным в MPI процедуру. Пример переименования в языке Си приводится ниже. Если мы определяем процедуру в языке Си таким образом:
void copyIntBuffer(int *pin, int *pout, int len)
{
int i;
for (i=0; i<len; ++i) *pout++ = *pin++;
}
тогда для обращения к ней в следующем фрагменте кода используются аргументы с другими именами.
int a[10]; copyIntBuffer(a, a+3, 7);
Хотя язык Си позволяет это, такое использование процедур в MPI запрещено, если они не описаны другим образом. Заметим, что язык ФОРТРАН запрещает такое переименование.
Все MPI функции сначала описываются в языково - независимой нотации. Затем ниже идет версия функции для ANSI Си, и еще ниже - версия той же функции для языков ФОРТРАН77 и С++.
Реализация MPI может обрабатывать или не обрабатывать некоторые ошибки, которые возникают при выполнении вызовов MPI. Это могут быть ошибки, которые генерируют исключения или прерывания, например, ошибки для операций с плавающей точкой или при нарушении доступа. Набор ошибок, которые корректно обрабатываются MPI, зависит от реализации. Каждая такая ошибка генерирует исключение MPI.
Вышеупомянутый текст имеет приоритет над любым текстом по обработке ошибок внутри этого документа. Текст, в котором говорится, что ошибки будут обработаны, должен содержать информацию о том, как они могут быть обработаны.
Пользователь может связывать обработчик ошибок с коммуникатором. Эта процедура будет использоваться для любого исключения MPI, которое имеет место в течение вызова MPI для обмена с использованием этого коммуникатора. Вызовы MPI, которые не связаны ни с одним коммуникатором, рассматриваются, как относящиеся к коммуникатору MPI_COMM_WORLD.
Привязка обработчиков ошибок к коммуникатору исключительно локальная: различные процессы могут присоединить различные обработчики ошибок к тому же самому коммуникатору.
Вновь созданный коммуникатор наследует обработчик ошибок, который связан с ``родительским'' коммуникатором. В частности, пользователь может определить ``глобальный'' обработчик ошибок для всех коммуникаторов, связывая этот обработчик с коммуникатором MPI_COMM_WORLD сразу после инициализации.
В MPI доступны несколько предопределенных обработчиков ошибок :
Реализации могут обеспечивать дополнительные обработчики ошибок, программисты также могут написать свои собственные обработчики ошибок.
Обработчик ошибок MPI_ERRORS_ARE_FATAL связан по умолчанию с MPI_COMM_WORLD после его инициализации. Таким образом, если пользователь не желает управлять обработкой ошибок самостоятельно, то каждая ошибка в MPI обрабатывается как фатальная. Так как все вызовы MPI возвращают код ошибки, пользователь может работать с ошибками в головной программе, используя возвращенные вызовами MPI коды и выполняя подходящую программу восстановления в том случае, когда вызов не был успешным. В этом случае будет использоваться обработчик ошибок MPI_ERRORS_RETURN. Обычно более удобно и более эффективно не проверять ошибки после каждого вызова, а иметь специализированный обработчик ошибок.
После того, как ошибка обнаружена, состояние MPI является
неопределенным. Это означает, что даже если используется определенный
пользователем обработчик ошибок или
MPI_ERRORS_RETURN,
не обязательно, что пользователю будет разрешено продолжить использовать
MPI после того, как ошибка определена. Цель таких обработчиков состоит в
том, чтобы пользователь получил определенное им сообщение об ошибке и предпринял
действия, не относящиеся к MPI (такие, как очистки буферов
ввода/вывода) перед выходом из программы. Реализация MPI допускает
продолжение работы приложения после возникновения ошибки, но не требует,
чтобы так было всегда.
Совет разработчикам: Хорошие реализации MPI должны максимально ограничивать воздействие ошибки, чтобы нормальное функционирование могло продолжаться после того, как обработчик ошибок был запущен. В документации должна содержаться информация относительно возможного эффекта по каждому классу ошибок.[]
Обработчик ошибок MPI является скрытым объектом, связанным с дескриптором. Процедуры MPI обеспечивают создание новых обработчиков ошибок, связывают обработчики ошибок с коммуникаторами и проверяют, какой обработчик ошибок связан с коммуникатором.
Синтаксис функции MPI_ERRHANDLER_CREATE представлен ниже.
MPI_ERRHANDLER_CREATE(function, errhandler)
| IN | function | установленная пользователем процедура обработки ошибок | |
| OUT | errhandler | MPI обработчик ошибок (дескриптор) |
int MPI_Errhandler_create(MPI_Handler_function *function,
MPI_Errhandler *errhandler)
MPI_ERRHANDLER_CREATE(FUNCTION, ERRHANDLER, IERROR)
EXTERNAL FUNCTION
INTEGER ERRHANDLER, IERROR
Функция MPI_ERRHANDLER_CREATE регистрирует процедуру пользователя в качестве обработчика MPI исключений. Возвращает в errhandler дескриптор зарегистрированного обработчика исключений.
В языке Си процедура пользователя должна быть функцией типа MPI_Handler_function, которая определяется как:
typedef void (MPI_Handler_function)(MPI_Comm *, int *, ...);
Первый аргумент является идентификатором используемого коммуникатора, второй является кодом ошибки, который будет возвращен процедурой MPI, которая выявила ошибку. Если процедура возвратила MPI_ERR_IN_STATUS, то это значит, что код ошибки возвращен в статусный объект обращения, которое запустило обработчик ошибок. Остающиеся аргументы есть аргументы ``stdargs'', номер и значение которых являются зависимыми от реализации. В реализации должны быть ясно документированы эти аргументы. Адреса используются так, чтобы обработчик мог быть написан на языке ФОРТРАН.
Синтаксис функции MPI_ERRHANDLER_SET представлен ниже.
MPI_ERRHANDLER_SET(comm, errhandler)
| IN | comm | коммуникатор , на котором устанавливается обработчик ошибок (дескриптор) | |
| IN | errhandler | новый обработчик ошибок для коммуникатора (дескриптор) |
int MPI_Errhandler_set(MPI_Comm comm, MPI_Errhandler errhandler)
MPI_ERRHANDLER_SET(COMM, ERRHANDLER, IERROR)
INTEGER COMM, ERRHANDLER, IERROR
Функция MPI_ERRHANDLER_SET связывает новый обработчик ошибок errorhandler с коммуникатором comm на вызывающем процессе. Заметим, что обработчик ошибок всегда связан с коммуникатором.
Синтаксис функции MPI_ERRHANDLER_GET представлен ниже.
MPI_ERRHANDLER_GET(comm, errhandler)
| IN | comm | коммуникатор, из которого получен обработчик ошибок (дескриптор) | |
| OUT | errhandler | MPI обработчик ошибок, связанный с коммуникатором (дескриптор) |
int MPI_Errhandler_get(MPI_Comm comm, MPI_Errhandler *errhandler)
MPI_ERRHANDLER_GET(COMM, ERRHANDLER, IERROR)
INTEGER COMM, ERRHANDLER, IERROR
Функция MPI_ERRHANDLER_GET возвращает в errhandler дескриптор обработчика ошибок, связанного с коммуникатором comm. Пример: библиотечная функция может записать на входной точке текущий обработчик ошибок для коммуникатора, затем установить собственный частный обработчик ошибок для этого коммуникатора и восстановить перед выходом предыдущий обработчик ошибок.
Синтаксис функции MPI_ERRHANDLER_FREE представлен ниже.
MPI_ERRHANDLER_FREE(errhandler)
| INOUT | errhandler | MPI обработчик ошибок (дескриптор) |
int MPI_Errhandler_free(MPI_Errhandler *errhandler)
MPI_ERRHANDLER_FREE(ERRHANDLER, IERROR)
INTEGER ERRHANDLER, IERROR
void MPI::Errhandler::Free()
Эта функция маркирует обработчик ошибок, связанный с errhandler для удаления и устанавливает для errhandler значение MPI_ERRHANDLER_NULL. Обработчик ошибок будет удален после того, как все коммуникаторы, связанные с ним, будут удалены.
Синтаксис функции MPI_ERROR_STRING представлен ниже.
MPI_ERROR_STRING(errorcode, string, resultlen)
| IN | errorcodeк | код ошибки, возвращаемый процедурой MPI | |
| OUT | string | текст, соответствующий errorcode | |
| OUT | resultlen | длина (в печатных знаках) результата, возвращаемого в string |
int MPI_Error_string(int errorcode, char *string, int *resultlen)
MPI_ERROR_STRING(ERRORCODE, STRING, RESULTLEN, IERROR)
INTEGER ERRORCODE, RESULTLEN, IERROR
CHARACTER*(*) STRING
void MPI::Get_error_string(int errorcode, char* name, int& resulten)
Функция MPI_ERROR_STRING возвращает текст ошибки, связанный с кодом или классом ошибки. Аргумент string обязан иметь длину не менее _MAX_ERROR_STRING знаков. Число фактически записанных символов возвращается в выходном аргументе resultlen.
Объяснение: Форма этой функции была выбрана такой для того, чтобы сделать привязки в языке ФОРТРАН и Си похожими. Версия, которая возвращает указатель на строку, создает две проблемы. Во первых, возвращенная строка должна быть статически распределена и различаться для каждого сообщения об ошибке (позволяя указателям, возвращенным успешными обращениями к MPI_ERROR_STRING, указать правильное сообщение). Во вторых, в языке ФОРТРАН функция, объявленная, как возвращающая CHARACTER*(*), может не ссылаться, например, на оператор PRINT.[]
Коды ошибок, возвращаемых MPI, полностью приведены в реализации MPI (за исключением MPI_SUCCESS). Это сделано для того, чтобы позволить реализации представить как можно больше информации об ошибках (для использования с MPI_ERROR_STRING).
Чтобы приложения могли интерпретировать код ошибки, процедура MPI_ERROR_CLASS преобразует код любой ошибки в один из кодов небольшого набора кодов стандартных ошибок, названный классом ошибок. Правильные классы ошибок удовлетворяют условию:
Классы ошибок являются подмножеством кодов ошибок: функция MPI может возвращать номер класса ошибки, а функция MPI_ERROR_STRING может использоваться, чтобы вычислить строку ошибки, связанную с классом ошибки.
Коды ошибок удовлетворяют выражению:
0 = const MPI_SUCCESS < constMPI_ERR_... ![]() MPI_ERR_LASTCODE.
MPI_ERR_LASTCODE.
Объяснение: Разница между MPI_ERR_UNKNOWN и MPI_ERR_OTHER состоит в том, что
MPI_ERROR_STRING
может возвращать полезную информацию о MPI_ERR_OTHER.
Заметим, что MPI_SUCCESS = 0 необходимо для соответствия языку Си; разделение классов ошибки и кодов ошибки допускает определение класса ошибки этим способом. Наличие известного LASTCODE - часто хороший контроль готовности к работе.[]
| MPI_SUCCESS | Ошибки нет |
| MPI_ERR_BUFFER | Неправильный указатель буфера |
| MPI_ERR_COUNT | Неверное количество аргумента |
| MPI_ERR_TYPE | Неправильный тип аргумента |
| MPI_ERR_TAG | Неправильный тэг аргумента |
| MPI_ERR_COMM | Неправильный коммуникатор |
| MPI_ERR_RANK | Неправильный номер |
| MPI_ERR_REQUEST | Неверный запрос (дескриптор) |
| MPI_ERR_ROOT | Неверный корневой идентификатор |
| MPI_ERR_GROUP | Неправильная группа |
| MPI_ERR_OP | Неправильная операция |
| MPI_ERR_TOPOLOGY | Неверная топология |
| MPI_ERR_DIMS | Неправильная размерность аргумента |
| MPI_ERR_ARG | Ошибка аргумента некоторого другого типа |
| MPI_ERR_UNKNOWN | Неизвестная ошибка |
| MPI_ERR_TRUNCATE | Неправильное округление |
| MPI_ERR_OTHER | Известная ошибка не из этого списка |
| MPI_ERR_INTERN | Внутренняя ошибка реализации MPI |
| MPI_ERR_IN_STATUS | Неправильный код статуса |
| MPI_ERR_PENDING | Зависший запрос |
| MPI_ERR_LASTCODE | Последний код в списке |
Синтаксис функции MPI_ERROR_CLASS представлен ниже.
MPI_ERROR_CLASS(errorcode, errorclass)
| IN | errorcode | код ошибки, возвращаемый процедурой MPI | |
| OUT | errorclass | класс ошибки, связанный с errorcode |
int MPI_Error_class(int errorcode, int *errorclass)
MPI_ERROR_CLASS(ERRORCODE, ERRORCLASS, IERROR)
INTEGER ERRORCODE, ERRORCLASS, IERROR
int MPI::Get_error_class(int errorcode)
Функция MPI_ERROR_CLASS отображает код каждой стандартной ошибки (класс ошибки) на себя.
В MPI-1 под различными именами имеются три функции для обработки ошибок.
Функция MPI_COMM_CREATE_ERRHANDLER замещает устаревшую функцию
MPI_ERRHANDLER_CREATE(function, errhandler).
Функция MPI_COMM_SET_ERRHANDLER замещает MPI_ERRHANDLER_SET(comm, errhandler).
Функция MPI_COMM_GET_ERRHANDLER замещает MPI_ERRHANDLER_GET(comm, errhandler).
Пользовательская процедура MPI_Comm_errhandler_fn замещает
MPI_Handler_function, а
MPI_COMM_ERRHANDLER_FN замещает HANDLER_FUNCTION.
Пользовательские процедуры языка Си (MPI_Handler_function) и ФОРТРАН (HANDLER_FUNCTION) также устарели.
В каждом случае старая функция имеет то же самое определение и те же привязки, как и соответствующая новая функция.
Объяснение: MPI-I подключает обработчики ошибок только к коммуникаторам. В MPI-2 были введены новые объекты (файлы и окна) и средства для подключения к ним обработчиков ошибок. Имена для новых функций согласованы с именами функций для других объектов и привязками для языка С++.[]
Синтаксис функции MPI_COMM_CREATE_ERRHANDLER представлен ниже.
MPI_COMM_CREATE_ERRHANDLER(function, errhandler)
| IN | function | процедура обработки ошибок, определенная пользователем (функция) | |
| OUT | errhandler | обработчик ошибок MPI (дескриптор) |
int
MPI_Comm_create_errhandler(MPI_Comm_errhandler_fn *function,
MPI_Errhandler *errhandler)
MPI_COMM_CREATE_ERRHANDLER(FUNCTION, ERRHANDLER, IERROR)
EXTERNAL FUNCTION
INTEGER ERRHANDLER, IERROR
static MPI::Errhandler MPI::Comm::Create_errhandler(
MPI::Comm::Errhandler_fn* function)
Функция MPI_COMM_CREATE_ERRHANDLER создает обработчик ошибок, который может подключаться к коммуникаторам. Эта функция идентична функции MPI_ERRHANDLER_CREATE, которая вышла из употребления.
Синтаксис функции MPI_COMM_SET_ERRHANDLER представлен ниже.
MPI_COMM_SET_ERRHANDLER(comm, errhandler)
| INOUT | comm | коммуникатор (дескриптор) | |
| IN | errhandler | новый обработчик ошибок для коммуникатора (дескриптор) |
int MPI_Comm_set_errhandler(MPI_Comm comm,
MPI_Errhandler errhandler)
MPI_COMM_SET_ERRHANDLER(COMM, ERRHANDLER, IERROR)
INTEGER COMM, ERRHANDLER, IERROR
void MPI::Comm::Set_errhandler(
const MPI::Errhandler& errhandler)
Функция MPI_COMM_SET_ERRHANDLER подключает новый обработчик ошибок к коммуникатору. Обработчик ошибок должен создаваться вызовом MPI_COMM_CREATE_ERRHANDLER, либо быть предопределенным обработчиком. Этот вызов идентичен вызову MPI_ERRHANDLER_SET, который уже не употребляется.
Синтаксис функции MPI_COMM_GET_ERRHANDLER представлен ниже.
MPI_COMM_GET_ERRHANDLER(comm, errhandler)
| IN | comm | коммуникатор (дескриптор) | |
| OUT | errhandler | обработчик ошибок, связанный в настоящее время с коммуника-тором (дескриптор) |
int MPI_Comm_get_errhandler(MPI_Comm comm,
MPI_Errhandler *errhandler)
MPI_COMM_GET_ERRHANDLER(COMM, ERRHANDLER, IERROR)
INTEGER COMM, ERRHANDLER, IERROR
MPI::Errhandler MPI::Comm::Get_errhandler() const
Функция MPI_COMM_GET_ERRHANDLER выбирает обработчик ошибок , связанный в настоящее время с коммуникатором. Этот вызов идентичен вызову MPI_ERRHANDLER_GET, который уже не применяется.
MPI определяет таймеры, поскольку таймер необходим для изучения характеристик параллельных программ, а существующие таймеры (в POSIX, в языке ФОРТРАН90) неудобны или не обеспечивают доступ к таймерам с высоким разрешением.
Синтаксис функции MPI_WTIME() представлен ниже.
MPI_WTIME() double MPI_Wtime(void) DOUBLE PRECISION MPI_WTIME()
Функция MPI_WTIME возвращает количество секунд, представляя полное время по отношению к некоторому моменту времени в прошлом. Этот момент в прошлом не изменяется на протяжении времени жизни процесса. Эта функция универсальна, поскольку она возвращает секунды, а не количество тактовых импульсов.
Функцию можно использовать следующим образом:
{
double starttime, endtime;
starttime = MPI_Wtime();
.... stuff to be timed ...
endtime = MPI_Wtime();
printf("That took %f seconds\n",endtime-starttime);
}
Измеренное время локально относительно узла, вызвавшего эту функцию. Разные узлы не обязательно возвращают одинаковое время.
Синтаксис функции MPI_WTICK() представлен ниже.
MPI_WTICK () double MPI_Wtick(void) DOUBLE PRECISION MPI_WTICK()
Функция MPI_WTICK возвращает величину разрешения MPI_WTIME
в секундах, то есть время в секундах между последовательными импульсами,
представленное с двойной точностью. Например, если часы выполнены как
аппаратный счетчик, который инкрементируется каждую миллисекунду, то
значение, возвращаемое MPI_WTICK, должна быть ![]() .
.
Одна из целей разработи MPI состоит в том, чтобы достигнуть переносимости исходного текста. Это означает, что программа, написанная с использованием MPI, не должна требовать никаких изменений исходного текста при перемещении ее от одной системы к другой.
Для реализации переносимости необходимо, чтобы перед запуском параллельной программы были сделаны некоторые установки, которые обеспечиваются несколькими функциями MPI. К ним прежде всего относится функция инициализации MPI_INIT.
Синтаксис функции MPI_INIT представлен ниже.
MPI_INIT() int MPI_Init(int *argc, char ***argv) MPI_INIT(IERROR) NTEGER IERROR void Init(int& argc, char**& argv) void Init()
Эта процедура должна быть вызвана прежде, чем будет вызвана какая - либо другая MPI подпрограмма (кроме MPI_INITIALIZED). Она должна быть вызвана всего один раз; последующие вызовы неверны (см. MPI_INITIALIZED). Все MPI программы должны содержать вызов MPI_INIT. Версия для ANSI Си принимает argc и argv, которые являются аргументами к main:
int main(argc, argv)
int argc;
char **argv;
{
MPI_Init(&argc, &argv);
/* анализ аргументов */
/* головная программа */
MPI_Finalize(); /* смотри ниже */
}
Версия для языка ФОРТРАН содержит только IERROR.
Реализация MPI не требует, чтобы аргументы в вызове для Си были аргументами main.
Объяснение: MPI_INIT может использовать командную строку аргументов для инициализации среды MPI. Они передаются по ссылке, чтобы позволить реализации MPI обеспечить их в среде, где аргументы командной строки не предусмотрены для main.[]
Синтаксис функции MPI_FINALIZE представлен ниже.
MPI_FINALIZE() int MPI_Finalize(void) MPI_FINALIZE(IERROR) INTEGER IERROR void Finalize()
Эта процедура очищает все состояния MPI. Никакая другая процедура MPI (даже MPI_INIT) не может быть вызвана после выполнения этой процедуры. Пользователь обязан гарантировать, что все незаконченные обмены будут завершены прежде, чем будет вызвана MPI_FINALIZE.
Синтаксис функции MPI_INITIALIZED представлен ниже.
MPI_INITIALIZED(flag)
| OUT | flag | параметр flag принимает значение true, если MPI_INIT была вызвана и false в противном случае. |
int MPI_Initialized(int *flag)
MPI_INITIALIZED(FLAG, IERROR)
LOGICAL FLAG
INTEGER IERROR
bool MPI::Is_initialized()
Процедура MPI_INITIALIZED может использоваться для определения
того, был ли вызван
MPI_INIT. Это единственная процедура,
которая может быть вызвана перед MPI_INIT.
Синтаксис функции MPI_ABORT представлен ниже.
MPI_ABORT(comm, errorcode)
| IN | comm | коммуникатор прерываемой задачи | |
| IN | errorcode | код ошибки для возврата в среду исполнения |
int MPI_Abort(MPI_Comm comm, int errorcode)
MPI_ABORT(COMM, ERRORCODE, IERROR)
INTEGER COMM, ERRORCODE, IERROR
bool MPI::Is_finalized()
Процедура MPI_ABORT пробует наилучшим способом прервать выполнение всех задач в группе коммуникатора comm. Эта процедура не требует, чтобы исполнительная среда производила какие-либо действия с кодом ошибки. Однако, среда Unix или POSIX должна обрабатывать его как return errorcode из главной программы или abort (errorcode).
Реализация MPI должна определить поведение MPI_ABORT по крайней мере для коммуникатора MPI_COMM_WORLD. Реализация MPI может игнорировать аргумент comm и действовать, как если бы коммуникатором был MPI_COMM_WORLD.
Объяснение: Коммуникационный аргумент предусмотрен для будущих
расщирений MPI в отношении среды исполнения, например, для
динамического управления процессами. Это, в частности, позволяет
(но не требует) реализации MPI прекратить действие подмножества
MPI_COMM_WORLD.[]
Номер версии стандарта можно определить как на этапе компиляции, так и во время исполнения программы. ``Версия'' представляется двумя целыми величинами - для версии и подверсии:
В Си и С++:
#define MPI_VERSION 1
#define MPI_SUBVERSION 2
в языке ФОРТРАН:
INTEGER MPI_VERSION, MPI_SUBVERSION
PARAMETER (MPI_VERSION = 1)
PARAMETER (MPI_SUBVERSION = 2)
Для времени исполнения используется функция MPI_GET_VERSION, синтаксис которой представлен ниже.
MPI_GET_VERSION(version, subversion)
| OUT | version | Номер версии (целое) | |
| OUT | subversion | Номер подверсии (целое) |
int MPI_Get_version(int *version, int *subversion)
MPI_GET_VERSION(VERSION, SUBVERSION, IERROR)
INTEGER VERSION, SUBVERSION, IERROR
void Get_version(int& version, int& subversion)
MPI_GET_VERSION - одна из небольшого числа функций,
которые могут вызываться перед MPI_INIT и после MPI_FINALIZE.
Чтобы в MPI обеспечить интерфейс профилирования, реализация MPI должна:
Назначение интерфейса профилирования MPI состоит в том, чтобы облегчить разработчикам инструментов профилирования сопряжение их программ с реализациями MPI на различных машинах.
Поскольку MPI является машинно-независимым стандартом со многими различными реализациями, не следует ожидать, что авторы инструментальных средств профилирования для MPI будут иметь доступ к исходному коду, который реализует MPI на любой частной машине. Следовательно, необходимо обеспечить механизм, с помощью которого разработчики таких инструментальных средств смогут собирать любую информацию об эффективности, которую они пожелают, без доступа к низлежащей реализации.
Предполагается, что наличие такого интерфейса важно для того, чтобы MPI был привлекательным для конечных пользователей, так как доступность большого числа инструментальных средств будет значительным фактором в привлечении пользователей к MPI стандарту.
Интерфейс профилирования - это только интерфейс. В нем ничего не говорится относительно способа его использования. Следовательно, не предпринимается никакой попытки показать, как информация собирается интерфейсом, как собранная информация сохраняется, фильтруется или представляется.
Хотя начальным импульсом для развития этого интерфейса явилось желания создать инструменты профилирования, ясно, что подобный интерфейс может быть также полезным и для других целей, например, в ``интернете'' для множественных реализаций MPI.
Поскольку результаты, представленные здесь, тесно связаны со способом построения исполняемых файлов, которые могут существенно отличаться для различных машин, то примеры, приведенные ниже, нужно трактовать исключительно как один из способов выполнения интерфейса профилирования MPI. Фактические требования детально рассмотрены в разделе 8.1, вся остальная часть этой главы представляет собой обсуждение и обоснование логичности этих требований.
Представленные ниже примеры демонстрируют способ построения реализации для Unix-систем (несомненно, имеются и другие равноценные способы).
Если реализация MPI отвечает вышеупомянутым требованиям, система профилирования в состоянии перехватить все запросы MPI, сделанные в соответствии с программой пользователя. Затем можно собрать любую требуемую информацию перед обращением к основной реализации MPI (по ее имени, смещенному по отношению ко входной точке) для достижения желаемого результата.
При обсуждении процедур MPI используются следующие семантические термины. Первые два обычно применяются для коммуникационных операций.
Программа пользователя должна иметь возможность управлять профилированием во время своего исполнения. Обычно это необходимо для достижения (по крайней мере) следующих целей:
Эти требования удовлетворяются при использовании функции MPI_PCONTROL, синтаксис которой представлен ниже.
MPI_PCONTROL(level, ...)
| IN | level | уровень профилирования |
int MPI_Pcontrol(const int level, ...)
MPI_PCONTROL(LEVEL)
INTEGER LEVEL, ...
void Pcontrol(const int level, ...)
MPI библиотеки непосредственно не используют эту подпрограмму, они просто возвращаются немедленно к коду пользователя. Однако возможность обращения к этой процедуре позволяет пользователю явно вызвать блок профилирования.
Поскольку MPI не контролирует реализацию профилирующего кода, нельзя точно определить семантику, которая будет обеспечивать вызовы MPI_PCONTROL. Эта неопределенность распространяется на число аргументов функции и на их тип.
Однако, чтобы обеспечить некоторый уровень мобильности кода пользователя относительно различных библиотек профилирования, необходимо, чтобы определенные значения уровня имели следующий смысл:
Также требуется, чтобы после выполнения MPI_INIT по умолчанию было установлено профилирование (как если бы была выполнена операция MPI_PCONTROL с аргументом 1). Это позволяет пользователю связаться с библиотекой профилирования и получить результат профилирования без модификации их исходного текста.
Предположим, что система профилирования подсчитывает общий объем данных, посланных функцией MPI_SEND, и полное время выполнения этой функции. В простейшем случае этого можно достичь так:
static int totalBytes;
static double totalTime;
int MPI_SEND(void * buffer, const int count,
MPI_Datatype datatype, int dest, int tag, MPI_comm comm)
{
double tstart = MPI_Wtime(); /* передача на все аргументы */
int extent;
int result = PMPI_Send(buffer,count,datatype,dest,tag,comm);
MPI_Type_size(datatype, &extent); /* расчет размера */
totalBytes += count*extent;
totalTime += MPI_Wtime() - tstart; /* и времени */
return result;
}
На системе Unix, в которой библиотека MPI выполнена на Си, имеются различные опции. Рассмотрим далее две из них, наиболее распространенные. Критерием отбора лучших вариантов является то, поддерживает ли компилятор и редактор связей weak символы (символы со слабой связью).
Системы с ![]() символами
символами
Если компилятор и редактор связей поддерживают внешние слабые символы (например, Solaris 2.x, другая система V.4 машин), то тогда требуется единственная библиотека при использовании #pragma weak
#pragma weak MPI_Example = PMPI_Example
int PMPI_Example(/* соответствующие args */)
{
/* полезное содержание */
}
Результом этой #pragma является определение внешнего символа MPI_EXAMPLE как слабого. Это означает, что редактор связей не будет считать ошибкой тот факт, что имеется другое определение символа (например в библиотеке профилирования), однако, если никакого другого определения не существует, то редактор связей использует это слабое определение.
Системы без ![]() символов
символов
В случае отсутствия слабых символов одним возможным решением является использование макро-препроцессора Си таким образом:
#ifdef PROFILELIB # ifdef __STDC__ # define FUNCTION(name) P##name # else # define FUNCTION(name) P/**/name # endif #else # define FUNCTION(name) name #endif
Каждая из видимых пользователем функций в библиотеке была бы затем объявлена таким образом:
int FUNCTION(MPI_Example)(/* соответствующие args */)
{
/* полезное содержание */
}
Тот же самый исходный файл может затем быть скомпилирован, чтобы создать обе версии библиотеки в зависимости от состояния макро символа PROFILELIB.
Требуется, чтобы стандарт библиотеки MPI был построен таким образом, что включение функций MPI происходило по одной за один раз. Это неприятное требование, поскольку подразумевается, что каждая внешняя функция должна компилироваться из отдельного файла. Однако это необходимо для того, чтобы автор профилирующей библиотеки определял только те функции MPI, которые он хочет перехватить, ссылки на любые другие функции выполняются стандартной библиотекой MPI. Следовательно, этап компановки может выглядеть примерно так:
% cc ... -lmyprof -lpmpi -lmpi
Здесь libmyprof.a включает профилирующие функции , которые перехватывают некоторые функций из MPI. libpmpi.a содержит смещенные имена функцийMPI и libmpi.a содержит нормальные определение функций MPI.
Двойной подсчет
Поскольку часть функций библиотеки MPI может быть выражена через основные функции MPI (например, переносимая реализация коллективных операций написана с помощью парных обменов), имеется потенциальная возможность вызывать профилирующие функции из функции MPI, которая была вызвана из профилирующей функции. Это приведет к ``двойному подсчету'' времени выполнения внутренней подпрограммы. Так как этот эффект будет полезным при некоторых обстоятельствах (например, он может ответить на вопрос ``Сколько времени тратится на парные обмены, если они были вызваны из коллективных функций?''), то решено не вводить никаких ограничений для авторов библиотеки MPI, которые бы запретили этот эффект. Следовательно, авторы профилирующих библиотек должны осознавать эту проблему и защитить себя от нее. В однопоточной среде это может быть легко достигнуто с помощью статической переменной в коде профилирования, которая хранит информацию о том, находитесь ли вы внутри профилирующей подпрограммы или нет. Это становится более сложным в многопоточных средах.
Описанная выше схема непосредственно не поддерживает вложение функций профилирования, поскольку это обеспечивает только единственное альтернативное имя для каждой функции MPI. Рассмотривалась реализация, которая бы допускала множественные уровни перехвата, однако не удалось построить реализацию, которая не имела бы следующих недостатков:
Поскольку одной из целей MPI является создание эффективных приложений и не дело стандарта требовать отдельного языка реализаций, было решено принять схему, описанную выше.
Заметим однако, что можно использовать вышеприведенную схему для воплощения многоуровневой системы, так как функция, вызванная пользователем, может вызывать много различных функций профилирования перед вызовом основной функции MPI.
К сожалению такая реализация может потребовать обеспечения большей
кооперации между различными библиотеками профилирований, чем потребовалось
бы для реализации отдельного уровня, описанного выше.
[1] V. Bala and S. Kipnis. Process groups: a mechanism for the coordination
of and communication among processes in the Venus collective communication
library. Technical report, IBM T. J. Watson Research Center, October 1992.
Preprint.
[2] V. Bala, S. Kipnis, L. Rudolph, and Marc Snir. Designing efficient,
scalable, and portable collective communication libraries. Technical report,
IBM T. J. Watson Research Center, October 1992. Preprint.
[3] Purushotham V. Bangalore, Nathan E. Doss, and Anthony Skjellum. MPI++:
Issues and Features. In OON-SKI '94, page in press, 1994.
[4] A. Beguelin, J. Dongarra, A. Geist, R. Manchek, and V. Sunderam.
Visualization and debugging in a heterogeneous environment. IEEE
Computer, 26(6):88-95, June 1993.
[5] Luc Bomans and Rolf Hempel. The Argonne/GMD macros in FORTRAN for
portable parallel programming and their implementation on the Intel iPSC/2.
Parallel Computing, 15:119-132, 1990.
[6] R. Butler and E. Lusk. User's guide to the p4 programming system.
Technical Report TM-ANL-92/17, Argonne National Laboratory, 1992.
[7] Ralph Butler and Ewing Lusk. Monitors, messages, and clusters: the p4
parallel programming system. Journal of Parallel Computing, 1994.
to appear (Also Argonne National Laboratory Mathematics and Computer Science
Division preprint P362-0493).
[8] Robin Calkin, Rolf Hempel, Hans-Christian Hoppe, and Peter Wypior.
Portable programming with the parmacs message-passing library.
Parallel Computing, Special issue on message-passing interfaces,
to appear.
[9] S. Chittor and R. J. Enbody. Performance evaluation of mesh-connected
wormhole-routed networks for interprocessor communication in
multicomputers. In Proceedings of the 1990 Supercomputing
Conference, pages 647-656, 1990.
[10] S. Chittor and R. J. Enbody. Predicting the effect of mapping on the
communication performance of large multicomputers. In Proceedings of
the 1991 International Conference on Parallel Processing, vol. II
(Software), pages II-1 - II-4, 1991.
[11] J. Dongarra, A. Geist, R. Manchek, and V. Sunderam. Integrated PVM
framework supports heterogeneous network computing. Computers in
Physics, 7(2):166-75, April 1993.
[12] J. J. Dongarra, R. Hempel, A. J. G. Hey, and D. W. Walker. A proposal
for a user-level, message passing interface in a distributed memory
environment. Technical Report TM-12231, Oak Ridge National Laboratory,
February 1993.
[13] Nathan Doss, William Gropp, Ewing Lusk, and Anthony Skjellum. A model
implementation of MPI. Technical report, Argonne National Laboratory, 1993.
[14] Edinburgh Parallel Computing Centre, University of Edinburgh.
CHIMP Concepts, June 1991.
[15] Edinburgh Parallel Computing Centre, University of Edinburgh.
CHIMP Version 1.0 Interface, May 1992.
[16] D. Feitelson. Communicators: Object-based multiparty interactions for
parallel programming. Technical Report 91-12, Dept. Computer Science, The
Hebrew University of Jerusalem, November 1991.
[17] Hubertus Franke, Peter Hochschild, Pratap Pattnaik, and Marc Snir. An
efficient implementation of MPI. In 1994 International Conference on
Parallel Processing, 1994.
[18] G. A. Geist, M. T. Heath, B. W. Peyton, and P. H. Worley. A user's guide to PICL: a portable instrumented communication library. Technical Report TM-11616, Oak Ridge National Laboratory, October 1990.
[19] William D. Gropp and Barry Smith. Chameleon parallel programming tools
users manual. Technical Report ANL-93/23, Argonne National Laboratory, March
1993.
[20] O. Krämer and H. Mühlenbein. Mapping strategies in
message-based multiprocessor systems. Parallel Computing,
9:213-225, 1989.
[21] nCUBE Corporation. nCUBE 2 Programmers Guide, r2.0, December
1990.
[22] Parasoft Corporation, Pasadena, CA. Express User's Guide,
version 3.2.5 edition, 1992.
[23] Paul Pierce. The NX/2 operating system. In Proceedings of the
Third Conference on Hypercube Concurrent Computers and Applications, pages
384-390. ACM Press, 1988.
[24] A. Skjellum and A. Leung. Zipcode: a portable multicomputer
communication library atop the reactive kernel. In D. W. Walker and Q. F.
Stout, editors, Proceedings of the Fifth Distributed Memory
Concurrent Computing Conference, pages 767-776. IEEE Press, 1990.
[25] A. Skjellum, S. Smith, C. Still, A. Leung, and M. Morari. The Zipcode
message passing system. Technical report, Lawrence Livermore National
Laboratory, September 1992.
[26] Anthony Skjellum, Nathan E. Doss, and Purushotham V. Bangalore. Writing
Libraries in MPI. In Anthony Skjellum and Donna S. Reese, editors,
Proceedings of the Scalable Parallel Libraries Conference, pages
166-173. IEEE Computer Society Press, October 1993.
[27] Anthony Skjellum, Steven G. Smith, Nathan E. Doss, Alvin P . Leung, and
Manfred Morari. The Design and Evolution of Zipcode. Parallel
Computing, 1994. (Invited Paper, to appear in Special Issue on Message
Passing).
[28] Anthony Skjellum, Steven G. Smith, Nathan E. Doss, Charles H. Still,
Alvin P. Leung, and Manfred Morari. Zipcode: A Portable Communication Layer
for High Performance Multicomputing. Technical Report UCRL-JC-106725
(revised 9/92, 12/93, 4/94), Lawrence Livermore National Laboratory, March
1991. To appear in Concurrency: Practice & Experience.
[29] D. Walker. Standards for message passing in a distributed memory
environment. Technical Report TM-12147, Oak Ridge National Laboratory,
August 1992.
А1 Введение
В этом разделе представлены все привязки для языков ФОРТРАН и Си. Для каждого языка привязки разделяются на части, внутри которых они упорядочены по алфавиту.
А2 Константы для языков Си и ФОРТРАН
Здесь приведены константы, определенные в файлах mpi.h (для языка Си) и mpif.h (для языка ФОРТРАН).
/* возвращаемые коды (как для Си, так и для языка Фортран) */
MPI_SUCCESS
MPI_ERR_BUFFER
MPI_ERR_COUNT
MPI_ERR_TYPE
MPI_ERR_TAG
MPI_ERR_COMM
MPI_ERR_RANK
MPI_ERR_REQUEST
MPI_ERR_ROOT
MPI_ERR_GROUP
MPI_ERR_OP
MPI_ERR_TOPOLOGY
MPI_ERR_DIMS
MPI_ERR_ARG
MPI_ERR_UNKNOWN
MPI_ERR_TRUNCATE
MPI_ERR_OTHER
MPI_ERR_INTERN
MPI_ERR_PENDING
MPI_ERR_IN_STATUS
MPI_ERR_LASTCODE
/* разные константы (как для языка Си, так и для языка Фортран) */
MPI_BOTTOM
MPI_PROC_NULL
MPI_ANY_SOURCE
MPI_ANY_TAG
MPI_UNDEFINED
MPI_BSEND_OVERHEAD
MPI_KEYVAL_INVALID
/* размер статуса и резервируемые индексные значения (Фортран) */
MPI_STATUS_SIZE
MPI_SOURCE
MPI_TAG
MPI_ERROR
/* описатели обработчика ошибок (Си и Фортран) */
MPI_ERRORS_ARE_FATAL
MPI_ERRORS_RETURN
/* максимальные размеры строк */
MPI_MAX_PROCESSOR_NAME
MPI_MAX_ERROR_STRING
/* элементарные типы данных (Си) */
MPI_CHAR
MPI_SHORT
MPI_INT
MPI_LONG
MPI_UNSIGNED_CHAR
MPI_UNSIGNED_SHORT
MPI_UNSIGNED
MPI_UNSIGNED_LONG
MPI_FLOAT
MPI_DOUBLE
MPI_LONG_DOUBLE
MPI_BYTE
MPI_PACKED
/* элементарные типы данных(Фортран) */
MPI_INTEGER
MPI_REAL
MPI_DOUBLE_PRECISION
MPI_COMPLEX
MPI_LOGICAL
MPI_CHARACTER
MPI_BYTE
MPI_PACKED
/* типы данных для функций редукции (Си) */
MPI_FLOAT_INT
MPI_DOUBLE_INT
MPI_LONG_INT
MPI_2INT
MPI_SHORT_INT
MPI_LONG_DOUBLE_INT
/* типы данных для функций редукции (Фортран) */
MPI_2REAL
MPI_2DOUBLE_PRECISION
MPI_2INTEGER
/* дополнительные типы данных (Фортран) */
MPI_INTEGER1
MPI_INTEGER2
MPI_INTEGER4
MPI_REAL2
MPI_REAL4
MPI_REAL8
etc.
/* дополнительные типы данных (Си) */
MPI_LONG_LONG_INT
etc.
/* специальные типы данных для создания производных типов данных */
MPI_UB
MPI_LB
/* зарезервированные коммуникаторы (Си и Фортран) */
MPI_COMM_WORLD
MPI_COMM_SELF
/* результаты сравнения коммуникаторов и групп */
MPI_IDENT
MPI_CONGRUENT
MPI_SIMILAR
MPI_UNEQUAL
/* ключи запроса среды (Си и Фортран) */
MPI_TAG_UB
MPI_IO
MPI_HOST
MPI_WTIME_IS_GLOBAL
/* коллективные операции (Си и Фортран) */
MPI_MAX
MPI_MIN
MPI_SUM
MPI_PROD
MPI_MAXLOC
MPI_MINLOC
MPI_BAND
MPI_BOR
MPI_BXOR
MPI_LAND
MPI_LOR
MPI_LXOR
/* нулевые дескрипторы */
MPI_GROUP_NULL
MPI_COMM_NULL
MPI_DATATYPE_NULL
MPI_REQUEST_NULL
MPI_OP_NULL
MPI_ERRHANDLER_NULL
/* пустая группа */
MPI_GROUP_EMPTY
/* топологии (Си и Фортран) */
MPI_GRAPH
MPI_CART
/* предопределенные функции в Си и Фортран*/
MPI_NULL_COPY_FN
MPI_NULL_DELETE_FN
MPI_DUP_FN
Следующее есть типы Си, также включенные в файл mpi.h.
/* скрытые типы (Си) */
MPI_Aint
MPI_Status
/* дескрипторы различных структур (Си) */
MPI_Group
MPI_Comm
MPI_Datatype
MPI_Request
MPI_Op
MPI_Errhandler
/* прототипы для определенных пользователем функций (Си) */
typedef int MPI_Copy_function(MPI_Comm oldcomm, int keyval,
void *extra_state, void *attribute_val_in,
void *attribute_val_out, int *flag);
typedef int MPI_Delete_function(MPI_Comm comm, int keyval,
void *attribute_val, void *extra_state)
typedef void MPI_Handler_function(MPI_Comm *, int *, ...);
typedef void MPI_User_function( void *invec, void *inoutvec, int *len,
MPI_Datatype *datatype);
Далее даны примеры декларирования каждой из определенных пользователем функций для языка ФОРТРАН.
Аргумент пользовательской функции MPI_OP_CREATE декларируется следующим
образом:
SUBROUTINE USER_FUNCTION( INVEC, INOUTVEC, LEN, TYPE) <type> INVEC(LEN), INOUTVEC(LEN) INTEGER LEN, TYPE
Аргумент функции копирования MPI_KEYVAL_CREATE декларируется следующим
образом:
SUBROUTINE COPY_FUNCTION(OLDCOMM, KEYVAL, EXTRA_STATE,
ATTRIBUTE_VAL_IN, ATTRIBUTE_VAL_OUT, FLAG, IERR)
INTEGER OLDCOMM, KEYVAL, EXTRA_STATE, ATTRIBUTE_VAL_IN,
ATTRIBUTE_VAL_OUT, IERR
LOGICAL FLAG
Аргумент функции удаления MPI_KEYVAL_CREATE декларируется следующим
образом:
SUBROUTINE DELETE_FUNCTION(COMM, KEYVAL, ATTRIBUTE_VAL, EXTRA_STATE, IERR) INTEGER COMM, KEYVAL, ATTRIBUTE_VAL, EXTRA_STATE, IERR
Функция обработки для обработчиков ошибок декларируется следующим образом:
SUBROUTINE HANDLER_FUNCTION (COMM, ERROR_CODE, ...) INTEGER COMM, ERROR_CODE
А3 Привязки для парных обменов в языке Си
Функции представлены в порядке их появления в тексте стандарта
int MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest,
int tag, MPI_Comm comm)
int MPI_Recv(void* buf, int count, MPI_Datatype datatype, int source,
int tag, MPI_Comm comm, MPI_Status *status)
int MPI_Get_count(MPI_Status *status, MPI_Datatype datatype, int
*count)
int MPI_Bsend(void* buf, int count, MPI_Datatype datatype, int dest,
int tag, MPI_Comm comm)
int MPI_Ssend(void* buf, int count, MPI_Datatype datatype, int dest,
int tag, MPI_Comm comm)
int MPI_Rsend(void* buf, int count, MPI_Datatype datatype, int dest,
int tag, MPI_Comm comm)
int MPI_Buffer_attach( void* buffer, int size)
int MPI_Buffer_detach( void* buffer, int* size)
int MPI_Isend(void* buf, int count, MPI_Datatype datatype, int dest,
int tag, MPI_Comm comm, MPI_Request *request)
int MPI_Ibsend(void* buf, int count, MPI_Datatype datatype, int dest,
int tag, MPI_Comm comm, MPI_Request *request)
int MPI_Issend(void* buf, int count, MPI_Datatype datatype, int dest,
int tag, MPI_Comm comm, MPI_Request *request)
int MPI_Irsend(void* buf, int count, MPI_Datatype datatype, int dest,
int tag, MPI_Comm comm, MPI_Request *request)
int MPI_Irecv(void* buf, int count, MPI_Datatype datatype, int source,
int tag, MPI_Comm comm, MPI_Request *request)
int MPI_Wait(MPI_Request *request, MPI_Status *status)
int MPI_Test(MPI_Request *request, int *flag, MPI_Status *status)
int MPI_Request_free(MPI_Request *request)
int MPI_Waitany(int count, MPI_Request *array_of_requests, int *index,
MPI_Status *status)
int MPI_Testany(int count, MPI_Request *array_of_requests, int *index,
int *flag, MPI_Status *status)
int MPI_Waitall(int count, MPI_Request *array_of_requests, MPI_Status
*array_of_statuses)
int MPI_Testall(int count, MPI_Request *array_of_requests, int *flag,
MPI_Status *array_of_statuses)
int MPI_Waitsome(int incount, MPI_Request *array_of_requests, int
*outcount,int *array_of_indices, MPI_Status *array_of_statuses)
int MPI_Testsome(int incount, MPI_Request *array_of_requests, int
*outcount,int *array_of_indices, MPI_Status *array_of_statuses)
int MPI_Iprobe(int source, int tag, MPI_Comm comm, int *flag,
MPI_Status *status)
int MPI_Probe(int source, int tag, MPI_Comm comm, MPI_Status *status)
int MPI_Cancel(MPI_Request *request)
int MPI_Test_cancelled(MPI_Status *status, int *flag)
int MPI_Send_init(void* buf, int count, MPI_Datatype datatype, int
dest, int tag, MPI_Comm comm, MPI_Request *request)
int MPI_Bsend_init(void* buf, int count, MPI_Datatype datatype, int
dest, int tag, MPI_Comm comm, MPI_Request *request)
int MPI_Ssend_init(void* buf, int count, MPI_Datatype datatype, int
dest, int tag, MPI_Comm comm, MPI_Request *request)
int MPI_Rsend_init(void* buf, int count, MPI_Datatype datatype, int
dest, int tag, MPI_Comm comm, MPI_Request *request)
int MPI_Recv_init(void* buf, int count, MPI_Datatype datatype, int
source,int tag, MPI_Comm comm, MPI_Request *request)
int MPI_Start(MPI_Request *request)
int MPI_Startall(int count, MPI_Request *array_of_requests)
int MPI_Sendrecv(void *sendbuf, int sendcount, MPI_Datatype sendtype,
int dest, int sendtag, void *recvbuf, int recvcount, int recvtype,
int source, MPI_Datatype recvtag, MPI_Comm comm, MPI_Status *status)
int MPI_Sendrecv_replace(void* buf, int count, MPI_Datatype datatype,
int dest, int sendtag, int source, int recvtag, MPI_Comm comm,
MPI_Status *status)
int MPI_Type_contiguous(int count, MPI_Datatype oldtype,
MPI_Datatype *newtype)
int MPI_Type_vector(int count, int blocklength, int stride,
MPI_Datatype oldtype, MPI_Datatype *newtype)
int MPI_Type_hvector(int count, int blocklength, MPI_Aint stride,
MPI_Datatype oldtype, MPI_Datatype *newtype)
int MPI_Type_indexed(int count, int *array_of_blocklengths,
int *array_of_displacements, MPI_Datatype oldtype,
MPI_Datatype *newtype)
int MPI_Type_hindexed(int count, int *array_of_blocklengths,
MPI_Aint *array_of_displacements, MPI_Datatype oldtype,
MPI_Datatype *newtype)
int MPI_Type_struct(int count, int *array_of_blocklengths,
MPI_Aint *array_of_displacements, MPI_Datatype *array_of_types,
MPI_Datatype *newtype)
int MPI_Address(void* location, MPI_Aint *address)
int MPI_Type_extent(MPI_Datatype datatype, MPI_Aint *extent)
int MPI_Type_size(MPI_Datatype datatype, int *size)
int MPI_Type_lb(MPI_Datatype datatype, MPI_Aint* displacement)
int MPI_Type_ub(MPI_Datatype datatype, MPI_Aint* displacement)
int MPI_Type_commit(MPI_Datatype *datatype)
int MPI_Type_free(MPI_Datatype *datatype)
int MPI_Get_elements(MPI_Status *status, MPI_Datatype datatype,
int *count)
int MPI_Pack(void* inbuf, int incount, MPI_Datatype datatype,
void *outbuf,int outsize, int *position, MPI_Comm comm)
int MPI_Unpack(void* inbuf, int insize, int *position, void *outbuf,
int outcount, MPI_Datatype datatype, MPI_Comm comm)
int MPI_Pack_size(int incount, MPI_Datatype datatype, MPI_Comm comm,
int *size)
А4 Привязки для коллективных обменов в языке Си
int MPI_Barrier(MPI_Comm comm)
int MPI_Bcast(void* buffer, int count, MPI_Datatype datatype,
int root, MPI_Comm comm)
int MPI_Gather(void* sendbuf, int sendcount, MPI_Datatype sendtype,
void* recvbuf, int recvcount, MPI_Datatype recvtype, int root,
MPI_Comm comm)
int MPI_Gatherv(void* sendbuf, int sendcount, MPI_Datatype sendtype,
void* recvbuf, int *recvcounts, int *displs, MPI_Datatype recvtype,
int root, MPI_Comm comm)
int MPI_Scatter(void* sendbuf, int sendcount, MPI_Datatype sendtype,
void* recvbuf, int recvcount, MPI_Datatype recvtype, int root,
MPI_Comm comm)
int MPI_Scatterv(void* sendbuf, int *sendcounts, int *displs,
MPI_Datatype sendtype, void* recvbuf, int recvcount,
MPI_Datatype recvtype, int root, MPI_Comm comm)
int MPI_Allgather(void* sendbuf, int sendcount, MPI_Datatype sendtype,
void* recvbuf, int recvcount, MPI_Datatype recvtype, MPI_Comm comm)
int MPI_Allgatherv(void* sendbuf, int sendcount,
MPI_Datatype sendtype, void* recvbuf, int *recvcounts,
int *displs, MPI_Datatype recvtype, MPI_Comm comm)
int MPI_Alltoall(void* sendbuf, int sendcount, MPI_Datatype sendtype,
void* recvbuf, int recvcount, MPI_Datatype recvtype, MPI_Comm comm)
int MPI_Alltoallv(void* sendbuf, int *sendcounts, int *sdispls,
MPI_Datatype sendtype, void* recvbuf, int *recvcounts, int *rdispls,
MPI_Datatype recvtype, MPI_Comm comm)
int MPI_Reduce(void* sendbuf, void* recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm)
int MPI_Op_create(MPI_User_function *function, int commute, MPI_Op *op)
int MPI_Op_free( MPI_Op *op)
int MPI_Allreduce(void* sendbuf, void* recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
int MPI_Reduce_scatter(void* sendbuf, void* recvbuf, int *recvcounts,
MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
int MPI_Scan(void* sendbuf, void* recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
А5 Привязки для групп, контекстов и коммуникаторов в языке Си
int MPI_Group_size(MPI_Group group, int *size)
int MPI_Group_rank(MPI_Group group, int *rank)
int MPI_Group_translate_ranks (MPI_Group group1, int n, int *ranks1,
MPI_Group group2, int *ranks2)
int MPI_Group_compare(MPI_Group group1,MPI_Group group2, int *result)
int MPI_Comm_group(MPI_Comm comm, MPI_Group *group)
int MPI_Group_union(MPI_Group group1, MPI_Group group2, MPI_Group *newgroup)
int MPI_Group_intersection(MPI_Group group1, MPI_Group group2,
MPI_Group *newgroup)
int MPI_Group_difference(MPI_Group group1, MPI_Group group2,
MPI_Group *newgroup)
int MPI_Group_incl(MPI_Group group, int n, int *ranks, MPI_Group *newgroup)
int MPI_Group_excl(MPI_Group group, int n, int *ranks, MPI_Group *newgroup)
int MPI_Group_range_incl(MPI_Group group, int n, int ranges[][3],
MPI_Group *newgroup)
int MPI_Group_range_excl(MPI_Group group, int n, int ranges[][3],
MPI_Group *newgroup)
int MPI_Group_free(MPI_Group *group)
int MPI_Comm_size(MPI_Comm comm, int *size)
int MPI_Comm_rank(MPI_Comm comm, int *rank)
int MPI_Comm_compare(MPI_Comm comm1,MPI_Comm comm2, int *result)
int MPI_Comm_dup(MPI_Comm comm, MPI_Comm *newcomm)
int MPI_Comm_create(MPI_Comm comm, MPI_Group group, MPI_Comm *newcomm)
int MPI_Comm_split(MPI_Comm comm, int color, int key, MPI_Comm *newcomm)
int MPI_Comm_free(MPI_Comm *comm)
int MPI_Comm_test_inter(MPI_Comm comm, int *flag)
int MPI_Comm_remote_size(MPI_Comm comm, int *size)
int MPI_Comm_remote_group(MPI_Comm comm, MPI_Group *group)
int MPI_Intercomm_create(MPI_Comm local_comm, int local_leader,
MPI_Comm peer_comm, int remote_leader, int tag,
MPI_Comm *newintercomm)
int MPI_Intercomm_merge(MPI_Comm intercomm, int high,
MPI_Comm *newintracomm)
int MPI_Keyval_create(MPI_Copy_function *copy_fn,
MPI_Delete_function *delete_fn, int *keyval, void* extra_state)
int MPI_Keyval_free(int *keyval)
int MPI_Attr_put(MPI_Comm comm, int keyval, void* attribute_val)
int MPI_Attr_get(MPI_Comm comm, int keyval, void* attribute_val,
int *flag)
int MPI_Attr_delete(MPI_Comm comm, int keyval)
А6 Привязки для топологий процессов в языке Си
int MPI_Cart_create(MPI_Comm comm_old, int ndims, int *dims,
int *periods,int reorder, MPI_Comm *comm_cart)
int MPI_Dims_create(int nnodes, int ndims, int *dims)
int MPI_Graph_create(MPI_Comm comm_old, int nnodes, int *index,
int *edges,int reorder, MPI_Comm *comm_graph)
int MPI_Topo_test(MPI_Comm comm, int *status)
int MPI_Graphdims_get(MPI_Comm comm, int *nnodes, int *nedges)
int MPI_Graph_get(MPI_Comm comm, int maxindex, int maxedges,
int *index, int *edges)
int MPI_Cartdim_get(MPI_Comm comm, int *ndims)
int MPI_Cart_get(MPI_Comm comm, int maxdims, int *dims, int *periods,
int *coords)
int MPI_Cart_rank(MPI_Comm comm, int *coords, int *rank)
int MPI_Cart_coords(MPI_Comm comm, int rank, int maxdims, int *coords)
int MPI_Graph_neighbors_count(MPI_Comm comm, int rank,
int *nneighbors)
int MPI_Graph_neighbors(MPI_Comm comm, int rank, int maxneighbors,
int *neighbors)
int MPI_Cart_shift(MPI_Comm comm, int direction, int disp,
int *rank_source,int *rank_dest)
int MPI_Cart_sub(MPI_Comm comm, int *remain_dims, MPI_Comm *newcomm)
int MPI_Cart_map(MPI_Comm comm, int ndims, int *dims, int *periods,
int *newrank)
int MPI_Graph_map(MPI_Comm comm, int nnodes, int *index, int *edges,
int *newrank)
А7 Привязки для запросов среды в языке Си
int MPI_Get_processor_name(char *name, int *resultlen)
int MPI_Errhandler_create(MPI_Handler_function *function,
MPI_Errhandler *errhandler)
int MPI_Errhandler_set(MPI_Comm comm, MPI_Errhandler errhandler)
int MPI_Errhandler_get(MPI_Comm comm, MPI_Errhandler *errhandler)
int MPI_Errhandler_free(MPI_Errhandler *errhandler)
int MPI_Error_string(int errorcode, char *string, int *resultlen)
int MPI_Error_class(int errorcode, int *errorclass)
double MPI_Wtime(void)
double MPI_Wtick(void)
int MPI_Init(int *argc, char ***argv)
int MPI_Finalize(void)
int MPI_Initialized(int *flag)
int MPI_Abort(MPI_Comm comm, int errorcode)
А8 Привязки для профилирования Си в языке Си
int MPI_Pcontrol(const int level, ...)
А9 Привязки для парных обменов в языке ФОРТРАН
MPI_SEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR MPI_RECV(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR MPI_GET_COUNT(STATUS, DATATYPE, COUNT, IERROR) INTEGER STATUS(MPI_STATUS_SIZE), DATATYPE, COUNT, IERROR MPI_BSEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR MPI_SSEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR MPI_RSEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR MPI_BUFFER_ATTACH( BUFFER, SIZE, IERROR) <type> BUFFER(*) INTEGER SIZE, IERROR MPI_BUFFER_DETACH( BUFFER, SIZE, IERROR) <type> BUFFER(*) INTEGER SIZE, IERROR MPI_ISEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR MPI_IBSEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR MPI_ISSEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR MPI_IRSEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR MPI_IRECV(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR MPI_WAIT(REQUEST, STATUS, IERROR) INTEGER REQUEST, STATUS(MPI_STATUS_SIZE), IERROR MPI_TEST(REQUEST, FLAG, STATUS, IERROR) LOGICAL FLAG INTEGER REQUEST, STATUS(MPI_STATUS_SIZE), IERROR MPI_REQUEST_FREE(REQUEST, IERROR) INTEGER REQUEST, IERROR MPI_WAITANY(COUNT, ARRAY_OF_REQUESTS, INDEX, STATUS, IERROR) INTEGER COUNT, ARRAY_OF_REQUESTS(*), INDEX, STATUS(MPI_STATUS_SIZE), IERROR MPI_TESTANY(COUNT, ARRAY_OF_REQUESTS, INDEX, FLAG, STATUS, IERROR) LOGICAL FLAG INTEGER COUNT, ARRAY_OF_REQUESTS(*), INDEX, STATUS(MPI_STATUS_SIZE), IERROR MPI_WAITALL(COUNT, ARRAY_OF_REQUESTS, ARRAY_OF_STATUSES, IERROR) INTEGER COUNT, ARRAY_OF_REQUESTS(*), ARRAY_OF_STATUSES(MPI_STATUS_SIZE,*), IERROR MPI_TESTALL(COUNT, ARRAY_OF_REQUESTS, FLAG, ARRAY_OF_STATUSES, IERROR) LOGICAL FLAG INTEGER COUNT, ARRAY_OF_REQUESTS(*), ARRAY_OF_STATUSES(MPI_STATUS_SIZE,*), IERROR MPI_WAITSOME(INCOUNT, ARRAY_OF_REQUESTS, OUTCOUNT, ARRAY_OF_INDICES, ARRAY_OF_STATUSES, IERROR) INTEGER INCOUNT, ARRAY_OF_REQUESTS(*), OUTCOUNT, ARRAY_OF_INDICES(*), ARRAY_OF_STATUSES(MPI_STATUS_SIZE,*), IERROR MPI_TESTSOME(INCOUNT, ARRAY_OF_REQUESTS, OUTCOUNT, ARRAY_OF_INDICES, ARRAY_OF_STATUSES, IERROR) INTEGER INCOUNT, ARRAY_OF_REQUESTS(*), OUTCOUNT, ARRAY_OF_INDICES(*), ARRAY_OF_STATUSES(MPI_STATUS_SIZE,*), IERROR MPI_IPROBE(SOURCE, TAG, COMM, FLAG, STATUS, IERROR) LOGICAL FLAG INTEGER SOURCE, TAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR MPI_PROBE(SOURCE, TAG, COMM, STATUS, IERROR) INTEGER SOURCE, TAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR MPI_CANCEL(REQUEST, IERROR) INTEGER REQUEST, IERROR MPI_TEST_CANCELLED(STATUS, FLAG, IERROR) LOGICAL FLAG INTEGER STATUS(MPI_STATUS_SIZE), IERROR MPI_SEND_INIT(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR MPI_BSEND_INIT(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR MPI_SSEND_INIT(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR MPI_RSEND_INIT(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR MPI_RECV_INIT(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR MPI_START(REQUEST, IERROR) INTEGER REQUEST, IERROR MPI_STARTALL(COUNT, ARRAY_OF_REQUESTS, IERROR) INTEGER COUNT, ARRAY_OF_REQUESTS(*), IERROR MPI_SENDRECV(SENDBUF, SENDCOUNT, SENDTYPE, DEST, SENDTAG, RECVBUF, RECVCOUNT, RECVTYPE, SOURCE, RECVTAG, COMM, STATUS, IERROR) <type> SENDBUF(*), RECVBUF(*) INTEGER SENDCOUNT, SENDTYPE, DEST, SENDTAG, RECVCOUNT, RECVTYPE, SOURCE, RECVTAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR MPI_SENDRECV_REPLACE(BUF, COUNT, DATATYPE, DEST, SENDTAG, SOURCE, RECVTAG, COMM, STATUS, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, DEST, SENDTAG, SOURCE, RECVTAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR MPI_TYPE_CONTIGUOUS(COUNT, OLDTYPE, NEWTYPE, IERROR) INTEGER COUNT, OLDTYPE, NEWTYPE, IERROR MPI_TYPE_VECTOR(COUNT, BLOCKLENGTH, STRIDE, OLDTYPE, NEWTYPE, IERROR) INTEGER COUNT, BLOCKLENGTH, STRIDE, OLDTYPE, NEWTYPE, IERROR MPI_TYPE_HVECTOR(COUNT, BLOCKLENGTH, STRIDE, OLDTYPE, NEWTYPE, IERROR) INTEGER COUNT, BLOCKLENGTH, STRIDE, OLDTYPE, NEWTYPE, IERROR MPI_TYPE_INDEXED(COUNT, ARRAY_OF_BLOCKLENGTHS, ARRAY_OF_DISPLACEMENTS, OLDTYPE, NEWTYPE, IERROR) INTEGER COUNT, ARRAY_OF_BLOCKLENGTHS(*), ARRAY_OF_DISPLACEMENTS(*), OLDTYPE, NEWTYPE, IERROR MPI_TYPE_HINDEXED(COUNT, ARRAY_OF_BLOCKLENGTHS, ARRAY_OF_DISPLACEMENTS, OLDTYPE, NEWTYPE, IERROR) INTEGER COUNT, ARRAY_OF_BLOCKLENGTHS(*), ARRAY_OF_DISPLACEMENTS(*), OLDTYPE, NEWTYPE, IERROR MPI_TYPE_STRUCT(COUNT, ARRAY_OF_BLOCKLENGTHS, ARRAY_OF_DISPLACEMENTS, ARRAY_OF_TYPES, NEWTYPE, IERROR) INTEGER COUNT, ARRAY_OF_BLOCKLENGTHS(*), ARRAY_OF_DISPLACEMENTS(*), ARRAY_OF_TYPES(*), NEWTYPE, IERROR MPI_ADDRESS(LOCATION, ADDRESS, IERROR) <type> LOCATION(*) INTEGER ADDRESS, IERROR MPI_TYPE_EXTENT(DATATYPE, EXTENT, IERROR) INTEGER DATATYPE, EXTENT, IERROR MPI_TYPE_SIZE(DATATYPE, SIZE, IERROR) INTEGER DATATYPE, SIZE, IERROR MPI_TYPE_LB( DATATYPE, DISPLACEMENT, IERROR) INTEGER DATATYPE, DISPLACEMENT, IERROR MPI_TYPE_UB( DATATYPE, DISPLACEMENT, IERROR) INTEGER DATATYPE, DISPLACEMENT, IERROR MPI_TYPE_COMMIT(DATATYPE, IERROR) INTEGER DATATYPE, IERROR MPI_TYPE_FREE(DATATYPE, IERROR) INTEGER DATATYPE, IERROR MPI_GET_ELEMENTS(STATUS, DATATYPE, COUNT, IERROR) INTEGER STATUS(MPI_STATUS_SIZE), DATATYPE, COUNT, IERROR MPI_PACK(INBUF, INCOUNT, DATATYPE, OUTBUF, OUTSIZE, POSITION, COMM, IERROR) <type> INBUF(*), OUTBUF(*) INTEGER INCOUNT, DATATYPE, OUTSIZE, POSITION, COMM, IERROR MPI_UNPACK(INBUF, INSIZE, POSITION, OUTBUF, OUTCOUNT, DATATYPE, COMM, IERROR) <type> INBUF(*), OUTBUF(*) INTEGER INSIZE, POSITION, OUTCOUNT, DATATYPE, COMM, IERROR MPI_PACK_SIZE(INCOUNT, DATATYPE, COMM, SIZE, IERROR) INTEGER INCOUNT, DATATYPE, COMM, SIZE, IERROR
А10 Привязки для коллективных обменов в языке ФОРТРАН
MPI_BARRIER(COMM, IERROR) INTEGER COMM, IERROR MPI_BCAST(BUFFER, COUNT, DATATYPE, ROOT, COMM, IERROR) <type> BUFFER(*) INTEGER COUNT, DATATYPE, ROOT, COMM, IERROR MPI_GATHER(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF, RECVCOUNT, RECVTYPE, ROOT, COMM, IERROR) <type> SENDBUF(*), RECVBUF(*) INTEGER SENDCOUNT, SENDTYPE, RECVCOUNT, RECVTYPE, ROOT, COMM, IERROR MPI_GATHERV(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF, RECVCOUNTS, DISPLS, RECVTYPE, ROOT, COMM, IERROR) <type> SENDBUF(*), RECVBUF(*) INTEGER SENDCOUNT, SENDTYPE, RECVCOUNTS(*), DISPLS(*), RECVTYPE, ROOT, COMM, IERROR MPI_SCATTER(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF, RECVCOUNT, RECVTYPE, ROOT, COMM, IERROR) <type> SENDBUF(*), RECVBUF(*) INTEGER SENDCOUNT, SENDTYPE, RECVCOUNT, RECVTYPE, ROOT, COMM, IERROR MPI_SCATTERV(SENDBUF, SENDCOUNTS, DISPLS, SENDTYPE, RECVBUF, RECVCOUNT, RECVTYPE, ROOT, COMM, IERROR) <type> SENDBUF(*), RECVBUF(*) INTEGER SENDCOUNTS(*), DISPLS(*), SENDTYPE, RECVCOUNT, RECVTYPE, ROOT, COMM, IERROR MPI_ALLGATHER(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF, RECVCOUNT, RECVTYPE, COMM, IERROR) <type> SENDBUF(*), RECVBUF(*) INTEGER SENDCOUNT, SENDTYPE, RECVCOUNT, RECVTYPE, COMM, IERROR MPI_ALLGATHERV(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF, RECVCOUNTS, DISPLS, RECVTYPE, COMM, IERROR) <type> SENDBUF(*), RECVBUF(*) INTEGER SENDCOUNT, SENDTYPE, RECVCOUNTS(*), DISPLS(*), RECVTYPE, COMM, IERROR MPI_ALLTOALL(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF, RECVCOUNT, RECVTYPE, COMM, IERROR) <type> SENDBUF(*), RECVBUF(*) INTEGER SENDCOUNT, SENDTYPE, RECVCOUNT, RECVTYPE, COMM, IERROR MPI_ALLTOALLV(SENDBUF, SENDCOUNTS, SDISPLS, SENDTYPE, RECVBUF, RECVCOUNTS, RDISPLS, RECVTYPE, COMM, IERROR) <type> SENDBUF(*), RECVBUF(*) INTEGER SENDCOUNTS(*), SDISPLS(*), SENDTYPE, RECVCOUNTS(*), RDISPLS(*), RECVTYPE, COMM, IERROR MPI_REDUCE(SENDBUF, RECVBUF, COUNT, DATATYPE, OP, ROOT, COMM, IERROR) <type> SENDBUF(*), RECVBUF(*) INTEGER COUNT, DATATYPE, OP, ROOT, COMM, IERROR MPI_OP_CREATE( FUNCTION, COMMUTE, OP, IERROR) EXTERNAL FUNCTION LOGICAL COMMUTE INTEGER OP, IERROR MPI_OP_FREE( OP, IERROR) INTEGER OP, IERROR MPI_ALLREDUCE(SENDBUF, RECVBUF, COUNT, DATATYPE, OP, COMM, IERROR) <type> SENDBUF(*), RECVBUF(*) INTEGER COUNT, DATATYPE, OP, COMM, IERROR MPI_REDUCE_SCATTER(SENDBUF, RECVBUF, RECVCOUNTS, DATATYPE, OP, COMM, IERROR) <type> SENDBUF(*), RECVBUF(*) INTEGER RECVCOUNTS(*), DATATYPE, OP, COMM, IERROR PI_SCAN(SENDBUF, RECVBUF, COUNT, DATATYPE, OP, COMM, IERROR) <type> SENDBUF(*), RECVBUF(*) INTEGER COUNT, DATATYPE, OP, COMM, IERROR
А11 Привязки языка ФОРТРАН для групп, контекстов и так далее
MPI_GROUP_SIZE(GROUP, SIZE, IERROR) INTEGER GROUP, SIZE, IERROR MPI_GROUP_RANK(GROUP, RANK, IERROR) INTEGER GROUP, RANK, IERROR MPI_GROUP_TRANSLATE_RANKS(GROUP1, N, RANKS1, GROUP2, RANKS2, IERROR) INTEGER GROUP1, N, RANKS1(*), GROUP2, RANKS2(*), IERROR MPI_GROUP_COMPARE(GROUP1, GROUP2, RESULT, IERROR) INTEGER GROUP1, GROUP2, RESULT, IERROR MPI_COMM_GROUP(COMM, GROUP, IERROR) INTEGER COMM, GROUP, IERROR MPI_GROUP_UNION(GROUP1, GROUP2, NEWGROUP, IERROR) INTEGER GROUP1, GROUP2, NEWGROUP, IERROR MPI_GROUP_INTERSECTION(GROUP1, GROUP2, NEWGROUP, IERROR) INTEGER GROUP1, GROUP2, NEWGROUP, IERROR MPI_GROUP_DIFFERENCE(GROUP1, GROUP2, NEWGROUP, IERROR) INTEGER GROUP1, GROUP2, NEWGROUP, IERROR MPI_GROUP_INCL(GROUP, N, RANKS, NEWGROUP, IERROR) INTEGER GROUP, N, RANKS(*), NEWGROUP, IERROR MPI_GROUP_EXCL(GROUP, N, RANKS, NEWGROUP, IERROR) INTEGER GROUP, N, RANKS(*), NEWGROUP, IERROR MPI_GROUP_RANGE_INCL(GROUP, N, RANGES, NEWGROUP, IERROR) INTEGER GROUP, N, RANGES(3,*), NEWGROUP, IERROR MPI_GROUP_RANGE_EXCL(GROUP, N, RANGES, NEWGROUP, IERROR) INTEGER GROUP, N, RANGES(3,*), NEWGROUP, IERROR MPI_GROUP_FREE(GROUP, IERROR) INTEGER GROUP, IERROR MPI_COMM_SIZE(COMM, SIZE, IERROR) INTEGER COMM, SIZE, IERROR MPI_COMM_RANK(COMM, RANK, IERROR) INTEGER COMM, RANK, IERROR MPI_COMM_COMPARE(COMM1, COMM2, RESULT, IERROR) INTEGER COMM1, COMM2, RESULT, IERROR MPI_COMM_DUP(COMM, NEWCOMM, IERROR) INTEGER COMM, NEWCOMM, IERROR MPI_COMM_CREATE(COMM, GROUP, NEWCOMM, IERROR) INTEGER COMM, GROUP, NEWCOMM, IERROR MPI_COMM_SPLIT(COMM, COLOR, KEY, NEWCOMM, IERROR) INTEGER COMM, COLOR, KEY, NEWCOMM, IERROR MPI_COMM_FREE(COMM, IERROR) INTEGER COMM, IERROR MPI_COMM_TEST_INTER(COMM, FLAG, IERROR) INTEGER COMM, IERROR LOGICAL FLAG MPI_COMM_REMOTE_SIZE(COMM, SIZE, IERROR) INTEGER COMM, SIZE, IERROR MPI_COMM_REMOTE_GROUP(COMM, GROUP, IERROR) INTEGER COMM, GROUP, IERROR MPI_INTERCOMM_CREATE(LOCAL_COMM, LOCAL_LEADER, PEER_COMM, REMOTE_LEADER, TAG, NEWINTERCOMM, IERROR) INTEGER LOCAL_COMM, LOCAL_LEADER, PEER_COMM, REMOTE_LEADER, TAG, NEWINTERCOMM, IERROR MPI_INTERCOMM_MERGE(INTERCOMM, HIGH, NEWINTRACOMM, IERROR) INTEGER INTERCOMM, NEWINTRACOMM, IERROR LOGICAL HIGH MPI_KEYVAL_CREATE(COPY_FN, DELETE_FN, KEYVAL, EXTRA_STATE, IERROR) EXTERNAL COPY_FN, DELETE_FN INTEGER KEYVAL, EXTRA_STATE, IERROR MPI_KEYVAL_FREE(KEYVAL, IERROR) INTEGER KEYVAL, IERROR MPI_ATTR_PUT(COMM, KEYVAL, ATTRIBUTE_VAL, IERROR) INTEGER COMM, KEYVAL, ATTRIBUTE_VAL, IERROR MPI_ATTR_GET(COMM, KEYVAL, ATTRIBUTE_VAL, FLAG, IERROR) INTEGER COMM, KEYVAL, ATTRIBUTE_VAL, IERROR LOGICAL FLAG MPI_ATTR_DELETE(COMM, KEYVAL, IERROR) INTEGER COMM, KEYVAL, IERROR
А12 Привязки для топологий процессов в языке ФОРТРАН
MPI_CART_CREATE(COMM_OLD, NDIMS, DIMS, PERIODS, REORDER, COMM_CART, IERROR) INTEGER COMM_OLD, NDIMS, DIMS(*), COMM_CART, IERROR LOGICAL PERIODS(*), REORDER MPI_DIMS_CREATE(NNODES, NDIMS, DIMS, IERROR) INTEGER NNODES, NDIMS, DIMS(*), IERROR MPI_GRAPH_CREATE(COMM_OLD, NNODES, INDEX, EDGES, REORDER, COMM_GRAPH, IERROR) INTEGER COMM_OLD, NNODES, INDEX(*), EDGES(*), COMM_GRAPH, IERROR LOGICAL REORDER MPI_TOPO_TEST(COMM, STATUS, IERROR) INTEGER COMM, STATUS, IERROR MPI_GRAPHDIMS_GET(COMM, NNODES, NEDGES, IERROR) INTEGER COMM, NNODES, NEDGES, IERROR MPI_GRAPH_GET(COMM, MAXINDEX, MAXEDGES, INDEX, EDGES, IERROR) INTEGER COMM, MAXINDEX, MAXEDGES, INDEX(*), EDGES(*), IERROR MPI_CARTDIM_GET(COMM, NDIMS, IERROR) INTEGER COMM, NDIMS, IERROR MPI_CART_GET(COMM, MAXDIMS, DIMS, PERIODS, COORDS, IERROR) INTEGER COMM, MAXDIMS, DIMS(*), COORDS(*), IERROR LOGICAL PERIODS(*) MPI_CART_RANK(COMM, COORDS, RANK, IERROR) INTEGER COMM, COORDS(*), RANK, IERROR MPI_CART_COORDS(COMM, RANK, MAXDIMS, COORDS, IERROR) INTEGER COMM, RANK, MAXDIMS, COORDS(*), IERROR MPI_GRAPH_NEIGHBORS_COUNT(COMM, RANK, NNEIGHBORS, IERROR) INTEGER COMM, RANK, NNEIGHBORS, IERROR MPI_GRAPH_NEIGHBORS(COMM, RANK, MAXNEIGHBORS, NEIGHBORS, IERROR) INTEGER COMM, RANK, MAXNEIGHBORS, NEIGHBORS(*), IERROR MPI_CART_SHIFT(COMM, DIRECTION, DISP, RANK_SOURCE, RANK_DEST, IERROR) INTEGER COMM, DIRECTION, DISP, RANK_SOURCE, RANK_DEST, IERROR MPI_CART_SUB(COMM, REMAIN_DIMS, NEWCOMM, IERROR) INTEGER COMM, NEWCOMM, IERROR LOGICAL REMAIN_DIMS(*) MPI_CART_MAP(COMM, NDIMS, DIMS, PERIODS, NEWRANK, IERROR) INTEGER COMM, NDIMS, DIMS(*), NEWRANK, IERROR LOGICAL PERIODS(*) MPI_GRAPH_MAP(COMM, NNODES, INDEX, EDGES, NEWRANK, IERROR) INTEGER COMM, NNODES, INDEX(*), EDGES(*), NEWRANK, IERROR
А13 Привязки для запросов среды в языке ФОРТРАН
MPI_GET_PROCESSOR_NAME(NAME, RESULTLEN, IERROR) CHARACTER*(*) NAME INTEGER RESULTLEN, IERROR MPI_ERRHANDLER_CREATE(FUNCTION, ERRHANDLER, IERROR) EXTERNAL FUNCTION INTEGER ERRHANDLER, IERROR MPI_ERRHANDLER_SET(COMM, ERRHANDLER, IERROR) INTEGER COMM, ERRHANDLER, IERROR MPI_ERRHANDLER_GET(COMM, ERRHANDLER, IERROR) INTEGER COMM, ERRHANDLER, IERROR MPI_ERRHANDLER_FREE(ERRHANDLER, IERROR) INTEGER ERRHANDLER, IERROR MPI_ERROR_STRING(ERRORCODE, STRING, RESULTLEN, IERROR) INTEGER ERRORCODE, RESULTLEN, IERROR CHARACTER*(*) STRING MPI_ERROR_CLASS(ERRORCODE, ERRORCLASS, IERROR) INTEGER ERRORCODE, ERRORCLASS, IERROR DOUBLE PRECISION MPI_WTIME() DOUBLE PRECISION MPI_WTICK() MPI_INIT(IERROR) INTEGER IERROR MPI_FINALIZE(IERROR) INTEGER IERROR MPI_INITIALIZED(FLAG, IERROR) LOGICAL FLAG INTEGER IERROR MPI_ABORT(COMM, ERRORCODE, IERROR) INTEGER COMM, ERRORCODE, IERROR
А14 Привязки языка ФОРТРАН для профилирования
MPI_PCONTROL(LEVEL) INTEGER LEVEL, ...
B1 Классы языка С++
Ниже представлены классы языка С++ в привязках для MPI-1:
namespace MPI {
class Comm {...};
class Intracomm : public Comm {...};
class Graphcomm : public Intracomm {...};
class Cartcomm : public Intracomm {...};
class Intercomm : public Comm {...};
class Datatype {...};
class Errhandler {...};
class Exception {...};
class Group {...};
class Op {...};
class Request {...};
class Prequest : public Request {...};
class Status {...};
};
Заметим, что некоторые функции, константы и типы данных MPI-1 устарели и поэтому не имеют соответствующих привязок С++. Все устаревшие имена имеют соответствующие новые имена в MPI-2 (хотя, возможно, с новой семантикой).
B2 Константы
Эти константы определены в файлах mpi.h. Для краткости типы констант
определяются в комментариях.
// возвращаемые коды // Тип: const int (или unnamed enum) MPI::SUCCESS MPI::ERR_BUFFER MPI::ERR_COUNT MPI::ERR_TYPE MPI::ERR_TAG MPI::ERR_COMM MPI::ERR_RANK MPI::ERR_REQUEST MPI::ERR_ROOT MPI::ERR_GROUP MPI::ERR_OP MPI::ERR_TOPOLOGY MPI::ERR_DIMS MPI::ERR_ARG MPI::ERR_UNKNOWN MPI::ERR_TRUNCATE MPI::ERR_OTHER MPI::ERR_INTERN MPI::ERR_PENDING MPI::ERR_IN_STATUS MPI::ERR_LASTCODE // различные константы // Тип: const void * MPI::BOTTOM // Тип: константы int (или unnamed enum) MPI::PROC_NULL MPI::ANY_SOURCE MPI::ANY_TAG MPI::UNDEFINED MPI::BSEND_OVERHEAD MPI::KEYVAL_INVALID // описатели для обработки ошибок // Тип: MPI::Errhandler (см. ниже) MPI::ERRORS_ARE_FATAL MPI::ERRORS_RETURN MPI::ERRORS_THROW_EXCEPTIONS // Максимальный размер строки // Тип: const int MPI::MAX_PROCESSOR_NAME MPI::MAX_ERROR_STRING // элементарные типы данных (Си / C++) // Тип: const MPI::Datatype MPI::CHAR MPI::SHORT MPI::INT MPI::LONG MPI::SIGNED_CHAR MPI::UNSIGNED_CHAR MPI::UNSIGNED_SHORT MPI::UNSIGNED MPI::UNSIGNED_LONG MPI::FLOAT MPI::DOUBLE MPI::LONG_DOUBLE MPI::BYTE MPI::PACKED // элементарные типы данных (Фортран) // Тип: const MPI::Datatype MPI::INTEGER MPI::REAL MPI::DOUBLE_PRECISION MPI::F_COMPLEX MPI::F_DOUBLE_COMPLEX MPI::LOGICAL MPI::CHARACTER // типы данных для функций редукции (Си / C++) // Тип: const MPI::Datatype MPI::FLOAT_INT MPI::DOUBLE_INT MPI::LONG_INT MPI::TWOINT MPI::SHORT_INT MPI::LONG_DOUBLE_INT // типы данных для функций редукции (Фортран) // Тип const MPI::Datatype MPI::TWOREAL MPI::TWODOUBLE_PRECISION MPI::TWOINTEGER // дополнительные типы данных данных (Фортран) // Тип: const MPI::Datatype MPI::INTEGER1 MPI::INTEGER2 MPI::INTEGER4 MPI::REAL2 MPI::REAL4 MPI::REAL8 // дополнительные типы данных (Си / C++) // Type: const MPI::Datatype MPI::LONG_LONG MPI::UNSIGNED_LONG_LONG // специальные типы данных для для создания производных типов данных // Тип: const MPI::Datatype MPI::UB MPI::LB // типы данных C++ // Тип: const MPI::Datatype MPI::BOOL MPI::COMPLEX MPI::DOUBLE_COMPLEX MPI::LONG_DOUBLE_COMPLEX // зарезервированные коммуникаторы // Тип: MPI::Intracomm MPI::COMM_WORLD MPI::COMM_SELF // результаты сравнения для коммуникаторов и групп // Тип: const int (или unnamed enum) MPI::IDENT MPI::CONGRUENT MPI::SIMILAR MPI::UNEQUAL // ключи запрсов среды // Тип: const int (или unnamed enum) MPI::TAG_UB MPI::IO MPI::HOST MPI::WTIME_IS_GLOBAL // коллективные операции // Тип: const MPI::Op MPI::MAX MPI::MIN MPI::SUM MPI::PROD MPI::MAXLOC MPI::MINLOC MPI::BAND MPI::BOR MPI::BXOR MPI::LAND MPI::LOR MPI::LXOR // нулевые дескрипторы // Тип: const MPI::Group MPI::GROUP_NULL MPI::COMM_NULL // Тип: const MPI::Datatype MPI::DATATYPE_NULL // Тип: const MPI::Request MPI::REQUEST_NULL // Тип: const MPI::Op MPI::OP_NULL // Тип: MPI::Errhandler MPI::ERRHANDLER_NULL // Пустая группа // Тип: const MPI::Group MPI::GROUP_EMPTY // Топологии // Тип: const int (или unnamed enum) MPI::GRAPH MPI::CART // Предопределенные функции // Тип: MPI::Copy_function MPI::NULL_COPY_FN MPI::DUP_FN // Тип: MPI::Delete_function MPI::NULL_DELETE_FN
B3 Определение типов
Следующее есть типы С++ , также включенные в файл mpi.h.
// Typedef MPI::Aint
Далее в этом приложении используется обозначение пространства имен, поскольку все функции из списка ниже имеют прототипы. Эта нотация не использовалась раньше, поскольку списки констант и типов выше не являются фактическими декларациями.
// прототипы для определенных пользователем функций
namespace MPI {
typedef void User_function(const void *invec, void* inoutvec, int len, const
Datatype& datatype);
};
B4 Привязки для парных обменов в языке С++
Кроме специально отмеченных случаев, все не статические функции в этом приложении виртуальные. Для краткости ключевое слово virtual пропущено.
namespace MPI{
void Comm::Send(const void* buf, int count,
const Datatype& datatype, int dest, int tag) const
void Comm::Recv(void* buf, int count, const Datatype& datatype,
int source, int tag, Status& status) const
void Comm::Recv(void* buf, int count, const Datatype& datatype,
int source, int tag) const
int Status::Get_count(const Datatype& datatype) const
void Comm::Bsend(const void* buf, int count, const Datatype& datatype,
int dest, int tag) const
void Comm::Ssend(const void* buf, int count, const Datatype& datatype,
int dest, int tag) const
void Comm::Rsend(const void* buf, int count, const Datatype& datatype,
int dest, int tag) const
void Attach_buffer(void* buffer, int size)
int Detach_buffer(void*& buffer)
Request Comm::Isend(const void* buf, int count, const Datatype& datatype,
int dest, int tag) const
Request Comm::Ibsend(const void* buf, int count, const Datatype& datatype,
int dest, int tag) const
Request Comm::Issend(const void* buf, int count, const Datatype& datatype,
int dest, int tag) const
Request Comm::Irsend(const void* buf, int count, const Datatype& datatype,
int dest, int tag) const
Request Comm::Irecv(void* buf, int count, const Datatype& datatype,
int source, int tag) const
void Request::Wait(Status& status)
void Request::Wait()
bool Request::Test(Status& status)
bool Request::Test()
void Request::Free()
static int Request::Waitany(int count, Request array_of_requests[], Status&
status)
static int Request::Waitany(int count, Request array_of_requests[])
static bool Request::Testany(int count, Request array_of_requests[],
int& index, Status& status)
static bool Request::Testany(int count, Request array_of_requests[], int& index)
static void Request::Waitall(int count, Request array_of_requests[],
Status array_of_statuses[])
static void Request::Waitall(int count, Request array_of_requests[])
static bool Request::Testall(int count, Request array_of_requests[],
Status array_of_statuses[])
static bool Request::Testall(int count, Request array_of_requests[])
static int Request::Waitsome(int incount, Request array_of_requests[],
int array_of_indices[], Status array_of_statuses[])
static int Request::Waitsome(int incount, Request array_of_requests[],
int array_of_indices[])
static int Request::Testsome(int incount, Request array_of_requests[],
int array_of_indices[], Status array_of_statuses[])
static int Request::Testsome(int incount, Request array_of_requests[],
int array_of_indices[])
bool Comm::Iprobe(int source, int tag, Status& status) const
bool Comm::Iprobe(int source, int tag) const
void Comm::Probe(int source, int tag, Status& status) const
void Comm::Probe(int source, int tag) const
void Request::Cancel() const
bool Status::Is_cancelled() const
Prequest Comm::Send_init(const void* buf, int count,
const Datatype& datatype, int dest, int tag) const
Prequest Comm::Bsend_init(const void* buf, int count,
const Datatype& datatype, int dest, int tag) const
Prequest Comm::Ssend_init(const void* buf, int count,
const Datatype& datatype, int dest, int tag) const
Prequest Comm::Rsend_init(const void* buf, int count,
const Datatype& datatype, int dest, int tag) const
Prequest Comm::Recv_init(void* buf, int count,
const Datatype& datatype, int source, int tag) const
void Prequest::Start()
static void Prequest::Startall(int count, Prequest array_of_requests[])
void Comm::Sendrecv(const void *sendbuf, int sendcount,
const Datatype& sendtype, int dest, int sendtag, void *recvbuf,
int recvcount, const Datatype& recvtype, int source, int recvtag,
Status& status) const
void Comm::Sendrecv(const void *sendbuf, int sendcount,
const Datatype& sendtype, int dest, int sendtag, void *recvbuf,
int recvcount, const Datatype& recvtype, int source, int recvtag) const
void Comm::Sendrecv_replace(void* buf, int count,
const Datatype& datatype, int dest, int sendtag, int source,
int recvtag, Status& status) const
void Comm::Sendrecv_replace(void* buf, int count,
const Datatype& datatype, int dest, int sendtag, int source, int recvtag)
const
Datatype Datatype::Create_contiguous(int count) const
Datatype Datatype::Create_vector(int count, int blocklength, int stride) const
Datatype Datatype::Create_indexed(int count, const int array_of_blocklengths[],
const int array_of_displacements[]) const
int Datatype::Get_size() const
void Datatype::Commit()
void Datatype::Free()
int Status::Get_elements(const Datatype& datatype) const
void Datatype::Pack(const void* inbuf, int incount, void *outbuf,
int outsize, int& position, const Comm &comm) const
void Datatype::Unpack(const void* inbuf, int insize, void *outbuf,
int outcount, int& position, const Comm& comm) const
int Datatype::Pack_size(int incount, const Comm& comm) const
};
B5 Привязки для коллективных обменов в языке С++
namespace MPI {
void Intracomm::Barrier() const
void Intracomm::Bcast(void* buffer, int count,
const Datatype& datatype, int root) const
void Intracomm::Gather(const void* sendbuf, int sendcount,
const Datatype& sendtype, void* recvbuf, int recvcount,
const Datatype& recvtype, int root) const
void Intracomm::Gatherv(const void* sendbuf, int sendcount,
const Datatype& sendtype, void* recvbuf, const int recvcounts[],
const int displs[], const Datatype& recvtype, int root) const
void Intracomm::Scatter(const void* sendbuf, int sendcount,
const Datatype& sendtype, void* recvbuf, int recvcount,
const Datatype& recvtype, int root) const
void Intracomm::Scatterv(const void* sendbuf, const int sendcounts[],
const int displs[], const Datatype& sendtype, void* recvbuf,
int recvcount, const Datatype& recvtype, int root) const
void Intracomm::Allgather(const void* sendbuf, int sendcount,
const Datatype& sendtype, void* recvbuf, int recvcount,
const Datatype& recvtype) const
void Intracomm::Allgatherv(const void* sendbuf, int sendcount,
const Datatype& sendtype, void* recvbuf, const int recvcounts[],
const int displs[], const Datatype& recvtype) const
void Intracomm::Alltoall(const void* sendbuf, int sendcount,
const Datatype& sendtype, void* recvbuf, int recvcount,
const Datatype& recvtype) const
void Intracomm::Alltoallv(const void* sendbuf, const int sendcounts[],
const int sdispls[], const Datatype& sendtype, void* recvbuf,
const int recvcounts[], const int rdispls[], const Datatype& recvtype) const
void Intracomm::Reduce(const void* sendbuf, void* recvbuf, int count,
const Datatype& datatype, const Op& op, int root) const
void Op::Init(User_function* function, bool commute)
void Op::Free()
void Intracomm::Allreduce(const void* sendbuf, void* recvbuf,
int count, const Datatype& datatype, const Op& op) const
void Intracomm::Reduce_scatter(const void* sendbuf, void* recvbuf,
int recvcounts[], const Datatype& datatype, const Op& op) const
void Intracomm::Scan(const void* sendbuf, void* recvbuf,
int count, const Datatype& datatype, const Op& op) const
};
B6 Привязки для групп, контекстов и коммуникаторов в языке С++
По синтаксическим и семантическим причинам функции Dup() в списке ниже не виртуальные. Синтаксически каждая из них обязана иметь различные типы возвращения.
namespace MPI {
int Group::Get_size() const
int Group::Get_rank() const
static void Group::Translate_ranks (const Group& group1, int n,
const int ranks1[], const Group& group2, int ranks2[])
static int Group::Compare(const Group& group1, const Group& group2)
Group Comm::Get_group() const
static Group Group::Union(const Group& group1, const Group& group2)
static Group Group::Intersect(const Group& group1, const Group& group2)
static Group Group::Difference(const Group& group1, const Group& group2)
Group Group::Incl(int n, const int ranks[]) const
Group Group::Excl(int n, const int ranks[]) const
Group Group::Range_incl(int n, const int ranges[][3]) const
Group Group::Range_excl(int n, const int ranges[][3]) const
void Group::Free()
int Comm::Get_size() const
int Comm::Get_rank() const
static int Comm::Compare(const Comm& comm1, const Comm& comm2)
Intracomm Intracomm::Dup() const
Intercomm Intercomm::Dup() const
Cartcomm Cartcomm::Dup() const
Graphcomm Graphcomm::Dup() const
Comm& Comm::Clone() const = 0
Intracomm& Intracomm::Clone() const
Intercomm& Intercomm::Clone() const
Cartcomm& Cartcomm::Clone() const
Graphcomm& Graphcomm::Clone() const
Intracomm Intracomm::Create(const Group& group) const
Intracomm Intracomm::Split(int color, int key) const
void Comm::Free()
bool Comm::Is_inter() const
int Intercomm::Get_remote_size() const
Group Intercomm::Get_remote_group() const
Intercomm Intracomm::Create_intercomm(int local_leader,
const Comm& peer_comm, int remote_leader, int tag) const
Intracomm Intercomm::Merge(bool high) const
};
B7 Привязки для топологий процессов в языке С++
namespace MPI {
Cartcomm Intracomm::Create_cart(int ndims, const int dims[],
const bool periods[], bool reorder) const
void Compute_dims(int nnodes, int ndims, int dims[])
Graphcomm Intracomm::Create_graph(int nnodes, const int index[],
const int edges[], bool reorder) const
int Comm::Get_topology() const
void Graphcomm::Get_dims(int nnodes[], int nedges[]) const
void Graphcomm::Get_topo(int maxindex, int maxedges, int index[],
int edges[]) const
int Cartcomm::Get_dim() const
void Cartcomm::Get_topo(int maxdims, int dims[], bool periods[], int coords[])
const
int Cartcomm::Get_cart_rank(const int coords[]) const
void Cartcomm::Get_coords(int rank, int maxdims, int coords[]) const
int Graphcomm::Get_neighbors_count(int rank) const
void Graphcomm::Get_neighbors(int rank, int maxneighbors, int neighbors[]) const
void Cartcomm::Shift(int direction, int disp, int& rank_source, int& rank_dest)
const
Cartcomm Cartcomm::Sub(const bool remain_dims[]) const
int Cartcomm::Map(int ndims, const int dims[], const bool periods[]) const
int Graphcomm::Map(int nnodes, const int index[], const int edges[]) const
};
B8 Привязки для запросов среды в языке С++
namespace MPI {
void Get_processor_name(char* name, int& resultlen)
void Errhandler::Free()
void Get_error_string(int errorcode, char* name, int& resultlen)
int Get_error_class(int errorcode)
double Wtime()
double Wtick()
void Init(int& argc, char**& argv)
void Init()
void Finalize()
bool Is_initialized()
void Comm::Abort(int errorcode)
};
B9 Привязки для профилирования в языке С++
namespace MPI{
void Pcontrol(const int level, ...)
};
B10 Привязки для доступа к статусу в языке С++
namespace MPI{
int Status::Get_source() const
void Status::Set_source(int source)
int Status::Get_tag() const
void Status::Set_tag(int tag)
int Status::Get_error() const
void Status::Set_error(int error)
};
B11 Привязки для новых функций MPI 1.2 в языке С++
namespace MPI{
void Get_version(int& version, int& subversion);
};
B12 Привязки для исключений в языке С++
namespace MPI{
Exception::Exception(int error_code);
int Exception::Get_error_code() const;
int Exception::Get_error_class() const;
const char* Exception::Get_error_string() const;
};
B13 Привязки для всех MPI классов в языке С++
Язык С++ требует, чтобы классы имели четыре специальные функции: конструктор, функцию копирования, деструктор и оператор присваивания. Привязки для этих функций представлены ниже. Два конструктора не являются виртуальными.
B13.1 Создание/Удаление
namespace MPI {
<CLASS>::<CLASS>()
<CLASS>::~<CLASS>()
};
B13.2 Копирование/присваивание
namespace MPI {
<CLASS>::<CLASS>(const <CLASS>& data)
<CLASS>& <CLASS>::operator=(const <CLASS>& data)
};
B13.3 Сравнение
Поскольку экземпляры статуса не являются дескрипторами
для функций более низкого уровня, функции
operator==() и operator!=() не определены как статусный класс.
namespace MPI {
bool <CLASS>::operator==(const <CLASS>& data) const
bool <CLASS>::operator!=(const <CLASS>& data) const
};
B13.4 Межязыковое взаимодействие
Поскольку не имеется никаких С++ объектов MPI::STATUS_IGNORE и
МPI::STATUSES_IGNORE, результат продвижения Си или ФОРТРАН дескрипторов (MPI_STATUS_IGNORE and MPI_STATUSES_IGNORE) является
неопределенным .
namespace MPI {
<CLASS>& <CLASS>::operator=(const MPI_<CLASS>& data)
<CLASS>::<CLASS>(const MPI_<CLASS>& data)
<CLASS>::operator MPI_<CLASS>() const
};
B13.5 Перекрестные ссылки для названий функций
Поскольку некоторые привязки в языке С++ слегка отличаются по названию от соответствующих привязок в языках Си и ФОРТРАН в этом разделе каждое нейтральное по отношению к языку имя сопоставляется c привязкой для С++.
Для краткости префикс ``MPI::'' предполагается для всех имен классов.
Для устаревших имен используется слово <нет> в графе "Имя", чтобы указать, что эта функция реализована с новым именем.
Если в графе "Возвращаемое значение" указано значение не void, данное имя соответствует параметру в языковонейтральном описании.
Таблицы ссылок представлены на следующих страницах.
=
table
tabular
|p170pt|p50pt|p90pt|p90pt|
| MPI Функция | C++ класс | Имя | Возвращаемое значение |
|---|---|---|---|
| MPI_ERROR_CLASS | Get_error_class | int errorclass | |
| MPI_ERROR_STRING | Get_error_string | void | |
| MPI_FINALIZE | Finalize | void | |
| MPI_GATHERV | Intracomm | Gatherv | void |
| MPI_GATHER | Intracomm | Gather | void |
| MPI_GET_COUNT | Status | Get_count | int count |
| MPI_GET_ELEMENTS | Status | Get_elements | int count |
| MPI_GET_PROCESSOR_NAME | Get_processor_name | void | |
| MPI_GRAPHDIMS_GET | Graphcomm | Get_dims | void |
| MPI_GRAPH_CREATE | Intracomm | Create_graph | Graphcomm newcomm |
| MPI_GRAPH_GET | Graphcomm | Get_topo | void |
| MPI_GRAPH_MAP | Graphcomm | Map | int newrank |
| MPI_GRAPH_NEIGHBORS_COUNT | Graphcomm | Get_neighbors_count | int nneighbors |
| MPI_GRAPH_NEIGHBORS | Graphcomm | Get_neighbors | void |
| MPI_GROUP_COMPARE | Group | static Compare | int result |
| MPI_GROUP_DIFFERENCE | Group | static Difference | Group newgroup |
| MPI_GROUP_EXCL | Group | Excl | Group newgroup |
| MPI_GROUP_FREE | Group | Free | void |
| MPI_GROUP_INCL | Group | Incl | Group newgroup |
| MPI_GROUP_INTERSECTION | Group | static Intersect | Group newgroup |
| MPI_GROUP_RANGE_EXCL | Group | Range_excl | Group newgroup |
| MPI_GROUP_RANGE_INCL | Group | Range_incl | Group newgroup |
| MPI_GROUP_RANK | Group | Get_rank | int rank |
| MPI_GROUP_SIZE | Group | Get_size | int size |
| MPI_GROUP_TRANSLATE_RANKS | Group | static Translate_ranks | void |
| MPI_GROUP_UNION | Group | static Union | Group newgroup |
| MPI_IBSEND | Comm | Ibsend | Request request |
| MPI_INITIALIZED | Is_initialized | bool flag | |
| MPI_INIT | Init | void | |
| MPI_INTERCOMM_CREATE | Intracomm | Create_intercomm | Intercomm newcomm |
| MPI_INTERCOMM_MERGE | Intercomm | Merge | Intracomm newcomm |
| MPI_IPROBE | Comm | Iprobe | bool flag |
| MPI_IRECV | Comm | Irecv | Request request |
| MPI_IRSEND | Comm | Irsend | Request request |
| MPI_ISEND | Comm | Isend | Request request |
| MPI_ISSEND | Comm | Issend | Request request |
| MPI_KEYVAL_CREATE | <нет> | ||
| MPI_KEYVAL_FREE | <нет> | ||
| MPI_OP_CREATE | Op | Init | void |
| MPI_OP_FREE | Op | Free | void |
| MPI_PACK_SIZE | Datatype | Pack_size | int size |
| MPI_PACK | Datatype | Pack | void |
| MPI_PCONTROL | Pcontrol | void | |
| MPI_PROBE | Comm | Probe | void |
| MPI_RECV_INIT | Comm | Recv_init | Prequest request |
| MPI_RECV | Comm | Recv | void |
| MPI_REDUCE_SCATTER | Intracomm | Reduce_scatter | void |
| MPI_REDUCE | Intracomm | Reduce | void |
| MPI_REQUEST_FREE | Request | Free | void |
| MPI Функция | C++ класс | Имя | Возвращаемое значение |
|---|---|---|---|
| MPI_RSEND_INIT | Comm | Rsend_init | Prequest request |
| MPI_RSEND | Comm | Rsend | void |
| MPI_SCAN | Intracomm | Scan | void |
| MPI_SCATTERV | Intracomm | Scatterv | void |
| MPI_SCATTER | Intracomm | Scatter | void |
| MPI_SENDRECV_REPLACE | Comm | Sendrecv_replace | void |
| MPI_SENDRECV | Comm | Sendrecv | void |
| MPI_SEND_INIT | Comm | Send_init | Prequest request |
| MPI_SEND | Comm | Send | void |
| MPI_SSEND_INIT | Comm | Ssend_init | Prequest request |
| MPI_SSEND | Comm | Ssend | void |
| MPI_STARTALL | Prequest | static Startall | void |
| MPI_START | Prequest | Start | void |
| MPI_TESTALL | Request | static Testall | bool flag |
| MPI_TESTANY | Request | static Testany | bool flag |
| MPI_TESTSOME | Request | static Testsome | int outcount |
| MPI_TEST_CANCELLED | Status | Is_cancelled | bool flag |
| MPI_TEST | Request | Test | bool flag |
| MPI_TOPO_TEST | Comm | Get_topo | int status |
| MPI_TYPE_COMMIT | Datatype | Commit | void |
| MPI_TYPE_CONTIGUOUS | Datatype | Create_contiguous | Datatype |
| MPI_TYPE_EXTENT | <нет> | ||
| MPI_TYPE_FREE | Datatype | Free | void |
| MPI_TYPE_HINDEXED | <нет> | ||
| MPI_TYPE_HVECTOR | <нет> | ||
| MPI_TYPE_INDEXED | Datatype | Create_indexed | Datatype |
| MPI_TYPE_LB | <нет> | ||
| MPI_TYPE_SIZE | Datatype | Get_size | int |
| MPI_TYPE_STRUCT | <нет> | ||
| MPI_TYPE_UB | <нет> | ||
| MPI_TYPE_VECTOR | Datatype | Create_vector | Datatype |
| MPI_UNPACK | Datatype | Unpack | void |
| MPI_WAITALL | Request | static Waitall | void |
| MPI_WAITANY | Request | static Waitany | int index |
| MPI_WAITSOME | Request | static Waitsome | int outcount |
| MPI_WAIT | Request | Wait | void |
| MPI_WTICK | Wtick | double wtick | |
| MPI_WTIME | Wtime | double wtime |
Этот раздел содержит уточнения и небольшую коррекцию версии стандарта MPI-1.1. Единственная новая функцияв в MPI-1.2 - это функция, указывающая, какая версия стандарта используется. Между MPI-1 и MPI-1.1 имеются небольшие различия. Между MPI-1.1 и MPI-1.2 имеются очень небольшие различия (только те, которые обсуждены в этом разделе), но разница между MPI-1.1 и MPI-1.2 принципиальная.
С1. Номер версии
Номер версии стандарта можно определить как на этапе компиляции, так и во время исполнения программы. ``Версия'' представляется двумя целыми величинами - для версии и подверсии:
В Си и С++:
# define MPI_VERSION 1 # define MPI_SUBVERSION 2
в языке ФОРТРАН:
INTEGER MPI_VERSION, MPI_SUBVERSION PARAMETER (MPI_VERSION = 1) PARAMETER (MPI\_SUBVERSION = 2)
Для вызова во время исполнения используется функция MPI_GET_VERSION, синтаксис которой представлен ниже.
MPI_GET_VERSION(version, subversion)
| OUT | version | номер версии (целое) | |
| OUT | subversion | номер подверсии (целое) |
int MPI_Get_version(int *version, int *subversion) MPI_GET_VERSION(VERSION, SUBVERSION, IERROR) INTEGER VERSION, SUBVERSION, IERROR
MPI_GET_VERSION - одна из немногих функций, которая может быть вызвана перед MPI_INIT и после MPI_FINALIZE.
Привязки для С++ можно найти в приложении В
С2 Уточнения для MPI-1.0 и MPI-1.1
На основе опыта использования версий MPI-1.0 и MPI-1.1 MPI Forum предлагает уточнения для некоторых функций, в дальнейшем эти функции должны использоваться в соответствии с этими уточнениями.
С2.1 Уточнения для MPI_INITIALIZED
MPI_INITIALIZED возвращает true, если вызывающий процесс обращался к MPI_INIT. На поведение MPI_INITIALIZED не влияет тот факт, был ли уже вызван MPI_FINALIZE или нет.
С2.2 Уточнение MPI_FINALIZE
Эта процедура очищает все состояния MPI. Каждый процесс обязан вызвать MPI_FINALIZE перед своим выходом . Если не была вызвана функция MPI_ABORT, каждый процесс должен завершить все неблокирующие ждущие обмены до обращения к MPI_FINALIZE. Более того, на момент обращения к MPI_FINALIZE для всех ждущих посылок должен быть установлен соответствующий прием, и для всех ждущих приемов должна быть установлена соответствующая посылка. Например, следующая программа является корректной:
Process 0 Process 1
--------- ---------
MPI_Init(); MPI_Init();
MPI_Send(dest=1); MPI_Recv(src=0);
MPI_Finalize(); MPI_Finalize();
Без установления соответствующего приема программа неверна:
Process 0 Process 1
----------- -----------
MPI_Init(); MPI_Init();
MPI_Send (dest=1);
MPI_Finalize(); MPI_Finalize();
Успешное возвращение из операции блокирующего обмена или из MPI_WAIT или MPI_TEST говорит пользователю, что буфер может использоваться повторно, и означает, что операция завершена пользователем, но не гарантирует, что вся работа в локальном процессе завершена. Успешное возвращение из MPI_REQUEST_FREE с дескриптором запроса, сгенерированным MPI_ISEND, обнуляет дескриптор, но не дает гарантии, что операция завершена. MPI_ISEND завершается только тогда, когда он узнает некоторым способом, что соответствующий прием завершен.
MPI_FINALIZE гарантирует, что все локальные действия, необходимые для обменов, которые пользователь уже завершил, будут иметь место в действительности перед его возвратом.
MPI_FINALIZE не гарантирует ничего относительно ждущих обменов, которые еще не завершены (завершение гарантируется только MPI_WAIT, MPI_TEST, или MPI_REQUEST_FREE совместно с некоторыми другими проверками завершения).
Эта программа верна:
rank 0 rank 1 ===================================================== ... ... MPI_Isend(); MPI_Recv(); MPI_Request_free(); MPI_Barrier(); MPI_Barrier(); MPI_Finalize(); MPI_Finalize(); exit(); exit();
Эта программа неверна и ее поведение является неопределенным:
rank 0 rank 1 ===================================================== ... ... MPI_Isend(); MPI_Recv(); MPI_Request_free(); MPI_Finalize(); MPI_Finalize(); exit(); exit();
Если между MPI_BSEND (или другой буферизованной посылки) и MPI_FINALIZE нет операции MPI_BUFFER_DETACH, MPI_FINALIZE неявно обеспечивает MPI_BUFFER_DETACH.
Нижеследующая программа правильная и после MPI_Finalize все выполняется так, как если бы буфер был подключен:
rank 0 rank 1 ===================================================== ... ... buffer = malloc(1000000); MPI_Recv(); MPI_Buffer_attach(); MPI_Finalize(); MPI_Bsend(); exit(); MPI_Finalize(); free(buffer); exit();
В следующем примере MPI_Iprobe() должен возвратить флаг FALSE. MPI_Test_cancelled() обязан возвратить флаг TRUE, независимо от относительного порядка выполнения MPI_Cancel() в процессе 0 и MPI_Finalize() в процессе 1. Вызов MPI_Iprobe() необходим для создания уверенности, что реализация знает о том, что сообщение ``tag1'' существует на стороне приема.
Номер 0 номер 1
========================================================
MPI_Init(); MPI_Init();
MPI_Isend(tag1);
MPI_Barrier(); MPI_Barrier();
MPI_Iprobe(tag2);
MPI_Barrier(); MPI_Barrier();
MPI_Finalize();
exit();
MPI_Cancel();
MPI_Wait();
MPI_Test_cancelled();
MPI_Finalize();
exit();
После того, как MPI_FINALIZE возвратил управление, не могут быть вызваны никакие процедуры MPI (даже MPI_INIT), исключая MPI_GET_VERSION, MPI_INITIALIZED, и MPI-2 функция MPI_FINALIZED. Каждый процесс обязан завершить все ждущие коммуникации, которые он инициировал, до того, как он вызовет MPI_FINALIZE. Если вызов возвращает управление, каждый процесс может продолжать локальные вычисления или осуществить выход, без участия в дальнейших MPI обменах с другими процесами. MPI_FINALIZE является коллективной операцией на коммуникаторе MPI_COMM_WORLD.
Совет разработчикам: Хотя процесс завершил все инициированные коммуникации, такие коммуникации все еще могут быть не завершены с точки зрения более низкого системного уровня MPI. Например, блокирующая посылка может быть уже завершена, хотя данные все еще буферизованы на процессе-отправителе. Реализация MPI обязана гарантировать, что процесс завершает любую инициированную коммуникацию перед возвращением MPI_FINALIZE. Поэтому, если процесс существует после вызова MPI_FINALIZE, это не будет вызывать отказа продолжающегося обмена.
Не требуется, чтобы все процессы возвращали управление из
MPI_FINALIZE, однако необходимо, чтобы по крайней мере процесс
0 в MPI_COMM_WORLD возвратил управление, чтобы
пользователь знал о том, что порция вычислений завершена.
Следующий пример иллюстрирует требование, чтобы по крайней мере один
процесс возвращал управление и чтобы было известно, что процесс 0 -
один из таких процессов.
...
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
...
MPI_Finalize();
if (myrank == 0) {
resultfile = fopen("outfile","w");
dump_results(resultfile);
fclose(resultfile);
}
exit(0);
С2.3 Уточнение статуса после MPI_WAIT и MPI_TEST
Поля в статусном объекте, возвращенные вызовами MPI_WAIT, MPI_TEST или любыми другими производными функциями (MPI_{TEST,WAIT}{ALL,SOME,ANY}), где запрос соответствует вызову посылки, являются неопределенными за двумя исключениями: поле ошибки статусного объекта будет содержать правильную информацию, если вызов wait или test возвратил MPI_ERR_IN_STATUS; и возвращенный статус может быть запрошен вызовом MPI_TEST_CANCELLED.
Коды ошибок, принадлежащие классу MPI_ERR_IN_STATUS, должны быть возвращены только завершающей функцией MPI, которая использует массивы MPI_STATUS. Для функций ( MPI_TEST, MPI_TESTANY, MPI_WAIT, MPI_WAITANY), которые возвращают единственное значение MPI_STATUS, должен быть использован нормальный процесс возврата ошибки ( а не поле MPI_ERROR в аргументе MPI_STATUS).
С2.4 Уточнение MPI_INTERCOMM_CREATE
Проблема : стандарт MPI-1 говорит в дискуссии о MPI_INTERCOMM_CREATE, что: ``Группы должны быть разъединены'' и что ``Лидером может быть тот же самый процесс''.
Причиной требования ``Группы должны быть разъединены'' является озабоченность реализацией MPI_INTERCOMM_CREATE, которая не применима в случае, когда лидером является тот же самый процесс.
Принято: удалить текст: ``(два лидера могут быть тем же самым процессом)'' из дискуссии о MPI_INTERCOMM_CREATE.
Заменить текст ``Все конструкторы интер-коммуникаторов являются блокирующими и требуют, чтобы локальные и удаленные группы были разъединены в таком порядке, чтобы избежать дедлока'' текстом ``Все конструкторы интер-коммуникаторов являются блокирующими и требуют, чтобы локальные и удаленные группы были разъединены''.
Совет пользователям: Группы должны быть разъединены по нескольким причинам. Прежде всего, это цель интер-коммуникаторов - обеспечить коммуникатор для обмена между разъединенными группами. Это отражено в определении MPI_INTERCOMM_MERGE, который позволяет пользователю управлять нумерацией процессов в созданном интер-коммуникаторе; эта нумерация имеет мало смысла, если группы не разъединены. К тому же, естественное расширение на коллективные операции для интер-коммуникаторов имеет наибольший смысл, когда группы разъединены.
С2.5 Уточнение MPI_INTERCOMM_MERGE
Обработчик ошибок в новом интер-коммуникаторе в каждом процессе наследуется из коммуникатора, который создала локальная группа. Заметим, что это может выразиться в том, что различные процессы одного и того же коммуникатора имеют различные обработчики ошибок.
С.2.6. Уточнение привязок MPI_TYPE_SIZE
Это уточнение необходимо для описания MPI_TYPE_SIZE в MPI-1, поскольку проблема возникает многократно. Это уточнение привязки.
Совет пользователям: Стандарт MPI-1 указывает, что выходной аргумент MPI_TYPE_SIZE в Си имеет тип int. MPI Forum рассмотрел предложение изменить это и решил оставить исходное решение.
С2.7. Уточнение MPI_REDUCE
Текст на стр. 115, строки 25 - 28 стандарта MPI-1.1 (12, июнь, 1995) говорит:
``Аргумент типа данных MPI_REDUCE обязан быть совместим с типом ор. Предопределенные операторы работают только с типами данных из списка, представленного в разделах 4.9.2 и 4.9.3. Операторы, определенные пользователем, могут работать с производными типами данных''.
Этот текст заменен на:
``Аргумент типа данных MPI_REDUCE обязан быть совместим с типом ор. Предопределенные опраторы работают только с типами данных из списка, представленного в разделах 4.9.2 и 4.9.3. Более того, типы данных и ор, данные для предопределенных операторов, обязаны быть одними и теми же на всех процессах''.
Заметим, что пользователь имеет возможность создавать различные определенные пользователем операции в каждом процессе. MPI не определяет, какие операции и с какими операндами используются в этом случае.
Совет пользователям: Пользователи не должны делать никаких
предположений о том, как реализован MPI_REDUCE. Защита должна
гарантировать, что та же самая функция передается в MPI_REDUCE
каждым процессом.
Перекрывающиеся типы данных разрешены в буферах посылки. Перекрывающиеся типы данных в буферах приема ошибочны и могут давать непредсказуемый результат.
С2.8. Уточнение поведения функции Attribute Callback при ошибках
Если функция копирования или удаления атрибута возвращает что-либо, отличное от MPI_SUCCESS, то обращение, которое вызвало эту ситуацию (например, MPI_COMM_FREE), является неверным.
С2.9. Уточнение MPI_PROBE и MPI_IPROBE
Страница 52, строки 1 -3 MPI-1.1 (12, июнь, 1995) устанавливает, что:
``Последующий прием, выполненный с тем же самым коммуникатором, номером процесса-отправителя и тэгом, возвращенным в статус функцией MPI_IPROBE, будет принимать сообщение, которое соответствует пробе, если не имело места никакое другое пересекающееся сообщение после пробы, и посылка не была успешно отменена перед приемом''.
Объяснение: Следующая программа показывает, что определения MPI-1 для отмены и пробы конфликтуют:
Процесс 0 Процесс 1
---------- ----------
MPI_Init(); MPI_Init();
MPI_Isend(dest=1);
MPI_Probe();
MPI_Barrier(); MPI_Barrier();
MPI_Cancel();
MPI_Wait();
MPI_Test_cancelled();
MPI_Barrier(); MPI_Barrier();
MPI_Recv();
Поскольку посылка была отменена процессом 0, ожидание обязано быть локальным (страница 54, строка 13) и обязано возвращать управление перед соответствующим приемом. Чтобы ожидание было локальным, посылка должна быть успешно отменена и поэтому не обязана соответствовать приему в процессе 1 (страница 54, строка 29).
Однако, ясно, что проба на процессе 1 обязана в конечном счете детектировать входное сообщение. На странице 52 в строке 1 ясно говорится, что последующий прием процессом 1 обязан возвратить опробованное сообщение.
Выше выявлено противоречие и поэтому текст ``...и отправка не завершена успешно перед приемом'' обязан быть добавленным к строке 3 на странице 54.
Альтернативное решение (отброшенное) потребовало бы изменения семантики отмены, так как вызов не является локальным, если сообщение уже опробовано. Это увеличивает сложность реализации и добавляет новую концепцию ``состояния'' к сообщению (опробовано или нет). Однако, это сохранило бы ту особенность, что блокирующий прием после пробы является локальным.
=2cm
MPI_ABORT(comm, errorcode )
Прекращает выполнение операций
MPI_ADDRESS(location, address)
Устарела, вместо нее используется MPI_GET_ADDRESS
MPI_ALLGATHER(sendbuf, sendcount, sendtype, recvbuf, recvcount, recvtype, comm)
Собирает данные от всех процессов и распределяет их всем процессам
MPI_ALLGATHERV(sendbuf, sendcount, sendtype, recvbuf, recvcounts, displs, recvtype, comm)
Собирает данные от всех процессов и поставляет их всем процессам
MPI_ALLREDUCE(sendbuf, recvbuf, count, datatype, op, comm)
Выполняет глобальную операцию над данными от всех процессов и результат посылает обратно всем процессам
MPI_ALLTOALL(sendbuf, sendcount, sendtype, recvbuf, recvcount, recvtype, comm)
Посылает данные от всех процессов всем процессам
MPI_ALLTOALLV (sendbuf, sendcounts, sdispls, sendtype, recvbuf, recvcounts, rdispls, recvtype, comm)
Посылает данные от всех процессов всем процессам со смещением
MPI_ATTR_DELETE (comm, keyval)
Удаляет связанное с ключем значение.
Устарела, вместо нее используется MPI_COMM_DELETE_ATTR
MPI_ATTR_GET(comm, keyval, attribute_val, flag)
Обрабатывает значение атрибута по ключу
Устарела, вместо нее используется MPI_COMM_GET_ATTR
MPI_ATTR_PUT(comm, keyval, attribute_val)
Хранит связанное с ключом значение атрибута
Устарела, вместо нее используется MPI_COMM_ SET_ATTR
MPI_BARRIER ( comm )
Блокирует дальнейшее исполнение, пока все процессы не достигнут этой функции
MPI_BCAST( buffer, count, datatype, root, comm )
Широковещательная рассылка сообщения от одного процесса всем
MPI_BSEND (buf, count, datatype, dest, tag, comm)
Основная операция посылки сообщения с определенным пользователем буфером
MPI_BSEND_INIT (buf, count, datatype, dest, tag, comm, request)
![]() дескриптор для буферизованной посылки
дескриптор для буферизованной посылки
MPI_BUFFER_ATTACH ( buffer, size)
Создает определяемый пользователем буфер для посылки
MPI_BUFFER_DETACH ( buffer_addr, size)
Удаляет существующий буфер
MPI_CANCEL (request)
Отменяет коммуникационный запрос
MPI_CART_COORDS (comm, rank, maxdims, coords)
Определяет координаты процесса в картезианской топологии в соответствии с его номером
MPI_CART_CREATE (comm_old, ndims, dims, periods, reorder, comm_cart)
Создает новый коммуникатор по заданной топологической информации
MPI_CART_GET (comm, maxdims, dims, periods, coords)
Получает связанную с коммуникатором информацию о картезианской топологии
MPI_CART_MAP (comm, ndims, dims, periods, newrank)
Отображает процесс в соответствии с топологической информацией
MPI_CART_RANK (comm, coords, rank)
Определяет номер процесса в коммуникаторе с картезианской топологией
MPI_CART_SHIFT (comm, direction, disp, rank_source, rank_dest)
Возвращает новые номера процессов отправителя и получателя после сдвига в заданном направлении
MPI_CART_SUB (comm, remain_dims, newcomm)
Разделяет коммуникатор на подгруппы, которые формируют картезианские решетки меньшей размерности
MPI_CARTDIM_GET (comm, ndims)
Получает информацию о связанной с коммуникатором картезианской топологии
MPI_COMM_COMPARE (comm1, comm2, result)
Сравнивает два коммуникатора
MPI_COMM_CREATE (comm, group, newcomm)
Создает новый коммуникатор
MPI_COMM_CREATE_ERRHANDLER (function, errhandler)
MPI-2:создает обработчик ошибок в стиле MPI
MPI_COMM_CREATE_KEYVAL (Comm_copy_attr_fn, comm_delete_attr_fn, comm_keyval, extra_state)
MPI-2: генерирует новый ключ атрибута
MPI_COMM_DELETE_ATTR (comm,comm_keyval)
MPI-2: удаляет связанное с ключом значение атрибута
MPI_COMM_DUP (comm, newcomm)
Создает новый коммуникатор путем дублирования существующего со всеми его параметрами
MPI_COMM_FREE (comm)
Маркирует коммуникатор для удаления
MPI_COMM_FREE_KEYVAL (comm_keyval)
MPI-2:освобождает ключ атрибута
MPI_COMM_GET_ATTR (comm,comm_keyval, attribute, flag)
MPI-2: получает значение атрибута по ключу
MPI_COMM_GET_ERRHANDLER (comm, errhandler)
MPI-2:Получает обработчик ошибок для коммуникатора
MPI_COMM_GROUP (comm, group)
Осуществляет доступ к группе, связанной с данным коммуникатором
MPI_COMM_RANK (comm, rank)
Определяет номер процесса в коммуникаторе
MPI_COMM_REMOTE_GROUP (comm, group)
Возвращает удаленную группу в коммуникатор
MPI_COMM_REMOTE_SIZE (comm, size)
Возвращает номер процесса в удаленной группе
MPI_COMM_SET_ATTR (comm, comm_keyval, attribute_val)
Запоминает связанное с ключом значение атрибута
MPI_COMM_SET_ERRHANDLER (comm, errhandler)
MPI-2: устанавливает обработчик ошибок для коммуникатора
MPI_COMM_SIZE (comm, size)
Определяет размер связанной с коммуникатором группы
MPI_COMM_SPLIT (comm, color, key, newcomm)
Создает новый коммуникатор на основе признаков и ключей
MPI_COMM_TEST_INTER (comm, flag)
Проверяет, является ли данный коммуникатор интеркоммуникатором
MPI_DIMS_CREATE (nnodes, ndims, dims)
Распределяет процессы по размерностям
MPI_ERRHANDLER_CREATE ( function, errhandler )
Создает обработчик ошибок в стиле MPI
Устарела, вместо нее используется MPI_COMM_CREATE_ERRHANDLER
MPI_ERRHANDLER_FREE ( errhandler )
Освобождает обработчик ошибок в стиле MPI
MPI_ERRHANDLER_GET ( comm, errhandler )
Создает обработчик ошибок для коммуникатора
MPI_ERRHANDLER_SET ( comm, errhandler )
Устанавливает обработчик ошибок для коммуникатора
Устарела,вместо нее используется MPI_COMM_SET_ERRHANDLER
MPI_ERROR_CLASS ( errorcode, errorclass )
Преобразует код ошибки в класс ошибки
MPI_ERROR_STRING ( errorcode, string, resultlen )
Возвращает строку для кода данной ошибки
MPI_FINALIZE ( )
Завершает выполнение программы MPI
MPI_ GATHER ( sendbuf, sendcount, sendtype, recvbuf, recvcount, recvtype, root, comm)
Собирает в один процесс данные от группы процессов
MPI_GATHERV ( sendbuf, sendcount, sendtype, recvbuf, recvcounts, displs, recvtype, root, comm)
Векторный вариант функции GATHER
MPI_GET_ADRESS (location, address)
MPI-2: получает адрес ячейки в памяти
MPI_GET_COUNT (status, datatype, count)
Получает номер старших элементов
MPI_GET_ELEMENTS ( status, datatype, count)
Возвращает номер базового элемента в типе данных
MPI_GET_PROCESSOR_NAME ( name, resultlen )
Получает номер процессора
MPI_GET_VERSION (version, subversion)
Возвращает версию MPI
MPI_GRAPH_CREATE (comm_old, nnodes, index, edges, reorder, comm_graph)
Создает новый коммуникатор согласно топологической информации
MPI_GRAPH_GET(comm, maxindex, maxedges, index, edges)
Получает информацию о связанной с коммуникатором графовой топологии.
MPI_GRAPH_MAP (comm, nnodes, index, edges, newrank)
Размещает процесс согласно информации о топологии графа
MPI_GRAPH_NEIGHBORS_COUNT(comm, rank, nneighbors)
Возвращает число соседей узла в графовой топологии
MPI_GRAPH_NEIGHBORS (comm, rank, maxneighbors, neighbors)
Возвращает соседей узла в графовой топологии
MPI_GRAPHDIMS_GET (comm, nnodes, nedges)
Получает информацию о связанной с коммуникатором топологии
MPI_GROUP_COMPARE (group1, group2, result)
Сравнивает две группы
MPI_GROUP_DIFFERENCE (group1, group2, newgroup)
Создает группу по разности двух групп
MPI_GROUP_EXCL (group, n, ranks, newgroup)
Создает группу путем переупорядочивания существующей группы и отбора только тех элементов, которые не указаны в списке
MPI_GROUP_FREE (group)
Освобождает группу
MPI_GROUP_INCL (group, n, ranks, newgroup)
Создает группу путем переупорядочивания существующей группы и отбора только тех элементов,
которые указаны в списке
MPI_GROUP_INTERSECTION (group1, group2, newgroup)
Создает группу на основе пересечения двух групп
MPI_GROUP_RANGE_EXCL (group, n, ranges, newgroup)
Создает группу путем исключения ряда процессов из существующей группы
MPI_GROUP_RANGE_INCL (group, n, ranges, newgroup)
Создает новую группу из ряда номеров существующей группы
MPI_GROUP_RANK (group, rank)
Возвращает номер процесса в данной группе
MPI_GROUP_SIZE (group, size)
Возвращает размер группы
MPI_GROUP_TRANSLATE_RANKS (group1, n, ranks1, group2, ranks2)
Переводит номер процесса в одной группе в номер в другой группе
MPI_GROUP_UNION(group1, group2, newgroup)
Создает новую группу путем объединения двух групп
MPI_IBSEND (buf, count, datatype, dest, tag, comm, request)
Запускает неблокирующую буферизованную посылку
MPI_INIT ( )
Инициализация параллельных вычислений
MPI_INITIALIZED ( flag )
Указывает, был ли выполнен MPI_INIT
MPI_INTERCOMM_CREATE (local_comm, local_leader, peer_comm, remote_leader, tag, newintercomm)
Создает интеркоммуникатор из двух интракоммуникаторов
MPI_INTERCOMM_MERGE (intercomm, high, newintracomm)
Создает интракоммуникатор из интеркоммуникатора
MPI_IPROBE (source, tag, comm, flag, status)
Неблокирующий тест сообщения
MPI_IRECV (buf, count, datatype, source, tag, comm, request)
Начинает неблокирующий прием
MPI_IRSEND (buf, count, datatype, dest, tag, comm, request)
Запускает неблокирующую посылку по готовности
MPI_ISEND (buf, count, datatype, dest, tag, comm, request)
Запускает неблокирующую посылку
MPI_ISSEND (buf, count, datatype, dest, tag, comm, request)
Запускает неблокирующую синхронную передачу
MPI_KEYVAL_CREATE (copy_fn, delete_fn, keyval, extra_state)
Генерирует новый ключ атрибута
Устарела, вместо нее используется MPI_COMM_CREATE_KEYVAL
MPI_KEYVAL_FREE (keyval)
Освобождает ключ атрибута
Устарела, вместо нее используется MPI_COMM_FREE_KEYVAL
MPI_OP_CREATE ( function, commute, op)
Создает определенный пользователем дескриптор функции
MPI_OP_FREE ( op)
Освобождает определенный пользователем дескриптор функции
MPI_PACK (inbuf, incount, datatype, outbuf, outsize, position, comm)
Упаковывает данные в непрерывный буфер
MPI_PACK_SIZE (incount, datatype, comm, size)
Возвращает размер, необходимый для упаковки типа данных
MPI_PCONTROL (level, ...)
Управляет профилированием
MPI_PROBE (source, tag, comm, status)
Блокирующий тест сообщения
MPI_RECV (buf, count, datatype, source, tag, comm, status)
Основная операция приема
MPI_RECV_INIT(buf, count, datatype, source, tag, comm, request)
Создает дескриптор для приема
MPI_REDUCE ( sendbuf, recvbuf, count, datatype, op, root, comm)
Выполняет глобальную операцию над значениями всех процессов и возвращает результат в один процесс
MPI_REDUCE_SCATTER ( sendbuf, recvbuf, recvcounts, datatype, op, comm)
Выполняет редукцию и рассылает результаты
MPI_REQUEST_FREE (request)
Освобождает объект коммуникационного запроса
MPI_RSEND (buf, count, datatype, dest, tag, comm)
Операция посылки по готовности
MPI_RSEND_INIT (buf, count, datatype, dest, tag, comm, request)
Создает дескриптор для посылки по готовности
MPI_SCAN ( sendbuf, recvbuf, count, datatype, op, comm )
Вычисляет частичную редукцию данных на совокупности процессов
MPI_SCATTER ( sendbuf, sendcount, sendtype, recvbuf, recvcount, recvtype, root,comm)
Рассылает содержимое буфера одного процесса всем процессам в группе
MPI_SCATTERV( sendbuf, sendcounts, displs, sendtype, recvbuf, recvcount, recvtype, root, comm)
Рассылает части буфера одного процесса всем процессам в группе
MPI_SEND (buf, count, datatype, dest, tag, comm)
Основная операция посылки
MPI_SEND_INIT (buf, count, datatype, dest, tag, comm, request)
Создает дескриптор для стандартной посылки
MPI_SENDRECV (sendbuf, sendcount, sendtype, dest, sendtag, recvbuf, recvcount, recvtype, source, recvtag, comm, status)
Посылает и принимает сообщение
MPI_SENDRECV_REPLACE (buf, count, datatype, dest, sendtag, source, recvtag,comm, status)
Посылает и принимает сообщение, используя один буфер
MPI_SSEND (buf, count, datatype, dest, tag, comm)
Базисная синхронная передача
MPI_SSEND_INIT (buf, count, datatype, dest, tag, comm, request)
Создает дескриптор для синхронной передачи
MPI_START (request)
Инициирует обмен с персистентным дескриптором запросов
MPI_STARTALL (count, array_of_requests)
Запускает совокупность запросов
MPI_TEST(request, flag, status)
Проверяет завершение посылки или приема
MPI_TESTALL (count, array_of_requests, flag, array_of_statuses)
Проверяет завершение всех ранее начатых операций обмена
MPI_TESTANY (count, array_of_requests, index, flag, status)
Проверяет завершение любой ранее начатой операции
MPI_TESTSOME (incount, array_of_requests, outcount, array_of_indices,array_of_statuses)
Проверяет завершение заданных операций
MPI_TEST_CANCELLED (status, flag)
Проверяет отмену запроса
MPI_TOPO_TEST (comm, status)
Определяет тип связанной с коммуникатором топологии
MPI_TYPE_COMMIT(datatype)
Объявляет тип данных
MPI_TYPE_CONTIGUOUS (count, oldtype, newtype)
Создает непрерывный тип данных
MPI_TYPE_CREATE_HINDEXED (count, array_of_blocklengths_array_of_displacements, oldtype, newtype)
MPI-2: создает индексированный тип данных со смещением в байтах
MPI_TYPE_CREATE_HVECTOR (count, blocklength, stride, oldtype, newtype)
MPI-2: создает векторный тип данных со смещением в байтах
MPI_TYPE_CREATE_RESIDES (oldtype, lb, extent, newtype)
MPI-2: возвращает новый тип данных, эквивалентный старому, но с новыми границами
MPI_TYPE_CREATE_STRUCT (count, array_of_blocklehgths, array_of_displacements, array_of_types, newtype)
MPI-2: создает структурированный тип данных
MPI_TYPE_EXTENT(datatype, extent)
Создает экстент типа данных
MPI_TYPE_FREE (datatype)
Отмечает объект типа данных для удаления
MPI_TYPE_GET_EXTENT (datatype, lb, extent)
MPI-2: возвращает нижнюю границу и экстент типа данных
MPI_TYPE_HINDEXED ( count, array_of_blocklengths, array_of_displacements,oldtype, newtype)
MPI-2: создает индексированный тип данных со смещением в байтах
MPI_TYPE_HVECTOR ( count, blocklength, stride, oldtype, newtype)
MPI-2: создает векторный тип данных со смещением в байтах
MPI_TYPE_INDEXED ( count, array_of_blocklengths, array_of_displacements, oldtype, newtype)
Создает индексированный тип данных
MPI_TYPE_LB ( datatype, displacement)
Возвращает нижнюю границу типа данных
Устарела, используется MPI_TYPE_GET_EXTENT
MPI_TYPE_SIZE (datatype, size)
Возвращает число байтов, занятых элементами типа данных
MPI_TYPE_STRUCT (count, array_of_blocklengths, array_of_displacements, array_of_types, newtype)
Создает новый тип данных
Устарела, используется MPI_TYPE_CREATESTRUCT
MPI_TYPE_UB ( datatype, displacement)
Возвращает верхнюю границу типа данных
Устарела, используется MPI_TYPE_GET_EXTENT
MPI_TYPE_VECTOR ( count, blocklength, stride, oldtype, newtype)
Создает векторный тип данных
MPI_UNPACK (inbuf, insize, position, outbuf, outcount, datatype, comm)
Распаковывает данные из непрерывного буфера
MPI_WAIT (request, status)
Ожидает завершения посылки или приема
MPI_WAITALL ( count, array_of_requests, array_of_statuses)
Ожидает завершения всех обменов
MPI_WAITANY (count, array_of_requests, index, status)
Ожидает завершения любой из описанных посылки или приема
MPI_WAITSOME (incount, array_of_requests, outcount, array_of_indices, array_of_statuses)
Ожидает завершения некоторых заданных обменов
MPI_WTICK ( )
Возвращает величину разрешения при измерении времени
MPI_WTIME ( )
Возвращает полное время выполнения операций на используемом процессоре
144. MPI_COMM_NULL_COPY_FN
Возвращает flag = false и MPI_SUCCES
MPI_COMM_DUP_FN
Возвращает значение attribute_val_in в attribute_val_out и устанавливает MPI_SUCCES
MPI_COMM_NULL_DELETE_FN
Возвращает MPI_SUCCESS
MPI_Comm_copy_attr_function
Вызывается при дублировании коммуникатора
COMM_COPY_ATTR_FN
Вызывается при дублировании коммуникатора
MPI_Comm_delete_attr_function
Вызывается при удалении коммуникатора
COMM_DELETE_ATTR_FN
Вызывается при удалении коммуникатора
MPI_Comm_errhandler_fn
Возвращает код ошибки
This document was generated using the LaTeX2HTML translator Version 2002 (1.62)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html testbook.tex
The translation was initiated by Alex Otwagin on 2002-12-10
MPI управляет системной памятью, которая используется для буферизации сообщений и для хранения внутреннего представления различных объектов MPI, таких как группы, коммуникаторы, типы данных и так далее. Эта память не является для пользователя прямодоступной и объекты, хранимые здесь, являются скрытыми: их размер и форма невидимы пользователю. К скрытым объектам обращаются через дескрипторы (handles), которые существуют в пространстве пользователя. Процедуры MPI, которые оперируют на скрытых объектах, посылают аргументы дескриптора, чтобы получить доступ к этому объекту. В дополнение к их использованию вызовами MPI дескрипторы могут участвовать в операциях присваивания и сравнениях.
В языке ФОРТРАН все дескрипторы имеют тип INTEGER. В Си для каждой категории объектов определены различные типы указателей. Это должны быть типы, поддерживающие операторы присваивания и сравнения.
В языке ФОРТРАН дескриптор может быть индексом для таблицы скрытых объектов в системной таблице; в языке Си он может быть таким же индексом или указателем (pointer) на объект.
Скрытые объекты создаются и удаляются вызовами, которые специфичны для каждого объектного типа. Они находятся в списке в разделе, где описаны объекты. Вызовы получают аргумент дескриптора соответствующего типа. В вызовах создания объекта это OUT аргумент, который возвращает ссылку на объект. В вызовах для удаления это INOUT аргумент, который возвращает значение ``нулевой дескриптор '' (``null handle''). MPI обеспечивает константу ``нулевой дескриптор'' для каждого типа объекта. Чтобы проверить правильность дескриптора, используется сравнение с этой константой.
Обращение для удаления делает объект недействительным и отмечает его для удаления. После этого вызова объект становится недоступен пользователю. Однако, в MPI нет необходимости удалять объект немедленно. Любая ждущая операция (во время удаления), которая использует этот объект, будет завершаться нормально, а объект будет удален после этого.
Вызовы MPI не изменяют значения дескрипторов, за исключением вызовов, которые создают и удаляют объекты, и вызова MPI_TYPE_COMMIT, в разделе 3.12.4.
Аргумент со значением ``null handle'' и с маркировкой IN является неверным, кроме случая, когда в тексте, определяющем функцию, явно установлено исключение. Такое исключение допустимо для дескрипторов в объектах запросов при обращении к Wait и Test (разделы 3.7.3 и 3.7.5). В противном случае нулевой указатель может быть передан только функции, которая создает новый объект и возвращает ссылку на него в дескриптор.
Скрытый объект и его дескриптор существенны только в процессе, где был создан объект, и не могут быть переданы другому процессу.
В MPI предусмотрены предопределенные скрытые объекты и предопределенные статические дескрипторы этих объектов. Такие объекты не могут быть разрушены.
Объяснение: Использование в MPI скрытого представления некоторых структур данных имеет то преимущество, что позволяет сходным образом обращаться к этим структурам в языках Си и ФОРТРАН. Это также позволяет избежать конфликтов в правилах типизации для этих языков и обеспечивает будущие расширения функциональности. Механизм скрытых объектов, использованный здесь, близок к стандарту связей POSIX ФОРТРАН.
Явное отделение указателей в пользовательском пространстве от объектов в системном пространстве позволяет выполнить вызовы удаления объектов в нужной точке программы. Если бы скрытые объекты были в пространстве пользователя, тогда нужно было бы быть очень аккуратным, чтобы не выйти из области до завершения любой ждущей операции, требующей этого объекта. Система скрытых объектов позволяет объекту быть маркированным для удаления, пользовательская программа может затем выйти из области, но сам объект все еще сохраняется, пока любая ждущая операция, использующая этот объект, не завершится.[]
Совет пользователям: Пользователь может случайно создавать повисшие ссылки путем назначения дескриптору значения другого дескриптора, и затем снять с назначения объект, связанный с этим дескриптором. С другой стороны, если дескриптор удален перед освобождением связанного с ним объекта, тогда объект становится недоступным (это может иметь место, например, если дескриптор является локальной переменной подпрограммы и подпрограмма закончена перед тем, как связанный с ней объект освобождается). Пользователь должен избегать добавления или удаления ссылок на скрытые объекты, кроме случаев, когда они появляются в результате вызовов, которые создают или удаляют такой объект.[]
Совет разработчикам: Предполагаемая семантика скрытых объектов такова, что каждый скрытый объект отделен от другого; каждый вызов на размещение такого объекта копирует всю информацию, необходимую для этого объекта. В конкретных реализациях можно избежать излишнего копирования установлением ссылок для копирования. Например, производный тип данных может содержать ссылку на его компоненты, а не на копии его компонентов, вызов к MPI_COMM_GROUP может возвращать ссылку на группу, связанную с коммуникатором, а не копию этой группы. В таких случаях реализация может содержать счетчик ссылок и создавать и удалять объекты с таким же видимым эффектом, как если бы объекты были скопированы.[]
Для вызовов MPI могут понадобится аргументы, которые являются массивами скрытых объектов или массивами дескрипторов. Массив дескрипторов - это регулярный массив с элементами, которые являются дескрипторами объектов того же самого типа в последовательных ячейках массива. Когда такой массив используется, требуется дополнительный len-аргумент для указания реального числа элементов (если это число не получено другим путем). Правильные элементы находятся в начале массива; len указывает, как много их имеется и не обязательно указывает полный размер массива. Тот же подход принят для других аргументов, представленных массивами.
Процедуры MPI используют аргументы с типами состояние. Значения
данных такого типа определяются именами и на них не определено никаких
операций. Например, процедура
MPI_ERRHANDLER_SET имеет аргумент типа состояния со значением
MPI_ERRORS_ARE_FATAL, MPI_ERRORS_RETURN и так далее.
Version 1.0: May,1994. Целью MPI является создание широко используемого стандарта для написания программ для систем с обменом сообщениями. Такой интерфейс должен установить практичный, мобильный, эффективный и гибкий стандарт для обмена сообщениями. Этот документ содержит все технические особенности, предложенные для интерфейса. Этот документ был подготовлен на LaTeX 5 мая 1994 года.
Version 1.1: June, 1995. В марте 1995 года снова был созван Форум, чтобы устранить ошибки и сделать уточнения в документе MPI от 5 мая 1994 года, названном выше как Version 1.0. Эта дискуссия реализовалась в Version 1.1, которая и представлена в этом документе. Отличия от Version 1.0 незначительны.
500pt©1993, 1994, 1995 University of Tennessee, Knoxville, Tennessee. Разрешается бесплатное копирование всего или части этого материала при указании, что права копирования этого документа принадлежат Университету Tennessee, и дана ссылка, что копирование разрешено Университетом Tennessee.
Процедуры MPI иногда присваивают особый смысл специальному значению аргумента базисного типа, например, тэг (tag) есть целочисленный аргумент для операций парного обмена со специальным значением MPI_ANY_TAG. Такой аргумент будет иметь диапазон регулярных значений, который является правильным поддиапазоном значений соответствующего базового типа; специальное значение (такое как MPI_ANY_TAG) будет вне регулярного диапазона. Диапазон регулярных значений может быть упорядочен при использовании функций анализа среды (environmental inquiry) (глава 7).
MPI также обеспечивает предопределенные именованные константные дескрипторы, например, MPI_COMM_WORLD, который является дескриптором объекта, представляющего все процессы, доступные в стартовое время, и позволяет обмены с любыми из них.
Все именованные константы, за исключением MPI_BOTTOM в языке ФОРТРАН, могут быть использованы в выражениях инициализации или присваивания. Эти константы не изменяют своих значений во время исполнения. Также определены скрытые объекты, к которым обращаются с помощью константных указателей, и которые не изменяют свое значение между инициализацией MPI (MPI_INIT()) и завершением MPI (MPI_FINALIZE()).
Функции MPI иногда используют аргументы с альтернативным типом данных. Различные вызовы той же самой процедуры могут передавать по ссылке фактические аргументы различных типов. Механизм для обеспечения таких аргументов будет отличаться от языка к языку. Для языка ФОРТРАН документ использует < type >, чтобы представить альтернативную переменную, для Си используется (void *).
Некоторые процедуры MPI используют аргумент address, который представляет абсолютный адрес в вызывающей программе. Тип данных такого аргумента есть целое достаточного размера, чтобы хранить любой правильный адрес в среде исполнения.
Этот раздел определяет правила построения языковых привязок вообще и для языков ФОРТРАН77 и ANSI Си в частности. Ожидается, что любая реализация ФОРТРАН90 и С++ будут использовать привязки для языков ФОРТРАН77 и ANSI Си, хотя для них возможны и дополнительные привязки.
Поскольку слово Parameter является ключевым для языка ФОРТРАН, далее используется слово ``аргумент'', чтобы определить аргументы подпрограммы.
Этим стандартом не определены несколько важных проблем языкового связывания. Например, стандарт не обсуждает взаимодействие при передачи сообщений между языками. Ожидается, что много реализаций MPI будут иметь такие особенности и что такие особенности являются признаком качества реализации.
Все имена в MPI имеют MPI_ prefix, и все знаки являются заглавными. Программист не должен декларировать собственные переменные или функции с именами, начинающимися с префиксом MPI_. Это сделано, чтобы избежать противоречий при использовании имен.
Последним аргументом всех подпрограмм MPI на языке ФОРТРАН является код завершения. Небольшое количество операций MPI являются функциями, которые не возвращают код завершения. При успешном завершении операции возвращается значение MPI_SUCCESS. Другие коды ошибок зависят от реализации (см. главу 7).
Дескрипторы представлены в языке ФОРТРАН как INTEGER. Двоичные переменные имеют тип LOGICAL. Аргумены массивов индексируются от единицы.
Привязки для MPI F77 соответствуют стандарту ANSI ФОРТРАН77, если явно не задано другое . Имеется несколько точек, где этот стандарт отходит от стандарта ANSI ФОРТРАН77. Эти исключения соответствуют общей практике программирования на языке ФОРТРАН. В частности:

Все именованные константы MPI могут быть использованы там, где объект, объявленный с атрибутом PARAMETER, может быть использована в языке ФОРТРАН. Имеется одно исключение для этого правила: MPI константа MPI_BOTTOM (раздел 3.12.2) может использоваться как аргумент буфера.
В MPI используется формат ANSI Си. Все имена MPI имеют префикс MPI_ prefix, определяемые константы содержат только заглавные буквы, а определяемые типы и функции имеют одну заглавную букву после префикса. Программист не должен декларировать собственные переменные или функции с именами, которые начинаются с префикса MPI_. Это позволяет избегать возможных коллизий с именами.
Определение именованных констант, прототипов функций и определений типов должно быть обеспечены в include файлах типа mpi.h.
Почти все функции Си возвращают код ошибки. Код успешного завершения имеет значение MPI_SUCCESS, но возвращаемые коды ошибок зависят от реализации MPI. Несколько функций языка Си не имеют возвращаемых значений, так что они могут быть реализованы как макроопределения.
Для указателей по каждой категории скрытых объектов имеются декларации типов. Используется указатель или целый тип.
Аргументы массивов индексируются от нуля.
Логические флаги являются целыми величинами со значением 0, обозначающим false, а ненулевое значение обозначает true.
Альтернативные аргументы являются указателями типа void*.
Адресные аргументы являются MPI определенным типом MPI_Aint.
Все именованные константы MPI могут быть использованы для инициализации выражений или присваивания, подобно константам Си.
Программы MPI состоят из автономных процессов, выполняющих собственный код, написанный в стиле MIMD. Коды, выполняемые каждым процессом, не обязательно идентичны. Процессы взаимодействуют через вызовы коммуникационных примитивов MPI. Обычно каждый процесс выполняется в его собственном адресном пространстве, хотя возможны реализации MPI с разделяемой памятью. Этот документ описывает поведение параллельной программы в предположении, что для обмена используются только вызовы MPI.
MPI не описывает модель исполнения для каждого процесса. Процесс может быть последовательным или многопоточным. В последнем случае необходимо обеспечить ``потоковую безопасность'' (``thread-safe''). Желаемое взаимодействие MPI с потоками должно состоять в том, чтобы разрешить конкурирующим потокам выполнять вызовы MPI, и вызовы должны быть реентерабельными; блокирующие вызовы MPI должны блокировать только вызываемый поток, не препятствуя планированию другого потока.
MPI не обеспечивает механизмы для начального распределения процессов по физическим процессорам. Ожидается, что эти механизмы для этапа загрузки или исполнения обеспечат поставщики. Такие механизмы позволят описывать начальное число требуемых процессов; код, который должен исполняться каждым начальным процессом; размещение процессов по процессорам. Однако, существующее определение MPI не обеспечивает динамического создания или удаления процессов во время исполнения программ (общее число процессов фиксировано), хотя такое расширение предусматривается. Наконец, процесс всегда идентифицируется согласно его относительному номеру в группе, т. е. последовательными целыми числами в диапазоне 0, ..., groupsize-1.
MPI обеспечивает пользователя надежным средством обмена сообщениями. Посылаемые сообщения всегда принимаются корректно и пользователю не нужно проверять правильность передачи, выход за границы заданного времени и другие условия неправильной передачи. Другими словами, MPI не обеспечивает механизмов, имеющих дело с отказами в коммуникационной системе. Если реализация MPI построена на ненадежной основе, тогда разработчик должен изолировать пользователя от этой ненадежности или считать невосстанавливаемые ошибки отказами. Там, где это возможно, такие отказы будут отражены как ошибки в соответствующих коммуникационных вызовах. Точно так же, MPI не обеспечивает механизмов для обработки процессорных отказов. Возможности по обработке ошибок, описанные в разделе 7.2, могут быть использованы для того, чтобы ограничить область невосстанавливаемой ошибки, или спроектировать восстановление после ошибки на прикладном уровне.
Конечно, программы MPI все же могут содержать ошибки. Программная ошибка может иметь место, когда вызов MPI осуществляется с неверным аргументом (несуществующий номер процесса-получателя в операции send, слишком мал буфер в операции приема и так далее). Этот тип ошибок возможен при любой реализации. Дополнительно, может иметь место ресурсная ошибка, когда запрос программы превышает сумму доступных системных ресурсов. Появление этого типа ошибок зависит от объема доступных ресурсов в системе и требуется механизм распределения ресурсов; он может отличаться от системы к системе. Хорошая реализация MPI должна обеспечивать большой объем важных ресурсов, так, чтобы смягчить проблему переносимости программ для этой реализации.
Почти все вызовы MPI возвращают код, в котором отмечается успешное завершение операции. Где возможно, вызовы возвращают код ошибки, если ошибка имела место при выполнении вызова. В определенных обстоятельствах, когда функция MPI может завершать несколько различных операций и поэтому может генерировать несколько независимых ошибок, функция MPI может возвращать множественные коды ошибок. По умолчанию, ошибка, обнаруженная при исполнении библиотеки MPI, вызывает прекращение параллельных вычислений. Однако MPI обеспечивает механизм для пользователя, позволяющий изменить установку по умолчанию, чтобы производить обработку восстанавливаемых ошибок. Пользователь может определить, что никакая ошибка не является фатальной и обрабатывать возвращаемые коды ошибок самостоятельно. Кроме того, пользователь может создать собственные процедуры для обработки ошибок, которые будут вызываться, когда вызов заканчивается ненормально. Возможности обработки ошибок описаны в разделе 7.2.
Несколько факторов ограничивают возможности для вызовов MPI возвращать важные коды ошибок, когда ошибка имеет место. Например, MPI может быть не в состоянии определить некоторые ошибки; выявление других ошибок в нормальном режиме слишком дорого; наконец, некоторые ошибки могут быть ``катастрофическими'' и будут препятствовать MPI возвратить управление в исходное состояние.
Еще одно тонкое обстоятельство возникает вследствие природы асинхронных обменов: MPI может инициировать операции, которые продолжаются асинхронно после того, как вызов завершен. Поэтому операция может заканчиваться с кодом успешного завершения, но после этого все еще вызывать исключение по ошибке. Если имеется последующий вызов, который связан с той же самой операцией (например, вызов, который проверяет, завершена ли асинхронная операция), тогда аргумент ошибки, связанный с этим вызовом, будет использован для определения природы этой ошибки. Иногда ошибка может иметь место после всех вызовов, связанных с завершенной операцией, так что никакое значение ошибки не может быть использовано для определения природы ошибки (например, ошибка при передаче в режиме по готовности). Такая ошибка должна быть обработана как фатальная, поскольку информация не может быть возвращена пользователю для последующего восстановления.
Этот документ не описывает состояние вычислений после того, как имел место вызов с ошибкой. Желательно, чтобы был возвращен код ошибки и эффект ошибки был локализован на участке наименьшего размера. Например, крайне желательно, чтобы ошибочный вызов приема не приводил к модификации любой части памяти принимающего процесса за пределами области, указанной для приема сообщения.
Реализации MPI могут выходить за пределы настоящего документа в части поддержки в стиле MPI тех вызовов, которые могут содержать ошибки. Например, MPI описывает строгие правила соответствия между парными операциями передачи и приема: если послать переменную с плавающей точкой, но при приеме указать целое число, то это вызовет ошибку. Реализация в такой ситуации может позволить себе автоматическое преобразование типа. При этом полезно будет сгенерировать предупреждение о таком особом поведении.
Имеется ряд областей, где реализация может взаимодействовать с операционным окружением и системой. Несмотря на то, что для MPI не требуется наличие различных сервисов (таких как I/O или обработка сигналов), в случае, если такие средства доступны, поведение MPI должно строго соответствовать их наличию. Это важный пункт для достижения мобильности на всех платформах с тем же набором сервисов.
Программы MPI требуют, чтобы библиотечные процедуры, которые являются частью базисной языковой среды (такие как date и write в языке ФОРТРАН, printf и malloc в ANSI Си), и процедуры, исполняемые после MPI_INIT и до MPI_FINALIZE работали независимо, а также чтобы их завершение было независимо от действий других процессов в программе MPI.
Заметим, что это никаким образом не ограничивает создание библиотечных процедур, которые обеспечивают параллелизм для коллективных операций. Однако, следующая программа ожидает завершения в среде ANSI Си в зависимости от размера MPI_COMM_WORLD (полагая, что I/O доступен на исполнительных узлах).
int rank;
MPI_Init(argc, argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0) printf("Starting program\n");
MPI_Finalize();
Соответствующая программа ФОРТРАН77 так же будет ожидать завершения.
Примером того, что не требуется, является любое частное упорядочивание действий этих программ, когда они вызваны несколькими задачами. Например, MPI не предъявляет требований и не дает рекомендаций для выхода из следующей программы (снова полагаем, что I/O имеется на исполнительных узлах).
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
printf("Output from task rank %d\n", rank);
К тому же вызовы, которым отказано из-за нехватки ресурсов, или другая ошибка не рассматриваются здесь нарушением требований (однако, требуется их завершение, не обязательно успешное).
Техническая разработка была выполнена несколькими группами, работа которых была рассмотрена всем комитетом. Список лиц, которые в этот период отвечали за разработку, приведен ниже.
В следующем списке указаны активные участники процесса разработки MPI, не отмеченные выше.
| Ed Anderson | Robert Babb | Joe Baron | Eric Barszcz |
| Scott Berryman | Rob Bjornson | Nathan Doss | Anne Elster |
| Jim Feeney | Vince Fernando | Sam Fineberg | Jon Flower |
| Daniel Frye | Ian Glendinning | Adam Greenberg | Robert Harrison |
| Leslie Hart | Tom Haupt | Don Heller | Tom Henderson |
| Alex Ho | C.T. Howard Ho | Gary Howell | John Kapenga |
| James Kohl | Susan Krauss | Bob Leary | Arthur Maccabe |
| Peter Madams | Alan Mainwaring | Oliver McBryan | Phil McKinley |
| Charles Mosher | Dan Nessett | Peter Pacheco | Howard Palmer |
| Paul Pierce | Sanjay Ranka | Peter Rigsbee | Arch Robison |
| Erich Schikuta | Ambuj Singh | Alan Sussman | Robert Tomlinson |
| Robert G. Voigt | Dennis Weeks | Stephen Wheat | Steve Zenith |
Университет Tennessee и Oak Ridge National Laboratory сделали проект документа доступным для распространения через почтовые FTP серверы.
MPI не описывает ни взаимодействия процессов с сигналами в среде UNIX, ни с другими событиями, которые не относятся к обменам MPI. Это означает, что сигналы не существенны с точки зрения MPI, и разработчикам следует попытаться реализовать MPI так, чтобы сигналы были прозрачными: вызов MPI, приостановленный сигналом, следует возобновить и завершить после обработки сигнала. Вообще, состояние вычислений, которое существенно с точки зрения MPI, должно зависеть только от MPI вызовов.
Стремление MPI обеспечить безопасное выполнение потоков и обработку сигналов имеет ряд тонких эффектов. Нпример, на системах Unix принимаемые сигналы, такие как SIGALRM (сигнал тревоги) не должен вызывать поведение процедур, отличное от поведения в отсутствии сигнала. Конечно, если обработчик сигнала возбуждает вызов MPI или изменяет среду, в которой работают MPI процедуры (например, потребляя всю доступную память), процедура MPI должна вести себя как положено в этой ситуации (в частности, в этом случае поведение должно быть таким же, как для многопоточной реализации).
Второй эффект состоит в том, что обработчик сигнала, который выполняет вызовы MPI, обязан не взаимодействовать с операцией MPI. Например, операция прием любого типа в MPI, которая имеет место внутри обработчика сигнала, не должна вызывать ненормального поведения реализации MPI. Заметим, что реализация может запрещать использование вызовов MPI от сигнального обработчика и не требуется детектировать такое использование.
Крайне желательно, чтобы MPI не использовал SIGALRM, SIGFPE или SIGIO. Реализация обязана ясно документировать все сигналы, которые она использует; хорошим местом для такой информации является Unix `man' page на MPI.
Примеры в этом документе предназначены только для иллюстративных целей. Они
не предназначены для описания стандарта. Более того, примеры даже не были
тщательно проверены.
Передача и прием сообщений процессами - это базовый коммуникационный механизм MPI. Основными операциями парного обмена (point-to-point communication) являются операции send (послать) и receive (получить). Их использование иллюстрируется следующим примером:
#include "mpi.h"
main(argc, argv)
int argc;
char **argv;
{
char message[20];
int myrank;
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
if (myrank == 0) /* code for process zero */
{
strcpy(message,"Hello, there");
MPI_Send(message, strlen(message), MPI_CHAR, 1, 99, MPI_COMM_WORLD);
}
else /* code for process one */
{
MPI_Recv(message, 20, MPI_CHAR, 0, 99, MPI_COMM_WORLD, &status);
printf("received :%s:\n", message);
}
MPI_Finalize();
}
В этом примере процесс нуль (myrank = 0) посылает сообщение процессу один, используя операцию посылки MPI_SEND. Эта операция описывает буфер посылающего процесса (send buffer), из которого извлекаются посылаемые данные. В приведенном примере посылающий буфер состоит из накопителя в памяти процесса нуль, содержащего переменную message.Размещение, размер и тип буфера посылающего процесса описываются первыми тремя параметрами операции send. Посланное сообщение будет содержать 13 символов этой переменной. Операция посылки также связывает с сообщением его атрибуты. Атрибуты определяют номер процесса-получателя сообщения и содержат различную информацию, которая может быть использована операцией receive, чтобы выбрать определенное сообщение среди других. Последние три параметра операции посылки описывают атрибуты посланного сообщения.
Процесс один (myrank = 1) получает это сообщение, используя операцию приема MPI_RECV, и данные сообщения записываются в буфер процесса-получателя (receive buffer). В приведенном примере буфер получателя состоит из накопителя в памяти процесса один, содержащего строку message. Первые три параметра операции приема описывают размещение, размер и тип буфера приема. Следующие три параметра необходимы для выбора входного сообщения. Последний параметр необходим для возврата информации о только что полученном сообщении.
Далее описываются операции блокирующей (bloсking) передачи и блокирующего приема. Будут обсуждены отправка, прием, семантика блокирующего обмена, требования к соответствию типов, преобразование типов в неоднородных средах и более общие коммуникационные режимы.
Ниже рассматривается неблокирующий обмен, затем - универсальные типы данных, которые позволяют эффективно пересылать разнородные и несмежные данные. В заключение описываются вызовы функций для явной упаковки и распаковки сообщений.
Синтаксис функции блокирующей передачи MPI_SEND приведен ниже.
MPI_SEND(buf, count, datatype, dest, tag, comm)
| IN | buf | начальный адрес буфера посылки сообщения (альтернатива) | |
| IN | count | число элементов в буфере посылки (неотрицательное целое) | |
| IN | datatype | тип данных каждого элемента в буфере посылки (дескриптор) | |
| IN | dest | номер процесса-получателя (целое) | |
| IN | tag | тэг сообщения (целое) | |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Send (void* buf, int count, MPI_Datatype datatype,
int dest, int tag, MPI_Comm comm)
MPI_SEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERROR)
<type> BUF(*)
INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR
void MPI::Comm::Send (const void* buf, int count,
const MPI::Datatype& datatype, int dest, int tag) const
Буфер посылки описан в операции MPI_SEND, в которой указано количество последовательно размещенных элементов, тип элементов указан в поле datatype, начиная с элемента по адресу buf. Длина сообщения задается числом элементов, а не числом байтов. Число данных count в сообщении может быть равно нулю, это означает, что область данных в сообщении пуста. Базисные типы данных в сообщении соответствуют базисным типам данных используемого языка программирования. Список соответствия этих типов данных для языка ФОРТРАН и MPI представлен ниже.
| MPI datatype | Fortran datatype |
| MPI_INTEGER | INTEGER |
| MPI_REAL | REAL |
| MPI_DOUBLE_PRECISION | DOUBLE PRECISION |
| MPI_COMPLEX | COMPLEX |
| MPI_LOGICAL | LOGICAL |
| MPI_CHARACTER | CHARACTER(1) |
| MPI_BYTE | |
| MPI_PACKED |
Список соответствия типов данных для языка Си и MPI дан ниже.
| MPI datatype | C datatype |
| MPI_CHAR | signed char |
| MPI_SHORT | signed short int |
| MPI_INT | signed int |
| MPI_LONG | signed long int |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_UNSIGNED_SHORT | unsigned short int |
| MPI_UNSIGNED | unsigned int |
| MPI_UNSIGNED_LONG | unsigned long int |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_LONG_DOUBLE | long double |
| MPI_BYTE | |
| MPI_PACKED |
Типы MPI_BYTE и MPI_PACKED не имеют соответствия в языках Си или ФОРТРАН. Значением типа MPI_BYTE является байт (8 двоичных цифр). Байт не интерпретируется и отличен от символа. Различные машины могут иметь различное представление для символов или могут использовать для представления символов более одного байта. С другой стороны, байт имеет то же самое двоичное значение на всех машинах. Использование типа MPI_PACKED объясняется в разделе 3.13.
MPI требует поддержки для указанных выше типов данных, соответствующих базовым типам языков ФОРТРАН77 и ANSI Си. В MPI необходимо ввести дополнительные типы данных, если базовый язык имеет следующие типы данных:
Объяснение: Одной из целей проектирования MPI является создание возможности реализации MPI как библиотеки, не требующей дополнительной предобработки или компиляции. Поэтому не следует предполагать, что коммуникационный вызов имеет информацию о типе переменных в коммуникационном буфере; эта информация должна быть представлена в виде явного аргумента. Необходимость такой информации будет объяснена в разделе 3.3.2.[]
В дополнение к описанию данных сообщение несет информацию, которая используется, чтобы различать и выбирать сообщения. Эта информация состоит из фиксированного количества полей, которые в совокупности называются атрибутами сообщения (message envelope). Эти поля таковы: source, destination , tag , communicator (номер процесса-отправителя сообщения, номер процесса-получателя, тэг, коммуникатор).
Целочисленный аргумент тэг (tag) используется, чтобы различать типы сообщений. Диапазон значений тэга находится в пределах 0,... ,UB, где верхнее значение UB зависит от реализации. Оно может быть определено путем опроса значения атрибута MPI_TAG_UB, как описано в главе 7. MPI требует, чтобы UB было не менее, чем 32767.
Аргумент comm описывает коммуникатор (communicator), который используется в операции обмена. Коммуникаторы объясняются в главе 5, ниже дается краткое изложение их использования.
Коммуникатор описывает коммуникационный контекст коммуникационной операции. Сообщение всегда принимается внутри контекста, в котором оно было послано; сообщения, посланные в различных контекстах, не взаимодействуют.
Коммуникатор также описывает ряд процессов, которые разделяют этот коммуникационный контекст. Эта группа процессов (process group) упорядочена и процессы определяются своим номером внутри этой группы. Вследствие этого диапазон значений для dest - 0, ... , n-1, где n - число процессов в группе. (Если коммуникатор является интеркоммуникатором, тогда процессы-получатели идентифицируются их номером в удаленной группе (cм. главу 5).
В MPI предопределен коммуникатор MPI_COMM_WORLD. Он разрешает обмен для всех процессов, которые доступны после инициализации MPI, и процессы идентифицируются их номером в группе MPI_COMM_WORLD.
Совет пользователям: Пользователям, которые знакомы с обозначениями для однородного пространства имен процессов и единственным коммуникационным контекстом (так сделано в большинстве существующих коммуникационных библиотек) нужно использовать только предопределенную переменную MPI_COMM_WORLD в качестве аргумента comm. Это позволяет производить обмен для всех процессов, доступных во время инициализации.
Как показано в главе 5, пользователь может определить новые коммуникаторы. Коммуникаторы обеспечивают важный инкапсуляционный механизм для библиотек и модулей. Они позволяют модулям иметь их собственное выделенное коммуникационное пространство и их собственную схему нумерации процессов.[]
Совет разработчикам: Желательно было бы кодировать атрибуты сообщения в формате фиксированной длины. Однако реальное кодирование зависит от реализации. Некоторая информация (например, имя источника или приемника) может быть неявной и не передаваться сообщением явно. Процессы также могут быть идентифицированы относительным, абсолютным номером и т.д.[]
Синтаксис функции блокирующего приема MPI_RECV представлен ниже.
MPI_RECV (buf, count, datatype, source, tag, comm, status)
| OUT | buf | начальный адрес буфера процесса-получателя (альтернатива) | |
| IN | count | число элементов в принимаемом сообщении (целое) | |
| IN | datatype | тип данных каждого элемента сообщения (дескриптор) | |
| IN | source | номер процесса-отправителя (целое) | |
| IN | tag | тэг сообщения (целое) | |
| IN | comm | коммуникатор (дескриптор) | |
| OUT | status | статус (параметры) принятого сообщения (статус) |
int MPI_Recv (void* buf, int count, MPI_Datatype datatype,
int source, int tag, MPI_Comm comm, MPI_Status *status)
MPI_RECV(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS, IERROR)
<type> BUF(*)
INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM,
STATUS(MPI_STATUS_SIZE), IERROR
void MPI::Comm::Recv (void* buf, int count, const MPI::Datatype& datatype,
int source, int tag, MPI::Status& status) const
void MPI::Comm::Recv (void* buf, int count,
const MPI::Datatype& datatype, int source, int tag) const
Буфер получения состоит из накопителя, содержащего последовательность элементов, тип которых указан в поле datatype и адресуемых, начиная с адреса buf. Длина получаемого сообщения должна быть равна или меньше длины буфера получения, в противном случае возникнет ошибка переполнения. Если сообщение меньше размера буфера получения, то в нем модифицируются только ячейки, соответствующие длине сообщения.
Совет пользователям: Функция MPI_PROBE, описанная в разделе 3.8, может быть использована для получения сообщений неизвестной длины.[]
Совет разработчикам: Хотя никакого специального поведения для ошибочных программ в MPI не предусмотрено, рекомендуется в случае переполнения возвращать в status информацию об отправителе и тэг входного сообщения. Операция приема возвратит код ошибки. Хорошая реализация MPI должна также гарантировать, что никакая память за пределами буфера приема не будет модифицирована.
В случае приема сообщения, размер которого меньше размера буфера получения, MPI определяет, что не должна производиться модификация никаких других ячеек. При более мягком подходе возможны были бы некоторые оптимизации, но это не разрешено. Реализация обязана заканчивать копирование в память процесса-получателя точно по адресу окончания буфера получения, даже если адрес нечетный.[]
Селекция сообщения операцией приема выполняется под управлением значений атрибутов сообщения. Прием сообщения осуществляется, если его атрибуты соответствуют значениям источника, тэга и коммуникатора, указанным в операции приема. Процесс-получатель может задавать значение MPI_ANY_SOURCE для отправителя и/или значение MPI_ANY_TAG для тэга, определяя тем самым, что любой отправитель и/или тэг разрешен.
Однако, нельзя задать произвольное значение для comm. Следовательно, сообщение может быть принято, если оно адресовано данному получателю и имеет соответствующий коммуникатор.
Тэг сообщения задается аргументом tag операции приема. Аргумент
отправителя, если он отличен от MPI_ANY_SOURCE, задается как
номер внутри группы процессов, связанной с тем же самым коммуникатором
(удаленная группа для интеркоммуникаторов). Следовательно, диапазон значений
для аргумента отправителя находится в пределах {0,..., n-1} ![]() {MPI_ANY_SOURCE}, где n - количество процессов в
этой группе.
{MPI_ANY_SOURCE}, где n - количество процессов в
этой группе.
Отметим ассиметрию между операциями посылки и приема. Операция приема допускает получение сообщения от произвольного отправителя, в то время как в операции посылки должен быть указан уникальный получатель.
Допускается ситуация, когда имена источника и получателя совпадают, то есть процесс может посылать сообщение самому себе (однако это небезопасно для блокирующих операций посылки и приема, описанных выше, поскольку это может привести к дедлоку (deadlock)).
Совет разработчикам: Контекст сообщения и другая информация о коммуникаторе может быть реализована как дополнительное поле тэга. Оно отличается от обычного тэга сообщения тем, что в этом поле не разрешаются неопределенные номера процессов и что установкой значений этого поля управляют манипуляционные функции коммуникатора.[]
Источник или тэг принимаемого сообщения могут быть неизвестны, если в операции приема были использованы значения типа ANY. Если множественные запросы завершаются единственной функцией MPI (см. раздел 3.7.5), может потребоваться возвратить различные коды ошибок для каждого запроса. Эта информация возвращается с помощью аргумента status операции MPI_RECV. Тип аргумента status определяется MPI. Статусные переменные размещаются пользователем явно, то есть они не являются системными объектами.
В языке Си status - это структура, которая содержит три поля,
называемые MPI_SOURCE, MPI_TAG и MPI_ERROR; структура
может содержать дополнительные поля. Следовательно,
status.MPI_SOURCE, status.MPI_TAG и status.MPI_ERROR
содержат источник, тэг и код ошибки принятого сообщения.
В языке ФОРТРАН status - массив целых значений размера
MPI_STATUS_SIZE. Константы
MPI_SOURCE, MPI_TAG
и MPI_ERROR определяют объекты, которые хранят поля источника, тэга и
ошибки. Следовательно, status(MPI_SOURCE), status(MPI_TAG)
и status(MPI_ERROR) содержат соответственно источник, тэг и код
ошибки принимаемого сообщения.
В общем случае вызовы передачи сообщений не модифицируют значения полей кода ошибки статусных переменных. Эти поля могут быть изменены только функциями из раздела 3.7.5, которые возвращают множественные статусы. Поля изменяются, если и только если такая функция возвращает код ошибки MPI_ERR_IN_STATUS.
Объяснение: Поле ошибки в статусе не является необходимым для вызовов, которые возвращают только один статус, например, для таких вызовов, как MPI_WAIT, так как это приведет только к дублированию информации, возвращаемой функцией. Эти поля нужны для вызовов, которые возвращают множественные статусы, поскольку каждое требование могло иметь свою причину отказа.[]
Статусный аргумент также возвращает информацию о длине принятого сообщения. Однако, эта информация не является доступной непосредственно, как поле статусной переменной, и требуется вызов MPI_GET_COUNT, чтобы ``декодировать'' эту информацию.
Синтаксис функции MPI_GET_COUNT представлен ниже.
MPI_GET_COUNT(status, datatype, count)
| IN | status | возвращает статус операции приема (статус) | |
| IN | datatype | тип данных каждого элемента приемного буфера (дескриптор) | |
| OUT | count | количество полученных элементов (целое) |
int MPI_Get_count(MPI_Status *status, MPI_Datatype datatype, int *count) MPI_GET_COUNT(STATUS, DATATYPE, COUNT, IERROR) INTEGER STATUS(MPI_STATUS_SIZE), DATATYPE, COUNT, IERROR int Status::Get_count(const MPI::Datatype& datatype) const
Операция MPI_GET_COUNT возвращает число полученных элементов. Аргумент datatype следует сопоставлять с аргументом из операции приема, которая устанавливает статусную переменную. (Позже в разделе 3.12.5 будет показано, что MPI_GET_COUNT может возвращать в определенных ситуациях значение MPI_UNDEFINED.)
Объяснение: Некоторые библиотеки для передачи сообщений используют аргументы INOUT count, tag и sourse. Это позволяет выбирать критерии селекции для входящих сообщений, и возвращать текущие значения атрибутов принятого сообщения. Использование отдельного статусного аргумента предупреждает ошибки, которые часто возникают при использовании аргумента INOUT (то есть при использовании константы MPI_ANY_TAG как тэга при приеме). Некоторые библиотеки используют вызовы, которые неявно обращаются к ``последнему принятому сообщению''.
Аргумент datatype передается в MPI_GET_COUNT, чтобы улучшить характеристики обмена. Сообщение может быть получено без подсчета числа элементов, которое оно содержит, и этот подсчет часто не нужен. Становится возможным использовать ту же самую функцию после вызова MPI_PROBE.[]
Все операции посылки и приема используют аргументы buf, count, datatype, source, dest, tag, comm иstatus таким же образом, как и блокирующие операции MPI_SEND иMPI_RECV, описанные в этом разделе.



Next: Введение в MPI Up: testbook Previous: Благодарности
Contents
- Предисловие редактора перевода
- MPI: Стандарт интерфейса передачи сообщений
- Благодарности
- Введение в MPI
- Обзор и цели
- Кому следует использовать этот стандарт?
- Для каких платформ предназначены реализации?
- Что включено в стандарт?
- Что не входит в стандарт?
- Организация этого документа
- Термины и соглашения в MPI
- Обозначения в документе
- Описание процедур
- Семантические термины
- Типы данных
- Языковые привязки (Language Binding)
- Процессы
- Обработка ошибок
- Проблемы реализации
- Примеры
- Парные межпроцессные обмены
- Введение
- Операции блокирующей передачи и блокирующего приема
- Соответствие типов данных и преобразование данных
- Коммуникационные режимы
- Семантика парного обмена между процессами.
- Распределение и использование буферов
- Неблокирующий обмен
- Проба и отмена
- Персистентные коммуникационные запросы
- Совмещенные прием и передача сообщений (send-receive)
- Нуль процессы
- Производные типы данных
- Упаковка и распаковка
- Коллективные взаимодействия процессов
- Введение и обзор
- Аргументы коммуникатора
- Барьерная синхронизация
- Широковещательный обмен
- Сборка данных
- Рассылка
- Сборка для всех процессов
- Функция all-to-all Scatter/Gather
- Глобальные операции редукции
- Функция Reduce-Scatter
- Функция Scan
- Корректность
- Группы, контексты и коммуникаторы
- Введение
- Базовые концепции
- Управление группой
- Управление коммуникаторами
- Примеры
- Интер-коммуникация
- Кэширование
- Топологии процессов
- Введение
- Виртуальные топологии
- Совместимость с MPI
- Общие сведения о функциях
- Топологические конструкторы
- Прикладной пример
- Управление исполнительной средой MPI
- Информация о реализации MPI
- Обработка ошибок
- Коды и классы ошибок.
- Таймеры и синхронизация.
- Подготовка к запуску параллельных программ
- Номер версии
- Иинтерфейс профилирования
- Библиография
- Дополнительные источники
- Приложение А. Языковые привязки для языков Си и ФОРТРАН
- Приложение B. Языковые привязки в MPI-1 для языка С++
- Приложение С. Версия 1.2 для MPI
- Приложение D. Перечень функций MPI-1.1
- About this document ...
Alex Otwagin 2002-12-10
Передача данных содержит следующие три фазы:
Соответствие типов должно отслеживаться на каждой из трех фаз: тип каждой переменной в буфере посылки должен соответствовать типу, указанному для этого элемента в операции посылки; тип, описанный в операции посылки , должен соответствовать типу, указанному в операции приема; и тип каждой переменной в приемном буфере должен соответствовать типу, указанному для нее в операции приема. Программа, в которой не соблюдаются эти три правила, является неверной.
Чтобы определить соответствие типов более точно, приходится иметь дело с двумя проблемами: с проблемой сравнения типов исходного языка с типами, указанными в коммуникационных операциях, и с проблемой сравнения типов отправителя и получателя.
Типы отправителя и получателя (фаза два) соответствуют друг другу, если обе операции используют одинаковые названия. Это означает, что MPI_INTEGER соответствует MPI_INTEGER, MPI_REAL соответствует MPI_REAL, и так далее. Имеется одно исключение из этого правила, которое обсуждается в разделе 3.13, тип MPI_PACKED может соответствовать любому другому типу.
Тип переменной в хост (главной) программе соответствует типу, указанному в операции обмена, если название типа данных, используемое этой операцией, соответствует базисному типу переменной хост программы. Например, элемент с названием типа MPI_INTEGER соответствует в языке ФОРТРАН переменной типа INTEGER. Таблица, описывающая соответствие для языков ФОРТРАН и Си, представлена в разделе 3.2.2. Имеется два исключения из этого последнего правила: элемент с названием типа MPI_BYTE или MPI_PACKED может соответствовать любому байту памяти (на байт-адресуемой машине), без учета типа переменной, которая содержит этот байт. Тип MPI_PACKED используется для передачи данных, которые были явно упакованы, или для получения данных, которые будут явно распакованы (см. раздел 3.13). Тип MPI_BYTE позволяет передавать неизменным двоичное значение байта из памяти.
В итоге правила соответствия типов можно разделить на три категории, указанные ниже:
Следующие примеры иллюстрируют первые два случая.
Пример 3.1 Отправитель и получатель указывают типы соответствия.
CALL MPI_COMM_RANK(comm, rank, ierr)
IF(rank.EQ.0) THEN
CALL MPI_SEND(a(1), 10, MPI_REAL, 1, tag, comm, ierr)
ELSE
CALL MPI_RECV(b(1), 15, MPI_REAL, 0, tag, comm, status, ierr)
END IF
Этот код корректен, если a и b есть действительные массивы
размера ![]() 10.
(В языке ФОРТРАН может быть корректным использовать этот код даже
если a или b имеют размер < 10, например, когда a(1)
эквивалентно массиву с десятью действительными числами.)
10.
(В языке ФОРТРАН может быть корректным использовать этот код даже
если a или b имеют размер < 10, например, когда a(1)
эквивалентно массиву с десятью действительными числами.)
Пример 3.2 Отправитель и получатель не указывают типы соответствия.
CALL MPI_COMM_RANK(comm, rank, ierr)
IF(rank.EQ.0) THEN
CALL MPI_SEND(a(1), 10, MPI_REAL, 1, tag, comm, ierr)
ELSE
CALL MPI_RECV(b(1), 40, MPI_BYTE, 0, tag, comm, status, ierr)
END IF
Этот код неверен, поскольку отправитель и получатель описывают различные типы данных.
Пример 3.3 Отправитель и получатель описывают передачу нетипизированных значений.
CALL MPI_COMM_RANK(comm, rank, ierr)
IF(rank.EQ.0) THEN
CALL MPI_SEND(a(1), 40, MPI_BYTE, 1, tag, comm, ierr)
ELSE
CALL MPI_RECV(b(1), 60, MPI_BYTE, 0, tag, comm, status, ierr)
END IF
Этот код правилен безотносительно к типу и размеру а и b (кроме случая, когда эти результаты выходят за границы памяти).
Совет пользователям: Если буфер типа MPI_BYTE передается в качестве аргумента операции MPI_SEND, то MPI будет посылать данные, хранимые в buf в смежных ячейках, начиная с адреса, указанного в аргументе buf. Это может иметь неожиданный результат, когда данные размещены не так, как предполагал их видеть пользователь. Например, некоторые компиляторы языка ФОРТРАН реализуют переменные типа CHARACTER как структуру, которая содержит длину знака и указатель на реальную строку. В такой среде передача и прием переменной CHARACTER с использованием типа MPI_BYTE не будет иметь ожидаемого результата передачи знаковой строки. По этой причине пользователю рекомендуется использовать типизированные обмены, где только возможно.[]
Тип MPI_CHARACTER соответствует одному знаку переменной языка ФОРТРАН с типом
CHARACTER, а не полной знаковой строке, хранимой в
переменной. Переменные языка ФОРТРАН типа CHARACTER или
подстроки передаются, как если бы они были массивами знаков. Это показано в
примере ниже.
Пример 3.4 Передача знаков в языке ФОРТРАН
CHARACTER*10 a
CHARACTER*10 b
CALL MPI_COMM_RANK(comm, rank, ierr)
IF(rank.EQ.0) THEN
CALL MPI_SEND(a, 5, MPI_CHARACTER, 1, tag, comm, ierr)
ELSE
CALL MPI_RECV(b(6:10), 5, MPI_CHARACTER, 0, tag, comm, status, ierr)
END IF
Последние пять знаков строки b в процессе 1 замещаются пятью первыми знаками строки процесса 0.
Объяснение: Альтернативой для MPI_CHARACTER могло бы быть соответствие знаку произвольной длины, однако это создает следующую проблему.
Знаковая переменная языка ФОРТРАН есть строка постоянной длины без специального символа конца. Не имеется зафиксированного соглашения о том, как представлять символы и как хранить их длину. Некоторые компиляторы передают аргумент знака процедуре как пару аргументов: один хранит адрес строки, другой - длину строки. Рассмотрим случай вызова обменаMPI, который передает коммуникационный буфер с типом derived datatype (производный тип данных, раздел 3.12). Если этот коммуникационный буфер содержит переменную типа MPI_CHARACTER, то информация о его длине не будет послана процедуре MPI.
Эта проблема приводит к заданию явной информации о длине знака в вызове MPI. Можно добавить параметр длины к типу MPI_CHARACTER, но это не добавляет удобства и те же возможности могут быть достигнуты определением подходящего производного типа данных.[]
Совет разработчикам: Некоторые компиляторы передают в языке ФОРТРАН аргумент типа
CHARACTER как структуру с длиной и указателем на
реальную строку. В такой среде вызов MPI должен преобразовывать
указатель, чтобы достичь строки.[]
Одной из целей MPI является поддержка параллельных вычислений в неоднородной среде. Связь в такой среде может потребовать преобразования данных. Будем использовать следующую терминологию:
Правила соответствия типов приводят к тому, что обмен в MPI никогда не влечет за собой преобразования типов. С другой стороны MPI требует, чтобы преобразование представления выполнялось, когда типизированное значение передается через среды, которые используют различные представления для типов данных этих значений. MPI не описывает правил для преобразования представления. Предполагается, что такое преобразование должно сохранять целые, логические или знаковые значения, и преобразовывать значения с плавающей точкой к ближайшему значению, которое может быть представлено на целевой системе.
Во время преобразования с плавающей точкой могут иметь место исключения по переполнению и потере значимости. Преобразование целых или знаков также может приводить к исключениям, когда значения, которые могут быть представлены в одной системе, не могут быть представлены в другой системе. Исключения при преобразовании представления приводят к невозможности обмена. Ошибка имеет место либо на операции посылки, либо на операции приема, или на обеих операциях.
Если значение, посылаемое в сообщении, не типизировано (например, типа MPI_BYTE), тогда двоичное представление байта, хранимое на стороне получателя, идентично двоичному представлению байта, загруженного на стороне отправителя. Ситуация сохраняется вне зависимости от того, работают ли отправитель и получатель в одной и той же или различающихся средах. Никакого преобразования представления не требуется. (Заметим, что преобразования представления могут иметь место, когда значения типа MPI_CHARACTER или MPI_CHAR, передаются, например, из кодирования EBCDIC в кодирование ASCII).
Никакого преобразования не нужно, когда программы MPI работают в однородной системе, т.е. когда все процессы выполняются в той же самой среде.
Рассмотрим три примера 3.1 - 3.3. Первая программа верна, если
a и b являются действительными массивами размера ![]() 10. Если
отправитель и получатель работают в различных средах, тогда десять
действительных значений, которые извлекаются из буфера отправителя, будут
преобразованы в представление для действительных чисел на приемной стороне
прежде, чем они будут записаны в приемный буфер. В то время, как количество
действительных чисел, извлекаемых из буфера отправителя равно количеству
действительных чисел, хранимых в приемном буфере, количество хранимых
байтов не обязано быть равным количеству загруженных байтов. Например,
отправитель может использовать четырехбайтовое представление для
действительных чисел, а получатель - восьмибайтовое.
10. Если
отправитель и получатель работают в различных средах, тогда десять
действительных значений, которые извлекаются из буфера отправителя, будут
преобразованы в представление для действительных чисел на приемной стороне
прежде, чем они будут записаны в приемный буфер. В то время, как количество
действительных чисел, извлекаемых из буфера отправителя равно количеству
действительных чисел, хранимых в приемном буфере, количество хранимых
байтов не обязано быть равным количеству загруженных байтов. Например,
отправитель может использовать четырехбайтовое представление для
действительных чисел, а получатель - восьмибайтовое.
Вторая программа содержит ошибки и ее поведение является неопределенным.
Третья программа правильная. Точно та же последовательнасть из сорока байтов, которая была загружена из буфера посылки, будет записана в приемный буфер, даже если получатель и отправитель работают в различных средах. Посланное сообщение имеет точно ту же длину (в байтах) и точно то же двоичное представление, как и принятое сообщение. Если a и b принадлежат к различным типам, или они имеют одинаковый тип, но различное представление, тогда биты, хранимые в приемном буфере, могут кодировать значения, которые отличаются от значений, закодированных теми же битами в буфере передачи.
Преобразование представления также относится и к атрибутам сообщения: источник, приемник и тэг являются целыми числами и могут нуждаться в преобразовании.
Совет разработчикам: Существующее описание MPI не требует, чтобы сообщения переносили информацию о типе данных. Как отправитель, так и приемник обеспечивают комплектование информации о типе данных. В неоднородной среде можно либо использовать независимое от машины кодирование, например, XDR, либо иметь преобразователь на стороне приемника или даже отправителя.
К сообщению могут быть добавлены дополнительные типы информации, чтобы позволить системе определять расхождение между типами данных отправителя и приемника. Это, в частности, может быть полезно в более медленном, но безопасном режиме отладки.[]
MPI не требует поддержки межъязыкового обмена. Поведение программы не определено, если сообщение послано процессом в языке Си, а принято процессом в языке ФОРТРАН, или наоборот.
Объяснение: MPI не выполняет обработку межъязыковых обменов, поскольку нет согласованных стандартов для соответствия между типами языков Си и ФОРТРАН. Поэтому MPI программы, в которых смешаны языки, не будут переносимыми.[]
Совет разработчикам: Разработчики MPI могут попробовать поддерживать межъязыковые обмены, разрешая программам на языке ФОРТРАН использовать ``C MPI types'', такие как MPI_INT, MPI_CHAR и так далее, и позволяя программам на Си использовать типы языка ФОРТРАН.[]
Вызов send, описанный в разделе 3.2.1, является блокирующим: он не возвращает управления до тех пор, пока данные и атрибуты сообщения надежно не сохранены в другом месте, чтобы процесс-отправитель мог обращаться к буферу посылки и перезаписывать его. Сообщение может быть скопировано прямо в соответствующий приемный буфер или во временный системный буфер.
Буферизация сообщения связывает операции посылки и приема. Блокирующая передача может завершаться сразу после буферизации сообщения, даже если приемник не выполнил соответствующего приема. С другой стороны, буферизация сообщения может оказаться дорогой, так как она вовлекает дополнительное копирование память-память, и это требует выделения памяти для буферизации. MРI имеет выбор из нескольких коммуникационных режимов, которые позволяют управлять выбором коммуникационного протокола.
Вызов send, описанный в разделе 3.2.1, использует стандартный (standart) коммуникационный режим. В этом режиме решение о том, будет ли исходящее сообщение буферизовано или нет, принимает MРI. MРI может буферизовать исходящее сообщение. В таком случае операция посылки может завершиться до того, как будет вызван соответствующий прием. С другой стороны, буферное пространство может отсутствовать или MРI может отказаться от буферизации исходящего сообщения из-за ухудшения характеристик обмена. В этом случае вызов send не будет завершен, пока данные не будут перемещены в процесс-получатель.
Следовательно, в стандартном режиме посылка может стартовать вне зависимости от того, выполнен ли соответствующий прием. Она может быть завершена до окончания приема. Посылка в стандартном режиме является нелокальной операцией: она может зависеть от условий приема.
Объяснение: Нежелание разрешать в стандартном режиме буферизацию проистекает от стремления сделать программы переносимыми. Поскольку рано или поздно при повышении размера сообщения в любой системе буферных ресурсов окажется недостаточно, MPI констатирует, что правильная (и, следовательно, переносимая) программа не должна зависеть в стандартном режиме от системной буферизации. Буферизация может улучшить характеристики правильной программы, но она не влияет на результат выполнения программы. Если пользователь может гарантированно предоставить определенный объем буферного пространства, можно использовать поддерживаемую пользователем буферную систему из раздела 3.6 совместно с передачей в буферизованном режиме.[]
Существует три дополнительных коммуникационных режима.
Буферизованный (buffered) режим операции посылки может стартовать вне зависимости от того, инициирован ли соответствующий прием. Однако, в отличие от стандартной посылки, эта операция является локальной и ее завершение не зависит от обстоятельств приема. Следовательно, если посылка выполнена и никакого соответствующего приема не инициировано, тогда MPI обязан буферизовать исходящее сообщение, чтобы позволить завершиться вызову send. Если не имеется достаточного объема буферного пространства, возникнет ошибка. Объем буферного пространства задается пользователем (см. раздел 3.6). Для того, чтобы буферизованный режим был эффективным, может потребоваться распределение буферов пользователем.
Посылка, которая использует синхронный (synchronous) режим, может стартовать вне зависимости от того, был ли начат соответствующий прием. Однако, посылка будет завершена успешно, только если соответствующая операция приема стартовала. Следовательно, завершение синхронной передачи не только указывает, что буфер отправителя может быть повторно использован, но также и отмечает, что получатель достиг определенной точки в своей работе, а именно, что он начал выполнение приема. Если и посылка, и прием являются блокирующими операциями, тогда использование синхронного режима обеспечивает синхронную коммуникационную семантику: посылка не завершается на любой стороне обмена, пока оба процесса не выполнят рандеву в процессе операции обмена. Выполнение обмена в этом режиме является нелокальным.
Посылка, которая использует режим обмена по готовности (ready communication mode), может быть запущена только тогда, когда прием уже инициирован. В противном случае операция является ошибочной и результат будет неопределенным. На некоторых системах обмен по готовности позволяет устранить необходимость в рандеву, что улучшает характеристики обмена. Завершение операции посылки не зависит от состояния приема и в основном указывает, что буфер посылки может быть повторно использован. Операция посылки, которая использует режим готовности, имеет ту же семантику, как и стандартная или синхронная передача; это означает, что отправитель обеспечивает систему дополнительной информацией (а именно, что прием уже инициирован), которая может уменьшить накладные расходы. Вследствие этого в правильной программе посылка по готовности может быть замещена стандартной передачей без влияния на поведение программы (но не на характеристики).
Для трех дополнительных коммуникационных режимов используются три дополнительные функции передачи. Коммуникационный режим отмечается одной префиксной буквой: B - для буферизованного, S - для синхронного и R - для режима готовности.
Синтаксис функции MPI_BSEND представлен ниже.
MPI_BSEND(buf, count, datatype, dest, tag, comm)
| IN | buf | начальный адрес буфера посылки (альтернатива) | |
| IN | count | число элементов в буфере посылки (неотрицательное целое) | |
| IN | datatype | тип данных каждого элемента в буфере посылки (дескриптор) | |
| IN | dest | номер процесса-получателя (целое) | |
| IN | tag | тэг сообщения (целое) | |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Bsend (void* buf, int count, MPI_Datatype datatype,
int dest, int tag, MPI_Comm comm)
MPI_BSEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERROR)
<type> BUF(*)
INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR
void MPI::Comm::Bsend(const void* buf, int count,
const MPI::Datatype& datatype, int dest, int tag) const
Синтаксис функции MPI_SSEND представлен ниже.
MPI_SSEND (buf, count, datatype, dest, tag, comm)
| IN | buf | начальный адрес буфера посылки (альтернатива) | |
| IN | count | число элементов в буфере посылки (неотрицательное целое) | |
| IN | datatype | тип данных каждого элемента в буфере посылки (дескриптор) | |
| IN | dest | номер процесса-получателя (целое) | |
| IN | tag | тэг сообщения (целое) | |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Ssend(void* buf, int count, MPI_Datatype datatype,
int dest, int tag, MPI_Comm comm)
MPI_SSEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERROR)
<type> BUF(*)
INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR
void MPI::Comm::Ssend(const void* buf, int count,
const MPI::Datatype& datatype, int dest, int tag) const
Синтаксис функции MPI_RSEND представлен ниже.
MPI_RSEND (buf, count, datatype, dest, tag, comm)
| IN | buf | начальный адрес буфера посылки (альтернатива) | |
| IN | count | число элементов в буфере посылки (неотрицательное целое) | |
| IN | datatype | тип данных каждого элемента в буфере посылки (дескриптор) | |
| IN | dest | номер процесса-получателя (целое) | |
| IN | tag | тэг сообщения (целое) | |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Rsend(void* buf, int count, MPI_Datatype datatype,
int dest, int tag, MPI_Comm comm)
MPI_RSEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERROR)
<type> BUF(*)
INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR
void MPI::Comm::Rsend(const void* buf, int count,
const MPI::Datatype& datatype, int dest, int tag) const
Имеется только одна операция приема, которая может соответствовать любому режиму передачи. Эта операция блокирования (blocking), описанная в последнем разделе: она завершается только после момента, когда приемный буфер уже содержит новое сообщение. Прием может завершаться перед завершением соответствующей передачи (конечно, он может завершаться только после того, как передача стартует).
В многопоточной реализации MPI система может перепланировать поток, который блокирован на операции отправки или приема, и назначить другой поток для исполнения в том же адресном пространстве. В этом случае вопрос о доступе к буферу обмена или его модификации до завершения обмена решается пользователем. В противном случае результат вычислений не определен.
Объяснение: Когда буфер используется, обращение к нему запрещено, даже если в операции посылки не предполагается изменять содержание этого буфера. Это может показаться излишне строгим, но дополнительное ограничение вызывает небольшую потерю возможностей и дает улучшение характеристик на некоторых системах. Примером является случай, когда передача данных выполняется машиной с DMA, которая не когерентна по кэшу с основным процессом.[]
Совет разработчикам: Возможные коммуникационные протоколы для различных режимов представлены ниже:
Для управления потоками и восстановления ошибок может понадобиться дополнительное управление. Конечно, имеется много других протоколов.
Посылка по готовности может быть реализована как стандартная передача. В этом случае для режима посылки по готовности никаких преимуществ (или потерь) по характеристикам не будет.
Стандартная передача может быть реализована как синхронная. В этом случае не нужна буферизация. Однако, многие (или даже большинство ?) пользователей в определенной степени желают использовать буферизацию.
В многопоточной среде при выполнении блокирующего обмена следует блокировать только выполняемый поток, давая возможность планировщику потоков перепланировать этот поток и поставить на исполнение другой поток.[]
Правильная реализация MPI гарантирует определенные общие свойства парного обмена, которые описаны ниже.
Очередность (Оrder). Сообщения не обгоняют друг друга: если отправитель последовательно посылает два сообщения на один адрес, то они должны быть приняты в том же порядке. Если получатель инициирует два приема последовательно и оба соответствуют одному и тому же сообщению, то вторая операция не будет принимать это сообщение, если первая операция все еще не выполнена. Это требование облегчает установление соответствия посылки и приема. Оно гарантирует, что программа с передачей сообщений детерминирована, если процессы однопоточные и операция MPI_ANY_SOURCE не используется при приеме. (Некоторые вызовы, описанные позже, такие как MPI_CANCEL или MPI_WAITANY, являются дополнительным источником недетерминизма).
Если процесс имеет однопоточное исполнение, тогда любые два обмена, выполняемые этим процессом, упорядочены. С другой стороны, если процесс многопоточный, тогда семантика потокового исполнения может быть неопределена относительно порядка для двух операций посылки, выполняемых двумя различными ветвями. Операции логически являются конкурентами, даже если одна физически предшествует другой. Аналогично, если две операции приема, которые логически конкурентны, принимают два последовательно посланных сообщения, то два сообщения могут соответствовать двум приемам в различном порядке.
Пример 3.5 Пример необгоняющих сообщений
CALL MPI_COMM_RANK(comm, rank, ierr)
IF (rank.EQ.0) THEN
CALL MPI_BSEND(buf1, count, MPI_REAL, 1, tag, comm, ierr)
CALL MPI_BSEND(buf2, count, MPI_REAL, 1, tag, comm, ierr)
ELSE ! rank.EQ.1
CALL MPI_RECV(buf1, count, MPI_REAL, 0, MPI_ANY_TAG, comm, status, ierr)
CALL MPI_RECV(buf2, count, MPI_REAL, 0, tag, comm, status, ierr)
END IF
Сообщение, посланное в первой передаче, обязано быть принято в первом приеме; сообщение, посланное во второй передаче, обязано быть принято во втором приеме.
Продвижение обмена (Progress). Если пара соответствующих посылки и приема инициализирована двумя процессами, тогда по крайней мере одна из этих двух операций будет завершена, независимо от других действий в системе: операция посылки будет завершена, несмотря на то, что прием завершен другим сообщением; операция приема будет завершена, не глядя на то, что посланное сообщение будет поглощено другим соответствующим приемом, который был установлен на том же самом процессе-получателе.
Пример 3.6 Пример двух пересекающихся пар.
CALL MPI_COMM_RANK(comm, rank, ierr)
IF (rank.EQ.0) THEN
CALL MPI_BSEND(buf1, count, MPI_REAL, 1, tag1, comm, ierr)
CALL MPI_SSEND(buf2, count, MPI_REAL, 1, tag2, comm, ierr)
ELSE ! rank.EQ.1
CALL MPI_RECV(buf1, count, MPI_REAL, 0, tag2, comm, status, ierr)
CALL MPI_RECV(buf2, count, MPI_REAL, 0, tag1, comm, status, ierr)
END IF
Оба процесса начинают их первый коммуникационный вызов.Поскольку первая посылка процесса нуль использует буферизованный режим, она обязана завершиться безотносительно к состоянию процесса один. Поскольку никакого соответствующего приема не инициировано, сообщение будет скопировано в буферное пространство. (Если буферного пространства недостаточно, программа не может выполняться дальше). Затем начинается вторая посылка. На этот момент соответствующая пара операций приема и посылки запущена и обе операции обязаны завершиться. Процесс один затем вызывает свою вторую операцию приема, которая получит буферизованное сообщение. Заметим, что процесс один получает сообщения в порядке, обратном порядку их передачи.
Однозначность (Fairness). MPI не гарантирует однозначности выполнения коммуникаций. Предположим, что посылка инициирована. Тогда возможно, что процесс-получатель повторно инициирует прием, соответствующий этой посылке, хотя сообщение все еще не принято, поскольку оно всякий раз обгоняется другим сообщением, посланным другим источником. Аналогично, предположим, что прием был установлен многопоточным процессом. Тогда возможно, что сообщения, соответствующие этому приему, принимаются повторно, хотя прием все еще не закрыт, поскольку он обгоняется другими приемами, установленными на этом узле (другими выполняемыми ветвями.). Предупредить зависание в такой ситуации является обязанностью программиста.
Ограничение по ресурсам (Resource limitations). Любое выполнение операций обмена предполагает наличие ресурсов, которые, однако, могут быть ограниченными. Может возникнуть ошибка, когда недостаток ресурсов ограничивает выполнение вызова. Хорошая реализация MPI должна обеспечивать фиксированный объем ресурсов для каждой ждущей посылки в режиме готовности или синхронном режиме и для каждого ждущего приема. Однако, буферное пространство может быть израсходовано на хранение сообщений, посланных в стандартном режиме, или занято для хранения сообщений, посланных в буферном режиме, когда прием для соответствующей пары недоступен. В таких случаях объем пространства, доступного для буферизации, будет намного меньше, чем объем памяти для данных на многих системах.
MPI позволяет пользователю обеспечить буферную память для сообщений, посланных в буферизованном режиме. Более того, MPI описывает детализированную операционную модель для использования этого буфера. От реализации MPI требуется, чтобы она не ухудшила возможности, предоставляемые этой моделью. Это позволяет пользователям избегать переполнений буфера, когда они используют буферизованные передачи. Распределение и использование буферов описано в разделе 3.6.
Операции буферизованной передачи, которые не могут завершиться из-за недостатка буферного пространства, являются неверными. Когда такая ситуация выявлена, появляется сигнал об ошибке, и это может вызвать ненормальное окончание программы. С другой стороны, операция стандартной посылки, которая не может завершиться из-за недостатка буферного пространства, будет просто блокирована, ожидая, когда освободится буферное пространство или будет установлен соответствующий прием. Это поведение предпочтительно во многих ситуациях. Рассмотрим ситуацию, в которой поставщик многократно генерирует новые значения и посылает их потребителю. Предположим, что генерация производится быстрее, чем потребитель может принять их. Если используются буферизованные посылки, то результатом станет перегрузка буфера. Чтобы предупредить такую ситуацию, в программу необходимо ввести дополнительную синхронизацию. Если используются стандартные передачи, то производитель будет автоматически следовать за блокированием его операций из-за недостатка буферного пространства.
В некоторых ситуациях недостаток буферного пространства ведет к дедлоку. Это иллюстрируется примером ниже.
Пример 3.7 Обмен сообщениями.
CALL MPI_COMM_RANK(comm, rank, ierr)
IF (rank.EQ.0) THEN
CALL MPI_SEND(sendbuf, count, MPI_REAL, 1, tag, comm, ierr)
CALL MPI_RECV(recvbuf, count, MPI_REAL, 1, tag, comm, status, ierr)
ELSE ! rank.EQ.1
CALL MPI_RECV(recvbuf, count, MPI_REAL, 0, tag, comm, status, ierr)
CALL MPI_SEND(sendbuf, count, MPI_REAL, 0, tag, comm, ierr)
END IF
Эта программа будет успешной, даже если не хватит буферного пространства для данных. Операция стандартной передачи данных в этом примере может быть заменена синхронной передачей.
Пример 3.8 Попытка обмена сообщениями.
CALL MPI_COMM_RANK(comm, rank, ierr)
IF (rank.EQ.0) THEN
CALL MPI_RECV(recvbuf, count, MPI_REAL, 1, tag, comm, status, ierr)
CALL MPI_SEND(sendbuf, count, MPI_REAL, 1, tag, comm, ierr)
ELSE ! rank.EQ.1
CALL MPI_RECV(recvbuf, count, MPI_REAL, 0, tag, comm, status, ierr)
CALL MPI_SEND(sendbuf, count, MPI_REAL, 0, tag, comm, ierr)
END IF
Операция приема первого процесса обязана завершиться перед его посылкой и может завершиться только в том случае, если выполнена соответствующая посылка второго процесса. Операция приема второго процесса обязана завершиться перед его посылкой и может завершиться только тогда, когда выполнена соответствующая посылка первого процесса. Эта программа всегда будет находиться в состоянии взаимного блокирования. То же самое справедливо для любых других режимов передачи.
Пример 3.9 Обмен, который зависит от буферизации.
CALL MPI_COMM_RANK(comm, rank, ierr)
IF (rank.EQ.0) THEN
CALL MPI_SEND(sendbuf, count, MPI_REAL, 1, tag, comm, ierr)
CALL MPI_RECV(recvbuf, count, MPI_REAL, 1, tag, comm, status, ierr)
ELSE ! rank.EQ.1
CALL MPI_SEND(sendbuf, count, MPI_REAL, 0, tag, comm, ierr)
CALL MPI_RECV(recvbuf, count, MPI_REAL, 0, tag, comm, status, ierr)
END IF
Сообщение, посланное каждым процессом, должно быть скопировано перед окончанием операции посылки и до старта операции приема. Чтобы завершить программу, необходимо, чтобы по крайней мере одно из двух сообщений было буферизовано. Поэтому программа может быть буферизованной только в случае, если коммуникационная система может буферизовать по крайней мере count слов данных.
Совет пользователям: Когда используется стандартная операция посылки, могут возникать тупиковые ситуации, когда оба процесса блокированы из-за недоступности буферного пространства. То же самое будет случаться, если используется синхронный режим. Если используется буферизованный режим и недостаточно буферного пространства, программа также не будет завершена. Однако, это будет не дедлок , а ошибка переполнения буфера.
Программа ``защищена'', если никакое буферизуемое сообщение не требует прекращения программы. В такой программе можно все посылки заменить синхронными передачами. Этот консервативный стиль программирования обеспечивает наилучшую переносимость программ, поскольку завершение программы не зависит от количества доступного буферного пространства или используемого коммуникационного протокола.
Многие программисты предпочитают иметь больше свободы действий и иметь возможность использовать ``незащищенный'' программный стиль, показанный в примере 3.9. В таком случае использование стандартных посылок должно обеспечить наилучший компромисс между характеристиками и надежностью: хорошие реализации будут обеспечивать достаточную буферизацию, чтобы программа, как правило, была без дедлоков. Буферизованный режим передачи может быть использован для программ, которые требуют больше буферизации или в ситуации, где программист желает иметь больше возможностей управления. Этот режим также может быть использован для целей отладки, так как условия переполнения буфера диагностировать легче, чем определить наличие дедлока.
Неблокируемые операции обмена, как описано в разделе 3.7, можно использовать, чтобы избежать необходимости буферизации исходящих сообщений. Это предупреждает дедлоки из-за недостатка буферного пространства и улучшает характеристики, поскольку позволяет совмещать вычисления и обмен и исключает накладные расходы на распределение буферов и копирование сообщений в буфера.[]
Пользователь может описать буфер, используемый для буферизации сообщений, посылаемых в режиме буферизации. Буферизация выполняется отправителем.
Синтаксис функции MPI_BUFFER_ATTACH представлен ниже.
MPI_BUFFER_ATTACH (buffer, size)
| IN | buffer | начальный адрес буфера (альтернатива) | |
| IN | size | размер буфера, в байтах (целое) |
int MPI_Buffer_attach (void* buffer, int size) MPI_BUFFER_ATTACH (BUFFER, SIZE, IERROR) <type> BUFFER(*) INTEGER SIZE, IERROR void MPI::Attach_buffer(void* buffer, int size)
Предусмотренный в MPI буфер в памяти пользователя используется для буферизации исходящих сообщений. Буфер используется только сообщениями, посланными в буферизованном режиме. За одну операцию к процессу может быть присоединен только один буфер.
Синтаксис функции MPI_BUFFER_DETACH представлен ниже.
MPI_BUFFER_DETACH(buffer_addr, size)
| OUT | buffer_addr | Начальный адрес буфера (альтернатива) | |
| OUT | size | Размер буфера, в байтах (целое) |
int MPI_Buffer_detach(void* buffer_addr, int* size) MPI_BUFFER_DETACH(BUFFER_ADDR, SIZE, IERROR) <type> BUFFER_ADDR(*) INTEGER SIZE, IERROR int MPI :: Detach_buffer (void*& buffer)
Отключение буфера операционно связано с MPI. Вызов возвращает адрес и размер отключенного буфера. Эта операция будет блокирована, пока находящееся в буфере сообщение не будет передано. После выполнения этой функции пользователь может повторно использовать или перераспределять объем памяти, занятый буфером.
Пример 3.10 Обращения к функциям подключения и отключения буферов.
#define BUFFSIZE 10000 int size char *buff; MPI_Buffer_attach(malloc(BUFFSIZE), BUFFSIZE); /* буфер на 10000 байтов может теперь быть использован MPI_Bsend */ MPI_Buffer_detach(&buff, &size); /* размер буфера уменьшен до нуля */ MPI_Buffer_attach(buff, size); /* буфер на 10000 байтов доступен снова */
Совет пользователям: Хотя для языка Си функции MPI_Buffer_attach и MPI_Buffer_detach имеют для первого аргумента тип void*, эти аргументы используются различно: при вызове MPI_Buffer_attach передается указатель (pointer) на буфер; а при вызове MPI_Buffer_detach - адрес указателя на буфер, так что этот вызов может возвращать значение указателя.[]
Объяснение: Оба аргумента определены типом void* (а не void* и void** соответственно), чтобы избежать сложностей приведения типов. Например, в последнем примере &buff, который имеет тип char**, может быть передан как аргумент MPI_Buffer_detach без приведения типов. Если формальный параметр имеет тип void**, тогда было бы нужно выполнить приведение типов перед и после вызова.[]
Утверждения, сделанные в этом разделе, описывают поведение MPI для буферизованного режима посылок. Если никакого буфера не подключено, то MPI ведет себя, как если бы с процессом был связан буфер нулевого размера.
MPI обязан обеспечить столько буферного пространства для исходящих сообщений, сколько нужно было бы, если бы посылающий процесс буферизовал исходящие сообщения в специальном буфере с непрерывным размещением. Ниже очерчена модельная реализация, которая определяет эту методику. MPI может обеспечить больше буферизации и может использовать алгоритм лучшего буферного распределения, чем описано ниже. С другой стороны, MPI может сообщать об ошибке, когда простое распределение, описанное ниже, выполнялось бы за пределами буферного пространства. В частности, если никакого буфера явно не связано с процессом, тогда любая буферизованная передача может вызывать ошибку.
MPI не обеспечивает механизма для установления очереди или управления буферизацией, сделанной посылками в стандартном режиме. Предполагается, что поставщики обеспечат такую информацию для их реализаций.
Объяснение: Имеется широкий спектр возможных реализаций буферизуемых обменов: буферизация может быть реализована на стороне отправителя, на стороне получателя или на обеих сторонах; буферы могут быть предназначены одной приемо-передающей паре или разделяться всеми обменами; буферизация может быть сделана в реальной или виртуальной памяти; она может использовать специально выделенную память или память, разделяемую другими процессами; буферное пространство может быть выделено статически или изменяться динамически; и так далее. Поэтому не очевидна возможность обеспечить переносимый механизм для управления очередностью и буферизацией, который был бы совместим со всеми этими вариантами.[]
Модель реализации использует функции упаковки и распаковки, описанные в разделе 3.13, и функции неблокируемого обмена из раздела 3.7.
Мы полагаем, что поддерживается круговая очередь ждущих элементов сообщений (pending message entries (PME)). Каждый входной элемент содержит запрос на обработку, который идентифицирует ждущую неблокирующую передачу, указатель на следующий элемент и упакованные данные сообщения. Элементы хранятся в последовательных ячейках буфера. Свободное пространство доступно между хвостом и головой очереди.
Вызов буферизованной посылки реализуется исполнением следующего алгоритма:
На многих системах можно улучшить характеристики путем совмещения во времени процессов обмена и вычислений. Это особенно актуально для систем, где обмен может быть выполнен автономно с помощью интеллектуального коммуникационного контроллера. Потоки, разделяющие единственный ресурс, являются одним из механизмов для достижения такого совмещения. Альтернативным механизмом, который часто приводит к лучшим характеристикам, является неблокирующий обмен. Неблокирующий вызов send start (начало посылки) инициирует операцию посылки, но не завершает ее. Вызов ``начало посылки'' будет возвращать управление перед тем, как сообщение будет послано из буфера отправителя. Отдельный вызов send complete (завершение посылки) необходим, чтобы завершить обмен, то есть чтобы убедиться, что данные уже извлечены из буфера отправителя. При подходящем оборудовании посылка данных из памяти отправителя может выполняться параллельно с вычислениями, выполняемыми на процессе-отправителе после того, как передача была инициирована и до ее завершения. Аналогично, неблокирующий вызов receive start (начало приема) инициирует операцию приема, но не завершает ее. Вызов будет закончен до записи сообщения в приемный буфер. Необходимо выполнить отдельный вызов receive complete (завершение приема), чтобы завершить операцию приема и проверить, что данные получены в приемный буфер. С подходящим оборудованием посылка данных в память получателя может выполняться параллельно с вычислениями, производимыми после того, как прием был инициирован и до его завершения. Использование неблокируемого приема позволит также избежать системной буферизации и копирования память-память, когда информация появилась преждевременно на приемном буфере.
Неблокируемые вызовы начала посылки могут использовать те же самые четыре режима, что и блокируемые передачи: стандартный, буферизуемый, синхронный и по готовности с сохранением их семантики. Передачи во всех режимах, исключая режим по готовности, могут стартовать вне зависимости от того, был ли инициирован соответствующий прием; неблокируемая посылка по готовности может быть начата , только если инициирован соответствующий прием. Во всех случаях вызов начала посылки является локальным: он заканчивается немедленно, безотносительно к состоянию других процессов. Если при вызове обнаруживается нехватка некоторых системных ресурсов, тогда он не может быть выполнен и возвращает код ошибки. Реализация MPI должна гарантировать, что это случается только в ``патологических'' случаях. Это означает, что реализация MPI должна быть способной поддерживать большое число ждущих неблокирующих операций.
Вызов завершения посылки заканчивается, когда данные извлечены из буфера отправителя. Этот факт может иметь дополнительный смысл в зависимости от режима передачи.
Если режим передачи синхронный, тогда передача может завершиться только, если соответствующий прием стартовал, то есть, прием инициирован и соответствует передаче. В этом случае вызов send-complete является нелокальным. Заметим, что синхронная неблокирующая передача может быть завершена, если перед вызовом receive complete имеет место соответствующий неблокирующий прием. (Он может завершиться сразу, как только отправитель ``узнает'', что передача будет завершена, но перед тем, как приемник ``узнает'', что передача будет завершена).
Если используется режим буферизуемой передачи, то сообщение должно быть буферизовано, если не имеется ждущего приема. В этом случае вызов send-complete является локальным и обязан быть успешным независимо от состояния соответствующего приема.
Если используется стандартный режим передачи, тогда вызов send-complete может заканчиваться перед тем, как выполняется соответствующий прием, если сообщение буферизованное. С другой стороны, send-complete может не завершаться до тех пор, пока имеет место соответствующий прием и сообщение было скопировано в приемный буфер.
Неблокирующие передачи могут соответствовать блокирующим приемам и наоборот.
Совет пользователям: Завершение операции посылки может быть задержано для стандартного режима и обязано быть задержано для синхронного режима, пока не инициирован соответствующий прием. Использование неблокирующих передач в этих двух случаях позволяет отправителю работать, опережая процесс-получатель, так что вычисления менее зависимы от флуктуаций скорости двух процессов.
Неблокирующие посылки в буферизованном режиме и режиме готовности дают ограниченный эффект. Неблокирующая посылка будет заканчиваться так скоро, как возможно, в то время как блокирующая посылка будет закончена после того, как данные будут извлечены из памяти отправителя. Использование неблокирующих передач имеет преимущество только в тех случаях, когда копирование данных может быть совмещено с вычислениями.
Модель передачи сообщений приводит к модели, в которой коммуникации инициируются отправителем. Обмен в общем будет иметь низкие накладные расходы, если прием уже установлен к моменту, когда отправитель инициирует обмен (данные могут быть перемещены прямо в приемный буфер и нет необходимости иметь очередь ждущих требований на посылку). Однако, операция приема может быть завершена только после того, как соответствующая посылка была совершена. Использование неблокирующего приема позволяет достичь низких затрат без блокирования приема, когда он ждет посылки.[]
Неблокирующие обмены используют скрытые запросы (request), чтобы идентифицировать операции обмена и сопоставить операцию, которая инициирует обмен с операцией, которая заканчивает его. Они являются системными объектами, которые становятся доступными в процессе обработки. Объект запроса указывает различные свойства операции обмена, например, такие, как режим передачи, связанный с ней буфер обмена, ее контекст, тэг и номер процесса-приемника, которые используются для посылки сообщения, или тэг и номер процесса-отправителя, которые используются для приема. Дополнительно этот объект хранит информацию о состоянии ждущих операций обмена.
Далее используются те же обозначения, что и для блокирующего обмена: префикс B, S, или R используются соответственно для буферизованного, синхронного режима или режима готовности. Дополнительный префикс I (immediate - непосредственный) указывает, что вызов неблокирующий.
Синтаксис функции MPI_ISEND представлен ниже.
MPI_ISEND(buf, count, datatype, dest, tag, comm, request)
| IN | buf | начальный адрес буфера посылки (альтернатива) | |
| IN | count | число элементов в буфере посылки (целое) | |
| IN | datatype | тип каждого элемента в буфере посылки (дескриптор) | |
| IN | dest | номер процесса-получателя (целое) | |
| IN | tag | тэг сообщения (целое) | |
| IN | comm | коммуникатор (дескриптор) | |
| OUT | request | запрос обмена (дескриптор) |
int MPI_Isend(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request) MPI_ISEND (BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR) <type> BUF(*) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR MPI::Request Comm::Isend(const void* buf, int count, const MPI::Datatype& datatype, int dest, int tag) const
Синтаксис функции MPI_IBSEND представлен ниже.
MPI_IBSEND(buf, count, datatype, dest, tag, comm, request)
| IN | buf | начальный адрес буфера посылки (альтернатива) | |
| IN | count | число элементов в буфере посылки (целое) | |
| IN | datatype | тип каждого элемента в буфере посылки (дескриптор) | |
| IN | dest | номер процесса-получателя (целое) | |
| IN | tag | тэг сообщения (целое) | |
| IN | comm | коммуникатор (дескриптор) | |
| OUT | request | запрос обмена (дескриптор) |
int MPI_Ibsend (void* buf, int count, MPI_Datatype datatype,
int dest, int tag, MPI_Comm comm, MPI_Request *request)
MPI_IBSEND (BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR)
<type> BUF(*)
INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR
MPI::Request MPI::Comm::Ibsend(const void* buf, int count,
const MPI::Datatype& datatype, int dest, int tag) const
Синтаксис функции MPI_ISSEND представлен ниже.
MPI_ISSEND (buf, count, datatype, dest, tag, comm, request)
| IN | buf | начальный адрес буфера посылки (альтернатива) | |
| IN | count | число элементов в буфере посылки (целое) | |
| IN | datatype | тип каждого элемента в буфере посылки (дескриптор) | |
| IN | dest | номер процесса-получателя (целое) | |
| IN | tag | тэг сообщения (целое) | |
| IN | comm | коммуникатор (дескриптор) | |
| OUT | request | запрос обмена (дескриптор) |
int MPI_Issend (void* buf, int count, MPI_Datatype datatype,
int dest, int tag, MPI_Comm comm, MPI_Request *request)
MPI_ISSEND (BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR)
<type> BUF(*)
INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR
MPI::Request MPI::Comm::Issend(const void* buf, int count,
const MPI::Datatype& datatype, int dest, int tag) const
Синтаксис функции MPI_IRSEND представлен ниже.
MPI_IRSEND(buf, count, datatype, dest, tag, comm, request)
| IN | buf | начальный адрес буфера посылки (альтернатива) | |
| IN | count | число элементов в буфере посылки (целое) | |
| IN | datatype | тип каждого элемента в буфере посылки (дескриптор) | |
| IN | dest | номер процесса-получателя (целое) | |
| IN | tag | тэг сообщения (целое) | |
| IN | comm | коммуникатор (дескриптор) | |
| OUT | request | запрос обмена (дескриптор) |
int MPI_Irsend(void* buf, int count, MPI_Datatype datatype,
int dest, int tag, MPI_Comm comm, MPI_Request *request)
MPI_IRSEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR)
<type> BUF(*)
INTEGER COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR
MPI::Request MPI::Comm::Irsend(const void* buf, int count,
const MPI::Datatype& datatype, int dest, int tag) const
Синтаксис функции MPI_IRECV представлен ниже.
MPI_IRECV(buf, count, datatype, source, tag, comm, request)
| IN | buf | начальный адрес буфера посылки (альтернатива) | |
| IN | count | число элементов в буфере посылки (целое) | |
| IN | source | тип каждого элемента в буфере посылки (дескриптор) | |
| IN | dest | номер процесса-получателя (целое) | |
| IN | tag | тэг сообщения (целое) | |
| IN | comm | коммуникатор (дескриптор) | |
| OUT | request | запрос обмена (дескриптор) |
int MPI_Irecv(void* buf, int count, MPI_Datatype datatype,
int source, int tag, MPI_Comm comm, MPI_Request *request)
MPI_IRECV(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR)
<type> BUF(*)
INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR
MPI::Request MPI::Comm::Irecv(void* buf, int count,
const MPI::Datatype& datatype, int source, int tag) const
Эти вызовы создают объект коммуникационного запроса и связывают его с дескриптором запроса (аргумент request). Запрос может быть использован позже, чтобы узнать статус обмена или чтобы ждать его завершения.
Неблокирующий вызов посылки указывает, что система может стартовать, копируя данные из буфера отправителя. Отправитель не должен обращаться к любой части буфера посылки после того, как вызвана операция неблокируемой передачи, пока посылка не завершится.
Неблокирующий прием указывает, что система может стартовать, записывая данные в приемный буфер. Приемник не должен обращаться в любую часть приемного буфера после того, как вызвана операция неблокируемого приема, пока прием не завершен.
Совет пользователям: Чтобы предупредить проблему копирования аргументов и оптимизации регистров, выполняемую компиляторами языка ФОРТРАН, следует обратить внимание на советы в разделе 10.2.2 MPI-2.[]
Чтобы завершить неблокирующий обмен, используются функции MPI_WAIT и MPI_TEST. Завершение операции посылки указывает, что отправитель теперь может изменять содержимое ячеек буфера посылки (операция посылки сама не меняет содержание буфера). Операция завершения не извещает, что сообщение было получено, но дает сведения, что оно было буферизовано коммуникационной подсистемой. Однако, если был использован синхронный режим, завершение операции посылки указывает, что соответствующий прием был инициирован и что это сообщение будет в конечном итоге принято этим соответствующим получателем.
Завершение операции приема указывает, что приемный буфер содержит принятое сообщение, что процесс-получатель теперь может обращаться к нему и что статусный объект установлен. Это не означает, что операция посылки завершена (но указывает, конечно, что посылка была инициирована).
Далее будет использоваться следующая терминология: нулевой дескриптор
есть дескриптор со значением MPI_REQUEST_NULL. Персистентный (persistent) запрос и дескриптор на него неактивны,
если запрос не связан с любым продолжающимся обменом (см. раздел 3.9).
Дескриптор является активным, если он не является нулевым или неактивным.
Состояние пусто (empty) - это состояние, которое установлено, чтобы
возвратить tag = MPI_ANY_TAG, source = MPI_ANY_SOURCE,
error = MPI_SUCCESS, и внутренне
сконфигурировано так, чтобы вызовы MPI_GET_COUNT и
MPI_GET_ELEMENTS возвращали count = 0 и MPI_TEST_CANCELLED возвращал false. Переменная состояния
устанавливается на empty, когда возвращаемое ею значение
несущественно. Состояние устанавливается таким образом, чтобы предупредить
ошибки из-за устаревшей информации.
Синтаксис функции MPI_WAIT представлен ниже.
MPI_WAIT(request, status)
| INOUT | request | запрос (дескриптор) | |
| OUT | status | объект состояния (статус) |
int MPI_Wait(MPI_Request *request, MPI_Status *status) MPI_WAIT(REQUEST, STATUS, IERROR) INTEGER REQUEST, STATUS(MPI_STATUS_SIZE), IERROR void MPI::Request::Wait(MPI::Status& status) void MPI::Request::Wait()
Обращение к MPI_WAIT заканчивается, когда завершена операция, указанная в запросе. Если коммуникационный объект, связанный с этим запросом, был создан вызовом неблокирующей посылки или приема, тогда этот объект удаляется при обращении к MPI_WAIT и дескриптор запроса устанавливается в MPI_REQUEST_NULL. MPI_WAIT является нелокальной операцией.
Вызов возвращает в status информацию о завершенной операции. Содержание статусного объекта для приемной операции может быть получено способом, описанным в разделе 3.2.5. Статусный объект для операции посылки может быть поставлен в очередь обращением к MPI_TEST_CANCELLED (см. раздел 3.8).
Разрешается вызывать MPI_WAIT с нулевым или неактивным аргументом запроса. В этом случае операция заканчивается немедленно со статусом empty.
Совет пользователям: Успешное завершение вызова MPI_WAIT после MPI_IBSEND подразумевает, что пользовательский буфер посылки может использоваться повторно, то есть что данные уже извлечены или скопированы в буфер, подключенный по MPI_BUFFER_ATTACH. Заметим, что с этого момента мы не можем дольше отменять посылку (см. раздел 3.8). Если соответствующий прием никогда не инициируется, тогда буфер не может быть освобожден. При этом необходимо запустить нечто вроде счетчика для вызова MPI_CANCEL (всегда способен освободить программное пространство, переданное коммуникационной подсистеме).[]
Совет разработчикам: В многопоточной среде обращение к MPI_WAIT должно блокировать только вызываемый поток, позволяя планировщику потоков планировать для исполнения другой поток.[]
Синтаксис функции MPI_TEST представлен ниже.
MPI_TEST(request, flag, status)
| INOUT | request | коммуникационный запрос (дескриптор) | |
| OUT | flag | true, если операция завершена (логический тип) | |
| OUT | status | статусный объект (статус) |
int MPI_Test(MPI_Request *request, int *flag, MPI_Status *status) MPI_TEST(REQUEST, FLAG, STATUS, IERROR) LOGICAL FLAG INTEGER REQUEST, STATUS(MPI_STATUS_SIZE), IERROR bool MPI::Request::Test(MPI::Status& status) bool MPI::Request::Test()
Обращение к MPI_TEST возвращает flag = true, если операция, указанная в запросе, завершена. В этом случае статусный объект содержит информацию о завершенной операции; если коммуникационный объект был создан неблокирующей посылкой или приемом, то он входит в состояние дедлока и обработка запроса устанавливается в MPI_REQUEST_NULL. Другими словами, вызов возвращает flag = false. В этом случае значение статуса не определено. MPI_TEST является локальной операцией.
Возвращенный статус для операции приема несет информацию, которая может быть получена способом, описанным в разделе 3.2.5. Статусный объект для операции посылки несет информацию, которая может быть получена обращением к MPI_TEST_CANCELLED (см. раздел 3.8).
Можно вызывать MPI_TEST с нулевым или неактивным аргументом запроса. В таком случае операция возвращает flag = true и empty для status.
Функции MPI_WAIT и MPI_TEST могут быть использованы как для завершения, так и для приема.
Совет пользователям: Использование неблокирующего вызова MPI_TEST позволяет пользователю планировать альтернативную активность внутри одиночного потока исполнения. Запускаемый по событиям планировщик потоков может быть эмулирован периодическими обращениями к MPI_TEST.[]
Объяснение: Функция MPI_TEST возвращает flag = true точно в момент, когда функция MPI_WAIT возвращает управление; в этом случае обе функции возвращают то же самое значение статуса. Следовательно, блокируемый Wait может быть легко замещен неблокируемым Test.[]
Пример 3.11 Простое использование неблокируемой операции и MPI_WAIT.
CALL MPI_COMM_RANK(comm, rank, ierr)
IF(rank.EQ.0) THEN
CALL MPI_ISEND(a(1), 10, MPI_REAL, 1, tag, comm, request, ierr)
**** do some computation to mask latency ****
CALL MPI_WAIT(request, status, ierr)
ELSE
CALL MPI_IRECV(a(1), 15, MPI_REAL, 0, tag, comm, request, ierr)
**** do some computation to mask latency ****
CALL MPI_WAIT(request, status, ierr)
END IF
Объект запроса может быть удален без ожидания завершения соответствующего обмена путем использования следующей операции MPI_REQUEST_FREE.
Синтаксис функции MPI_REQUEST_FREE представлен ниже.
MPI_REQUEST_FREE(request)
| INOUT | request | коммуникационный запросн (дескриптор) |
int MPI_Request_free(MPI_Request *request) MPI_REQUEST_FREE(REQUEST, IERROR) INTEGER REQUEST, IERROR void MPI::Request::Free()
Эта функция маркирует объект запроса для удаления и устанавливает запрос в состояние MPI_REQUEST_NULL. Продолжающейся коммуникации, которая связана с этим запросом, будет разрешено завершение. Запрос будет удален только после ее завершения.
Объяснение: Механизм MPI_REQUEST_FREE введен для повышения характеристик обмена и обеспечения удобства на стороне отправителя.[]
Совет пользователям: Как только запрос удаляется вызовом MPI_REQUEST_FREE, уже невозможно проверить успешное завершение соответствующего обмена обращением к MPI_WAIT или MPI_TEST. Если ошибка возникает позже в течение вызова, код ошибки не может быть возвращен пользователю - такая ошибка должна быть обработана как фатальная. Возникает вопрос, как узнать, когда операция завершена, когда используется MPI_REQUEST_FREE. В зависимости от логики программы могут быть другие пути, в которых программа знает, что определенные операции уже завершены и это делает использование MPI_REQUEST_FREE практичным. Например, активный запрос посылки можно было бы удалить, если логика программы такова, что приемник посылает ответ посланному сообщению - прибытие ответа информирует отправителя, что передача завершена и буфер отправителя может быть использован повторно. Активный запрос приема никогда не должен быть удален, так как процесс-получатель не будет иметь способа проверить, что прием завершен и приемный буфер свободен для нового использования.[]
Пример 3.12 Пример использования MPI_REQUEST_FREE.
CALL MPI_COMM_RANK(MPI_COMM_WORLD, rank)
IF(rank.EQ.0) THEN
DO i=1, n
CALL MPI_ISEND(outval, 1, MPI_REAL, 1, 0, req, ierr)
CALL MPI_REQUEST_FREE(req, ierr)
CALL MPI_IRECV(inval, 1, MPI_REAL, 1, 0, req, ierr)
CALL MPI_WAIT(req, status, ierr)
END DO
ELSE ! rank.EQ.1
CALL MPI_IRECV(inval, 1, MPI_REAL, 0, 0, req, ierr)
CALL MPI_WAIT(req, status)
DO I=1, n-1
CALL MPI_ISEND(outval, 1, MPI_REAL, 0, 0, req, ierr)
CALL MPI_REQUEST_FREE(req, ierr)
CALL MPI_IRECV(inval, 1, MPI_REAL, 0, 0, req, ierr)
CALL MPI_WAIT(req, status, ierr)
END DO
CALL MPI_ISEND(outval, 1, MPI_REAL, 0, 0, req, ierr)
CALL MPI_WAIT(req, status)
END IF
Семантика неблокирующих коммуникаций определена подходящим расширением определений в разделе 3.5.
Очередность. Операции неблокирующих коммуникаций упорядочены согласно порядку исполнения вызовов, которые инициируют обмен. Требование отсутствия обгона раздела 3.5 расширено на неблокирующий обмен.
Пример 3.13 Установление очереди для неблокирующих операций.
CALL MPI_COMM_RANK(comm, rank, ierr)
IF (RANK.EQ.0) THEN
CALL MPI_ISEND(a, 1, MPI_REAL, 1, 0, comm, r1, ierr)
CALL MPI_ISEND(b, 1, MPI_REAL, 1, 0, comm, r2, ierr)
ELSE ! rank.EQ.1
CALL MPI_IRECV(a, 1, MPI_REAL, 0, MPI_ANY_TAG, comm, r1, ierr)
CALL MPI_IRECV(b, 1, MPI_REAL, 0, 0, comm, r2, ierr)
END IF
CALL MPI_WAIT(r1,status)
CALL MPI_WAIT(r2,status)
Первая посылка процесса нуль будет соответствовать первому приему процесса один, даже если оба сообщения посланы до того, как процесс один выполнит тот или другой прием.
Продвижение обмена. Вызов MPI_WAIT, который завершает прием, будет в конечном итоге заканчиваться, если соответствующая посылка была начата и не закрыта другим приемом. В частности, если соответствующая посылка неблокирующая, тогда прием должен завершиться, даже если отправитель не выполняет никакого вызова, чтобы завершить передачу. Аналогично, обращение к MPI_WAIT, которое завершает посылку, будет в конечном итоге заканчиваться, если соответствующий прием инициирован (если прием не закрыт другой передачей, и даже если никакого обращения не выполняется, чтобы закрыть прием).
Пример 3.14 Илюстрация семантики продвижения.
CALL MPI_COMM_RANK(comm, rank, ierr)
IF (RANK.EQ.0) THEN
CALL MPI_SSEND(a, 1, MPI_REAL, 1, 0, comm, ierr)
CALL MPI_SEND(b, 1, MPI_REAL, 1, 1, comm, ierr)
ELSE ! rank.EQ.1
CALL MPI_IRECV(a, 1, MPI_REAL, 0, 0, comm, r, ierr)
CALL MPI_RECV(b, 1, MPI_REAL, 0, 1, comm, ierr)
CALL MPI_WAIT(r, status, ierr)
END IF
Этот код не имеет дедлока при правильной реализации MPI. Первая синхронная посылка процесса нуль обязана завершиться после того, как процесс один установит соответствующий (неблокирующий) прием , даже если процесс один не достиг еще завершения вызова wait. Поэтому процесс ноль будет продолжаться и выполнит вторую посылку, позволяя процессу один завершить передачу.
Если MPI_TEST, который завершает прием, вызывается повторно с тем же самым аргументом и соответствующая посылка стартовала, тогда вызов рано или поздно возвратит flag = true, если посылка не закрыта другим приемом. Если MPI_TEST, который завершает посылку, повторяется с тем же самым аргументом и соответствующий прием стартовал, тогда вызов рано или поздно возвратит flag = true, если не будет закрыт другой посылкой.
Удобно было бы иметь возможность ожидать завершения любой, определенной или всех операций в списке, а не ждать только специального сообщения.
Вызовы MPI_WAITANY или MPI_TESTANY можно использовать для ожидания завершения одной из нескольких операций.
Вызовы MPI_WAITALL или MPI_TESTALL могут быть использованы для всех ждущих операций в списке. Вызовы WAITSOME или MPI_TESTSOME можно использовать для завершения всех разрешенных операций в списке.
Синтаксис функции MPI_WAITANY представлен ниже.
MPI_WAITANY(count, array_of_requests, index, status)
| IN | count | длина списка (целое) | |
| INOUT | array_of_requests | массив запросов (массив десрипторов) | |
| OUT | index | индекс дескриптора для завершенной операции (целое) | |
| OUT | status | статусный объект (статус) |
int MPI_Waitany(int count, MPI_Request *array_of_requests,
int *index, MPI_Status *status)
MPI_WAITANY(COUNT, ARRAY_OF_REQUESTS, INDEX, STATUS, IERROR)
INTEGER COUNT, ARRAY_OF_REQUESTS(*), INDEX, STATUS(MPI_STATUS_SIZE), IERROR
static int MPI::Request::Waitany(int count,
MPI::Request array_of_requests[], MPI::Status& status)
static int MPI::Request::Waitany(int count,
MPI::Request array_of_requests[])
Операция блокирует работу до тех пор, пока не завершится одна из операций из массива активных запросов. Если более, чем одна операция задействована и может окончиться, выполняется произвольный выбор. Операция возвращает в index индекс этого запроса в массиве и возвращает в status статус завершаемого обмена. (Массив индексируется от нуля в языке Си и от единицы в языке ФОРТРАН).
Если запрос был создан операцией неблокирующего обмена, тогда он удаляется и дескриптор запроса устанавливается в MPI_REQUEST_NULL.
Список array_of_request может содержать нуль или неактивные дескрипторы. Если список не содержит активных дескрипторов (список имеет нулевую длину или все элементы являются нулями или неактивны), тогда вызов заканчивается немедленно с index = MPI_UNDEFINED и со статусом empty.
Выполнение MPI_WAITANY(count, array_of_requests, index, status) имеет тот же эффект, что и выполнение MPI_WAIT(&array_of_requests[i], status), где i есть значение, возвращенное в аргументе index (если значение index не MPI_UNDEFINED). MPI_WAITANY с массивом, содержащим один активный элемент, эквивалентно MPI_WAIT.
Синтаксис функции MPI_TESTANY представлен ниже.
MPI_TESTANY(count, array_of_requests, index, flag, status)
| IN | count | длина списка (целое) | |
| INOUT | array_of_requests | массив запросов (массив дескрипторов) | |
| OUT | index | индекс дескриптора для завершенной операции (целое) | |
| OUT | flag | true, если одна из операций завершена (логический тип) | |
| OUT | status | статусный объкт (статус) |
int MPI_Testany(int count, MPI_Request *array_of_requests,
int *index, int *flag, MPI_Status *status)
MPI_TESTANY(COUNT, ARRAY_OF_REQUESTS, INDEX, FLAG, STATUS, IERROR)
LOGICAL FLAG
INTEGER COUNT, ARRAY_OF_REQUESTS(*), INDEX, STATUS(MPI_STATUS_SIZE), IERROR
static bool MPI::Request::Testany(int count,
MPI::Request array_of_requests[], int& index, MPI::Status& status)
static bool MPI::Request::Testany(int count,
MPI::Request array_of_requests[], int& index)
Функция тестирует завершение либо одной, либо никакой из операций, связанных с активными дескрипторами. В первом случае она возвращает flag = true, индекс этого запроса в массиве index и статус этой операции в status; если запрос был создан вызовом неблокирующего обмена, тогда запрос удаляется и дескриптор устанавливается в MPI_REQUEST_NULL. (Массив индексируется от нуля в языке Си и от единицы в языке ФОРТРАН). В последнем случае (не завершено никакой операции) возвращается flag = false, значение MPI_UNDEFINED в index и состояние аргумента status является неопределенным.
Массив может содержать нуль или неактивные дескрипторы. Если массив не содержит активных дескрипторов, тогда вызов заканчивается немедленно с flag = true, index = MPI_UNDEFINED, и status = empty.
Если массив запросов содержит активные дескрипторы, тогда выполнение
MPI_TESTANY(count, array_of_requests, index, status) имеет
тот же самый эффект, что и выполнение
MPI_TEST(&array_of_requests[i], flag, status)
для i=0, 1, ..., count-1 в некотором произвольном порядке,
пока один вызов не возвратит flag = true, или все вызовы не могут быть
выполнены. В первом случае индекс устанавливается на последнее значение i,
и в последнем случае устанавливается в MPI_UNDEFINED.
MPI_TESTANY с массивом, содержащим один активный элемент,
эквивалентен MPI_TEST.
Объяснение: Функция MPI_TESTANY заканчивается с flag = true точно в момент, когда функция MPI_WAITANY возвращает управление ; обе функции возвращают в этом случае одинаковые значения остающихся параметров. Поэтому блокирующий вызов MPI_WAITANY может быть легко замещен неблокирующим MPI_TESTANY. Те же отношения сохраняются и для других пар функций Wait и Test, определенных в этом разделе.[]
Синтаксис функции MPI_WAITALL представлен ниже.
MPI_WAITALL(count, array_of_requests, array_of_statuses)
| IN | count | длина списков (целое) | |
| INOUT | array_of_requests | массив запросов (массив дескрипторов) | |
| OUT | array_of_statuses | массив статусных объектов (массив статусов) |
int MPI_Waitall (int count, MPI_Request *array_of_requests,
MPI_Status *array_of_statuses)
MPI_WAITALL(COUNT, ARRAY_OF_REQUESTS, ARRAY_OF_STATUSES, IERROR)
INTEGER COUNT, ARRAY_OF_REQUESTS(*)
INTEGER ARRAY_OF_STATUSES(MPI_STATUS_SIZE,*), IERROR
static void MPI::Request::Waitall (int count,
MPI::Request array_of_requests[], MPI::Status array_of_statuses[])
static void MPI::Request::Waitall (int count,
MPI::Request array_of_requests[])
Функция блокирует работу, пока все операции обмена, связанные с активными дескрипторами в списке, не завершатся, и возвращает статус всех операций (это включает случай, когда в списке нет активных дескрипторов). Оба массива имеют то же самое количество элементов. Элемент с номером i в array_of_statuses устанавливается в возвращаемый статус i-ой операции. Запросы, созданные операцией неблокирующего обмена, удаляются и соответствующие дескрипторы устанавливаются в MPI_REQUEST_NULL. Список может содержать нуль или неактивные дескрипторы. Вызов устанавливает статус каждого такого элемента в состояние empty.
Если ошибок нет, то вызов MPI_WAITALL(count, array_of_requests, array_of_statuses) имеет тот же эффект, что и вызов MPI_WAIT(&array_of_request[i], &array_of_statuses[i]) для i=0, ..., count-1 в некотором произвольном порядке. MPI_WAITALL с массивом длины один эквивалентен MPI_WAIT.
Когда один или более обменов, завершенных обращением к MPI_WAITALL, оказались неудачны, желательно возвратить специальную информацию по каждому обмену. Функция MPI_WAITALL возвращает в таком случае код MPI_ERR_IN_STATUS и устанавливает в поля ошибки каждого статуса специфический код ошибки. Этот код равен MPI_SUCCESS, если обмен завершен, или другому коду, если обмен не состоялся; он может иметь значение MPI_ERR_PENDING, если он и не завершен, и не в состоянии отказа. Функция MPI_WAITALL будет возвращать MPI_SUCCESS, если никакой из запросов не вызвал ошибку или будет возвращать специальный код ошибки, если запрос не выполнился по другим причинам (таким, как неверный аргумент). В таком случае функция не будет корректировать поле ошибки в статусе.
Объяснение: Стандарт упрощает обработку ошибок в приложениях. Прикладному коду нужно только проверить результат функции (единственный), чтобы выяснить, есть ли ошибка. Ему необходимо проверить каждый индивидуальный статус только в том случае, когда ошибка есть.[]
Синтаксис функции MPI_TESTALL представлен ниже.
MPI_TESTALL(count, array_of_requests, flag, array_of_statuses)
| IN | count | длина списка (целое) | |
| INOUT | array_of_requests | массив запросов (массив дескрипторов) | |
| OUT | flag | (логический тип) | |
| OUT | array_of_statuses | массив статусных объектов(массив статусов) |
int MPI_Testall(int count, MPI_Request *array_of_requests,
int *flag, MPI_Status *array_of_statuses)
MPI_TESTALL(COUNT, ARRAY_OF_REQUESTS, FLAG, ARRAY_OF_STATUSES, IERROR)
LOGICAL FLAG
INTEGER COUNT, ARRAY_OF_REQUESTS(*),
ARRAY_OF_STATUSES(MPI_STATUS_SIZE,*), IERROR
static bool MPI::Request::Testall(int count,
MPI::Request array_of_requests[], MPI::Status array_of_statuses[])
static bool MPI::Request::Testall(int count, MPI::Request array_of_requests[])
Функция возвращает flag = true, если обмены, связанные с активными дескрипторами в массиве, завершены (это включает случай, когда в списке нет активных дескрипторов). В этом случае каждый статусный элемент, который соответствует активному дескриптору, устанавливается в статус соответствующего обмена; если запрос был создан вызовом неблокирующего обмена, то он удаляется и дескриптор устанавливается в MPI_REQUEST_NULL. Каждый статусный элемент, который соответствует нулю или неактивному дескриптору, устанавливается в состояние empty.
В противном случае возвращается flag = false, никакие запросы не модифицируются и значения статусных элементов неопределенные. Операция является локальной.
Ошибки, которые имеют место при выполнении MPI_TESTALL, обрабатываются также, как и в случае MPI_WAITALL.
Синтаксис функции MPI_WAITSOME представлен ниже.
MPI_WAITSOME (incount, array_of_requests, outcount,
array_of_indices, array_of_statuses)
| IN | incount | длина массива запросов (целое) | |
| INOUT | array_of_requests | массив запросов (массив дескрипторов) | |
| OUT | outcount | число завершенных запросов (целое) | |
| OUT | array_of_indices | массив индексов операций, которые завершены (мас-сив целых) | |
| OUT | array_of_statuses | массив статусных операций для завершенных опера-ций (массив статусов) |
int MPI_Waitsome (int incount, MPI_Request *array_of_requests,
int *outcount, int *array_of_indices, MPI_Status *array_of_statuses)
MPI_WAITSOME (INCOUNT, ARRAY_OF_REQUESTS, OUTCOUNT, ARRAY_OF_INDICES,
ARRAY_OF_STATUSES, IERROR)
INTEGER INCOUNT, ARRAY_OF_REQUESTS(*), OUTCOUNT, ARRAY_OF_INDICES(*),
ARRAY_OF_STATUSES(MPI_STATUS_SIZE,*), IERROR
static int MPI::Request::Waitsome(int incount,
MPI::Request array_of_requests[], int array_of_indices[],
MPI::Status array_of_statuses[])
static int MPI::Request::Waitsome(int incount,
MPI::Request array_of_requests[], int array_of_indices[ ])
Функция ожидает, пока по крайней мере одна операция, связанная с активным дескриптором в списке, не завершится. Она возвращает в outcount число зопросов из списка array_of_indices, которые завершены. В первую outcount ячейку массива array_of_indices возвращаются индексы этих операций (индекс внутри array_of_requests; массив индексируется от нуля в языке Си и от единицы в языке ФОРТРАН). В первую ячейку outcount массива array_of_status поступает статус этих завершенных операций. Если завершенный запрос был создан вызовом неблокирующего обмена, то он удаляется и связанный дескриптор устанавливается в MPI_REQUEST_NULL.
Если список не содержит активных дескрипторов, то вызов заканчивается немедленно со значением outcount = MPI_UNDEFINED.
Если один или более обменов, завершенных MPI_WAITSOME, не могут быть выполнены, то надо возвращать по каждому обмену специфическую информацию. При этом аргументы outcount, array_of_indices и array_of_statuses будут индицировать завершение всех обменов, успешных или неуспешных. Вызов будет возвращать код ошибки MPI_ERR_IN_STATUS и устанавливать поле ошибки каждого возвращенного статуса, чтобы указать на успешное завершение или возвратить специфический код ошибки. Вызов будет возвращать MPI_SUCCESS, если ни один запрос не содержал ошибки, и будет возвращен специальный код ошибки, если запрос не может быть выполнен по какой-то причине (такой, как неправильный аргумент). В таких случаях поля ошибок статуса не будут корректироваться.
Синтаксис функции MPI_TESTSOME представлен ниже.
MPI_TESTSOME(incount, array_of_requests, outcount,
array_of_indices, array_of_statuses)
| IN | incount | длина массива запросов (целое) | |
| INOUT | array_of_requests | массив запросов(массив дескрипторов) | |
| OUT | outcount | число завершенных запросов (целое) | |
| OUT | array_of_indices | массив индексов завершенных операций (массив целых) | |
| OUT | array_of_statuses | массив статусных объектов завешенных операций (массив статусов) |
int MPI_Testsome(int incount, MPI_Request *array_of_requests,
int *outcount, int *array_of_indices, MPI_Status *array_of_statuses)
MPI_TESTSOME(INCOUNT, ARRAY_OF_REQUESTS, OUTCOUNT, ARRAY_OF_INDICES,
ARRAY_OF_STATUSES, IERROR)
INTEGER INCOUNT, ARRAY_OF_REQUESTS(*), OUTCOUNT, ARRAY_OF_INDICES(*),
ARRAY_OF_STATUSES(MPI_STATUS_SIZE,*), IERROR
static int MPI::Request::Testsome(int incount,
MPI::Request array_of_requests[], int array_of_indices[],
MPI::Status array_of_statuses[])
static int MPI::Request::Testsome(int incount,
MPI::Request array_of_requests[], int array_of_indices[])
Функция MPI_TESTSOME ведет себя подобно MPI_WAITSOME за исключением того, что заканчивается немедленно. Если ни одной операции не завершено, она возвращает outcount = 0. Если не имеется активных дескрипторов в списке, она возвращает outcount = MPI_UNDEFINED.
MPI_TESTSOME является локальной операцией, которая заканчивается немедленно, тогда как MPI_WAITSOME будет блокировать процесс до завершения обменов, если в списке содержится хотя бы один активный дескриптор. Оба вызова выполняют требование однозначности: если запрос на прием повторно появляется в списке запросов, передаваемых MPI_WAITSOME или MPI_TESTSOME, и соответствующая посылка была инициирована, тогда прием будет рано или поздно завершен успешно, если передача не закрыта другим приемом; аналогичная ситуация для запросов посылок.
Ошибки при выполнении MPI_TESTSOME обрабатываются также, как и для MPI_WAITSOME.
Совет пользователям: Использование MPI_TESTSOME представляется более эффективным, чем использование MPI_TESTANY. Первая функция возвращает информацию по всем завершенным обменам, для последней требуется вызов для каждого обмена, который завершается.
Сервер с множественными клиентами может использовать MPI_WAITSOME, чтобы не лишать обмена ни одного клиента. Клиент посылает сообщение серверу с сервисным запросом. Сервер вызывает MPI_WAITSOME с одним приемным требованием для каждого клиента и затем обрабатывает все приемы, которые завершены. Если вместо MPI_WAITSOME использован вызов MPI_WAITANY, тогда один клиент мог бы остаться без возможности обмена, в то время, как другие клиенты всегда проходили бы первыми.[]
Совет разработчикам: MPI_TESTSOME должен завершать как можно большее число ждущих коммуникаций.[]
Пример 3.15 Код клиента - сервера (имеет место невозможность обмена).
CALL MPI_COMM_SIZE(comm, size, ierr)
CALL MPI_COMM_RANK(comm, rank, ierr)
IF(rank > 0) THEN ! код клиента
DO WHILE(.TRUE.)
CALL MPI_ISEND(a, n, MPI_REAL, 0, tag, comm, request, ierr)
CALL MPI_WAIT(request, status, ierr)
END DO
ELSE ! rank=0 - код сервера
DO i=1, size-1
CALL MPI_IRECV(a(1,i), n, MPI_REAL, i tag,
comm, request_list(i), ierr)
END DO
DO WHILE(.TRUE.)
CALL MPI_WAITANY(size-1, request_list, index, status, ierr)
CALL DO_SERVICE(a(1,index)) ! дескриптор одного сообщения
CALL MPI_IRECV(a(1, index), n, MPI_REAL, index, tag,
comm, request_list(index), ierr)
END DO
END IF
Пример 3.16 Код с использованием MPI_WAITSOME.
CALL MPI_COMM_SIZE(comm, size, ierr)
CALL MPI_COMM_RANK(comm, rank, ierr)
IF(rank > 0) THEN ! код клиента
DO WHILE(.TRUE.)
CALL MPI_ISEND(a, n, MPI_REAL, 0, tag, comm, request, ierr)
CALL MPI_WAIT(request, status, ierr)
END DO
ELSE ! rank=0 - код сервера
DO i=1, size-1
CALL MPI_IRECV(a(1,i), n, MPI_REAL, i, tag,
comm, requests(i), ierr)
END DO
DO WHILE(.TRUE.)
CALL MPI_WAITSOME(size, request_list, numdone,
indices, statuses, ierr)
DO i=1, numdone
CALL DO_SERVICE(a(1, indices(i)))
CALL MPI_IRECV(a(1, indices(i)), n, MPI_REAL, 0, tag,
comm, requests(indices(i)), ierr)
END DO
END DO
END IF
Операции MPI_PROBE и MPI_IPROBE позволяют проверить входные сообщения без их реального приема. Пользователь затем может решить, как ему принимать эти сообщения, основываясь на информации, возвращенной при пробе (преимущественно, на информации, возвращенной аргументом status). В частности, пользователь может выделить память для приемного буфера по величине опробованного сообщения.
Операция MPI_CANCEL позволяет отменить ждущие сообщения. Инициация операций получения или отправки связывает пользовательские ресурсы (буфера процесса-получателя или отправителя) и отмена может оказаться необходимой, чтобы освободить эти ресурсы.
Синтаксис функции MPI_IPROBE представлен ниже.
MPI_IPROBE(source, tag, comm, flag, status)
| IN | source | номер процесса-отправителя или MPI_ANY_SOURCE (целое) | |
| IN | tag | значение тэга или MPI_ANY_TAG (целое) | |
| IN | comm | коммуникатор (дескриптор) | |
| OUT | flag | (логическое значение) | |
| OUT | status | статус (статус) |
int MPI_Iprobe(int source, int tag, MPI_Comm comm, int *flag, MPI_Status *status) MPI_IPROBE(SOURCE, TAG, COMM, FLAG, STATUS, IERROR) LOGICAL FLAG INTEGER SOURCE, TAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR bool MPI::Comm::Iprobe(int source, int tag, MPI::Status& status) const bool MPI::Comm::Iprobe(int source, int tag) const
Функция MPI_IPROBE (source, tag, comm, flag, status) возвращает flag = true, если имеется сообщение, которое может быть получено и которое соответствует образцу, описанному аргументами source, tag, и comm. Вызов соответствует тому же сообщению, которое было бы получено с помощью вызова MPI_RECV (..., source, tag, comm, status), выполненного на той же точке программы, и возвращает статус с теми же значениями, которые были бы возвращены MPI_RECV(). Другими словами, вызов возвращает flag = false, и оставляет статус неопределенным.
Если MPI_IPROBE возвращает flag = true, тогда содержание статусного объекта может быть впоследствии получено так, как описано в разделе 3.2.5, с целью определить источник, тэг и длину опробованного сообщения. Последующий прием, выполненный с тем же самым контекстом и тэгом, возвращенным в status вызовом MPI_IPROBE, будет получать сообщение, которое соответствует пробе, если после пробы не вмешается какое-либо другое сообщение. Если принимающий процесс является многопоточным, то ответственность за выполнение последнего условия возлагается на пользователя.
Аргумент source функции MPI_PROBE может быть MPI_ANY_SOURCE, это позволяет опробовать сообщения из произвольного источника и/или с произвольным тэгом. Однако, специфический контекст обмена обязан создаваться только при помощи аргумента comm.
Сообщение не обязательно должно быть получено сразу после опробования, кроме того оно может опробоваться несколько раз перед его получением.
Синтаксис функции MPI_PROBE представлен ниже.
MPI_PROBE (source, tag, comm, status)
| IN | source | номер источника или MPI_ANY_SOURCE (целое) | |
| IN | tag | значение тэга или MPI_ANY_TAG (целое) | |
| IN | comm | коммуникатор (дескриптор) | |
| OUT | status | статус (статус) |
int MPI_Probe(int source, int tag, MPI_Comm comm, MPI_Status *status) MPI_PROBE(SOURCE, TAG, COMM, STATUS, IERROR) INTEGER SOURCE, TAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR void MPI::Comm::Probe(int source, int tag, MPI::Status& status) const void MPI::Comm::Probe(int source, int tag) const
MPI_PROBE ведет себя подобно MPI_IPROBE, исключая тот факт, что функция MPI_PROBE является блокирующей и заканчивается только после того, как соответствующее сообщение было найдено.
MPI реализация MPI_PROBE и MPI_IPROBE нуждается в гарантии продвижения: если обращение к MPI_PROBE уже было запущено процессом, и посылка, которая соответствует пробе, уже инициирована тем же процессом, тогда вызов MPI_PROBE будет завершен, если сообщение не будет получено другой конкурирующей операцией приема (которая выполняется другой ветвью опробуемого процесса). Аналогично, если процесс ожидает выполнения MPI_IPROBE и соответствующее сообщение было запущено, тогда обращение к MPI_IPROBE рано или поздно возвратит flag = true, если сообщение не получено другой конкурирующей приемной операцией.
Пример 3.17 Использование блокирующей пробы для ожидания входного сообщения.
CALL MPI_COMM_RANK(comm, rank, ierr)
IF (rank.EQ.0) THEN
CALL MPI_SEND(i, 1, MPI_INTEGER, 2, 0, comm, ierr)
ELSE IF(rank.EQ.1) THEN
CALL MPI_SEND(x, 1, MPI_REAL, 2, 0, comm, ierr)
ELSE ! rank.EQ.2
DO i=1, 2
CALL MPI_PROBE(MPI_ANY_SOURCE, 0,
comm, status, ierr)
IF (status(MPI_SOURCE) = 0) THEN
100 CALL MPI_RECV(i,1,MPI_INTEGER,0,0,comm, status, ierr)
ELSE
200 CALL MPI_RECV(x,1,MPI_REAL,1,0,comm, status, ierr)
END IF
END DO
END IF
Каждое сообщение принимается с правильным типом.
Пример 3.18 Программа подобна предыдущей, но теперь в ней имеется проблема.
CALL MPI_COMM_RANK(comm, rank, ierr)
IF (rank.EQ.0) THEN
CALL MPI_SEND(i, 1, MPI_INTEGER, 2, 0, comm, ierr)
ELSE IF(rank.EQ.1) THEN
CALL MPI_SEND(x, 1, MPI_REAL, 2, 0, comm, ierr)
ELSE
DO i=1, 2
CALL MPI_PROBE(MPI_ANY_SOURCE, 0,
comm, status, ierr)
IF (status(MPI_SOURCE) = 0) THEN
100 CALL MPI_RECV(i, 1, MPI_INTEGER, MPI_ANY_SOURCE,
0, comm, status, ierr)
ELSE
200 CALL MPI_RECV(x, 1, MPI_REAL, MPI_ANY_SOURCE,
0, comm, status, ierr)
END IF
END DO
END IF
Здесь пример 3.17 слегка модифицирован, используется MPI_ANY_SOURCE, как аргумент sourse в двух вызовах приема, обозначенных метками 100 и 200. Теперь программа некорректна: операция приема может получать сообщение, которое отличается от сообщения, опробованного предыдущим обращением к MPI_PROBE.
Совет разработчикам: Вызов MPI_PROBE (source, tag, comm, status) будет соответствовать сообщению, которое было бы получено функцией MPI_RECV (...source, tag, comm, status), выполненной в этой же точке программы. Предположим, что это сообщение имеет источник s, тэг t и коммуникатор c. Если тэг имел в вызове пробы значение MPI_ANY_TAG, тогда опробованное значение будет самым ранним ждущим сообщением от источника с коммуникатором с и любым тэгом; в любом случае опробованное сообщение будет самым ранним ждущим сообщением от источника s, с тэгом t и коммуникатором c. Операция приема, выполненная после пробы, которая использует тот же самый коммуникатор, как и проба, и использующая тэг и источник, возвращенные пробой, обязана принять это сообщение, если оно уже не было принято другой приемной операцией.[]
Синтаксис функции MPI_CANCEL представлен ниже.
MPI_CANCEL (request)
| IN | request | коммуникационный запрос (дескриптор) |
int MPI_Cancel(MPI_Request *request) MPI_CANCEL(REQUEST, IERROR) INTEGER REQUEST, IERROR void MPI::Request::Cancel () const
Обращение к MPI_CANCEL маркирует для отмены ждущие неблокирующие операции обмена (передачи или приема). Вызов cancel является локальным. Он заканчивается немедленно, возможно перед действительной отменой обмена. После маркировки необходимо завершить эту операцию обмена, используя вызов MPI_REQUEST_FREE, MPI_WAIT или MPI_TEST (или любые производные операции).
Если обмен маркирован для отмены, тогда вызов MPI_WAIT для этой операции гарантирует завершение, невзирая на активность других процессов (то есть MPI_WAIT ведет себя как локальная функция); аналогично, если MPI_TEST вызывается повторно в цикле занятого ожидания для отмены обмена, тогда MPI_TEST будет неизбежно успешно закончен.
MPI_CANCEL может быть использован для отмены обмена, который использует персистентный запрос (см. раздел 3.9), тем же способом, который используется для неперсистентных запросов. Успешная отмена отменяет активный обмен, но не сам запрос. После обращения к MPI_CANCEL и затем к MPI_WAIT или MPI_TEST запрос становится неактивным и может быть активирован для нового обмена.
Успешная отмена буферизованной передачи освобождает буферное пространство, занятое ждущим сообщением.
Должно выполняться следующее условие: либо отмена имеет успех, либо имеет успех обмен, но не обе ситуации вместе. Если передача маркирована для отмены, тогда обязательно должна быть ситуация, когда либо передача завершается нормально (посланное сообщение принято процессом назначения), или передача отменена успешно (никакая часть сообщения не принята по адресу назначения). Тогда любой соответствующий прием закрывается другой передачей. Если прием маркирован для отмены, тогда обязан быть случай, когда прием завершился нормально, или этот прием успешно отменен (никакая часть приемного буфера не изменена). Тогда любая соответствующая передача должна быть удовлетворена другим приемом.
Если операция была отменена, тогда информация об этом будет возвращена в в аргумент статуса операции, которая завершает обмен.
Синтаксис функции MPI_TEST_CANCELLED представлен ниже.
MPI_TEST_CANCELLED (status, flag)
| IN | status | статус (статус) | |
| OUT | flag | (логический тип) |
int MPI_Test_cancelled(MPI_Status *status, int *flag) MPI_TEST_CANCELLED(STATUS, FLAG, IERROR) LOGICAL FLAG INTEGER STATUS(MPI_STATUS_SIZE), IERROR bool MPI::Status::Is_cancelled () const
Функция MPI_TEST_CANCELLED возвращает flag = true, если обмен, связанный со статусным объектом, был отменен успешно. В этом случае все другие поля статуса (такие как count или tag) не определены. В противном случае возвращается flag = false. Если приемная операция может быть отменена, то сначала можно вызвать MPI_TEST_CANCELLED, чтобы проверить, была ли отменена операция (перед проверкой других полей возвращенного статуса).
Совет пользователям: Отмена может быть дорогостоящей операцией, которую следует использовать в виде исключения.[]
Совет разработчикам: Если операция передачи использует ``жадный'' (``eager'') протокол (данные передаются получателю еще до того, как инициирован соответствующий прием), тогда отмена этой передачи может потребовать обмена с предполагаемым получателем, чтобы освободить занятые буфера. На некоторых системах это может потребовать прерывания предполагаемого процесса-получателя. Заметим, что хотя для реализации MPI_CANCEL может потребоваться обмен, это все еще локальная операция, поскольку ее завершение не зависит от кода, выполняемого другими процессами. Если обработка необходима на другом процессе, это должно быть прозрачно для приложения (отсюда необходимость прерывания и наличия обработчика прерываний).[]
Часто запрос с одним и тем же набором аргументов повторно выполняется во внутреннем цикле параллельных вычислений. В такой ситуации можно оптимизировать обмен путем однократного включения списка аргументов в персистентный (persistent) коммуникационный запрос и повторного использования этого запроса для инициации и завершения обмена.
Персистентный запрос, созданный таким образом, может восприниматься как коммуникационный порт или ``полуканал''. Он не обеспечивает полноты функций обычного канала, поскольку нет никакой связи между передающим и приемным портами. Эта конструкция позволяет уменьшить накладные расходы на коммуникацию между процессом и коммуникационным контроллером, но не расходы на коммуникацию между одним коммуникационным контроллером и другим.
Если сообщение послано на основе персистентного запроса, то оно не обязательно должно быть принято операцией, также использующей персистентный запрос, и наоборот.
Персистентный запрос создается одним из четырех следующих вызовов.
Синтаксис функции MPI_SEND_INIT представлен ниже.
MPI_SEND_INIT (buf, count, datatype, dest, tag, comm, request)
| IN | buf | начальный адрес буфера посылки (альтернатива) | |
| IN | count | число посланных элементов (целое) | |
| IN | datatype | тип каждого элемента (дескриптор) | |
| IN | dest | номер процесса-получателя (целое) | |
| IN | tag | тэг сообщения (целое) | |
| IN | comm | коммуникатор(дескриптор) | |
| OUT | request | коммуникационный запрос (дескриптор) |
int MPI_Send_init(void* buf, int count, MPI_Datatype datatype,
int dest, int tag, MPI_Comm comm, MPI_Request *request)
MPI_SEND_INIT(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR)
<type> BUF(*)
INTEGER REQUEST, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR
MPI::Prequest MPI::Comm::Send_init(const void* buf, int count,
const MPI::Datatype& datatype, int dest, int tag) const
MPI_SEND_INIT создает персистентный коммуникационный запрос для операции передачи стандартного режима и связывает для этого все аргументы операции передачи.
Синтаксис функции MPI_BSEND_INIT представлен ниже.
MPI_BSEND_INIT (buf, count, datatype, dest, tag, comm, request)
| IN | buf | начальный адрес передающего буфера (альтернатива) | |
| IN | count | число посланных элементов (целое) | |
| IN | datatype | тип каждого элемента (дескриптор) | |
| IN | dest | номер приемника (целое) | |
| IN | tag | тэг сообщения (целое) | |
| IN | comm | коммуникатор (дескриптор) | |
| OUT | request | коммуникационный запрос (дескриптор) |
int MPI_Bsend_init(void* buf, int count, MPI_Datatype datatype,
int dest, int tag, MPI_Comm comm, MPI_Request *request)
MPI_BSEND_INIT(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR)
<type> BUF(*)
INTEGER REQUEST, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR
MPI::Prequest MPI::Comm::Bsend_init (const void* buf, int count,
const MPI::Datatype& datatype, int dest, int tag) const
MPI_BSEND_INIT создает персистентный коммуникационный запрос для буферизованного режима передачи.
Синтаксис функции MPI_SSEND_INIT представлен ниже.
MPI_SSEND_INIT (buf, count, datatype, dest, tag, comm, request)
| IN | buf | начальный адрес буфера отправителя (альтернатива) | |
| IN | count | число посланных элементов (целое) | |
| IN | datatype | тип каждого элемента (дескриптор) | |
| IN | dest | номер получателя (целое) | |
| IN | tag | тэг сообщения (целое) | |
| IN | comm | коммуникатор(дескриптор) | |
| OUT | request | коммуникационный запрос (дескриптор) |
int MPI_Ssend_init (void* buf, int count, MPI_Datatype datatype,
int dest, int tag, MPI_Comm comm, MPI_Request *request)
MPI_SSEND_INIT(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR)
<type> BUF(*)
INTEGER REQUEST, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR
MPI::Prequest MPI::Comm::Ssend_init(const void* buf, int count,
const MPI::Datatype& datatype, int dest, int tag) const
MPI_SSEND_INIT создает персистентный коммуникационный запрос для синхронного режима операции посылки.
Синтаксис функции MPI_RSEND_INIT представлен ниже.
MPI_RSEND_INIT (buf, count, datatype, dest, tag, comm, request)
| IN | buf | начальный адрес буфера отправителя (альтернатива) | |
| IN | count | число посланных элементов (целое) | |
| IN | datatype | тип каждого элемента (дескриптор) | |
| IN | dest | номер получателя (целое) | |
| IN | tag | тэг сообщения (целое) | |
| IN | comm | коммуникатор(дескриптор) | |
| OUT | request | коммуникационный запрос (дескриптор) |
int MPI_Rsend_init (void* buf, int count, MPI_Datatype datatype,
int dest, int tag, MPI_Comm comm, MPI_Request *request)
MPI_RSEND_INIT(BUF, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR)
<type> BUF(*)
INTEGER REQUEST, COUNT, DATATYPE, DEST, TAG, COMM, REQUEST, IERROR
MPI::Prequest MPI::Comm::Rsend_init(const void* buf, int count,
const MPI::Datatype& datatype, int dest, int tag) const
MPI_RSEND_INIT создает персистентный коммуникационный объект для режима по готовности операции посылки.
Синтаксис функции MPI_RECV_INIT представлен ниже.
MPI_RECV_INIT(buf, count, datatype, source, tag, comm, request)
| OUT | buf | начальный адрес приемного буфера (альтернатива) | |
| IN | count | число полученных элементов (целое) | |
| IN | datatype | тип каждого элемента (дескриптор) | |
| IN | source | номер источника или MPI_ANY_SOURCE (целое) | |
| IN | tag | тэг сообщения или MPI_ANY_TAG (целое) | |
| IN | comm | коммуникатор (дескриптор) | |
| OUT | request | коммуникационный запрос (дескриптор) |
int MPI_Recv_init(void* buf, int count, MPI_Datatype datatype,
int source, int tag, MPI_Comm comm, MPI_Request *request)
MPI_RECV_INIT(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR)
<type> BUF(*)
INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM, REQUEST, IERROR
MPI::Prequest MPI::Comm::Recv_init(void* buf, int count,
const MPI::Datatype& datatype, int source, int tag) const
Функция MPI_RECV_INIT создает персистентный запрос для операции приема. Аргумент buf маркируется как OUT, поскольку пользователь разрешает запись в приемный буфер, передавая аргумент MPI_RECV_INIT.
Персистентный запрос после создания не активен - никакого активного обмена не подключено к запросу.
Коммуникация (передача или прием), которая использует персистентный запрос, создается функцией MPI_START.
Синтаксис функции MPI_START представлен ниже.
MPI_START(request)
| INOUT | request | коммуникационный запрос (дескриптор) |
int MPI_Start (MPI_Request *request) MPI_START (REQUEST, IERROR) INTEGER REQUEST, IERROR void MPI::Prequest::Start ()
Аргумент request - дескриптор, возвращенный одним из пяти предыдущих вызовов. Связанный с ним запрос должен быть не активен. Запрос становится активен сразу, как только сделан вызов.
Если это запрос для посылки с режимом по готовности, тогда соответствующий прием должен быть установлен перед тем, как сделан вызов. Коммуникационный буфер не должен быть доступен после вызова и до завершения операции.
Вызов MPI_START является локальным с семантикой, подобной семантике неблокирующей коммуникационной операции, описанной в разделе 3.7. Это означает, что обращение к MPI_START с запросом, созданным MPI_SEND_INIT, запускает обмен тем же способом, как при обращении к MPI_ISEND; обращение к MPI_START с запросом, созданным MPI_BSEND_INIT, запускает обмен тем же способом, как при обращении к MPI_IBSEND; и так далее.
Синтаксис функции MPI_STARTALL представлен ниже.
MPI_STARTALL (count, array_of_requests)
| IN | count | длина списка (целое) | |
| INOUT | array_of_requests | массив запросов (массив of дескриптор) |
int MPI_Startall(int count, MPI_Request *array_of_requests) MPI_STARTALL(COUNT, ARRAY_OF_REQUESTS, IERROR) INTEGER COUNT, ARRAY_OF_REQUESTS(*), IERROR static void MPI::Prequest::Startall (int count, MPI::Prequest array_of_requests[])
Запуск всех обменов связан с запросами в array_of_requests.
Обращение к функции
MPI_STARTALL(count,
array_of_requests) дает тот же самый эффект, что и обращения к функциям
MPI_START(&array_of_requests[i]), выполненным для i=0,
..., count-1 в некотором произвольном порядке.
Обмен, который стартует по вызову MPI_START или MPI_STARTALL завершается обращением к MPI_WAIT, MPI_TEST или к одной из производных функций, описанных в разделе 3.7.5. Запрос становится неактивным после успешного завершения такого вызова. Запрос не снимается с назначения и может быть активирован вновь вызовами MPI_START или MPI_STARTALL.
Постоянный запрос удаляется вызовом MPI_REQUEST_FREE (раздел 3.7.3).
Обращение к MPI_REQUEST_FREE может выполняться в любой точке программы после старта персистентного запроса. Однако запрос будет снят с назначения только после того, как он становится неактивным. Активные приемные запросы не должны удаляться, иначе невозможно будет проверить, какой прием был завершен. Желательно удалить запросы, когда они не активны. Если следовать этому правилу, то функции, описанные в этом разделе, будут вызываться в последовательности вида
Create (Start Complete)*Free
где * указывает ноль или более повторений. Если некоторый коммуникационный объект используется в нескольких конкурирующих ветвях, то координация вызовов для соблюдения правильной последовательности выполнения, лежит на пользователе.
Операция передачи, инициированная MPI_START, может соответствовать любой операции приема; аналогичо, приемная операция , инициированная MPI_START, может принимать сообщения, сгенерированные любой операцией передачи.
Совет пользователям: Чтобы предупредить проблему с копированием аргументов и оптимизацией регистров, выполняемую компиляторами языка ФОРТРАН, следует обратить внимание на раздел 10.2.2 в стандарте MPI-2.[]
Операция send-receive комбинирует в одном обращении посылку сообщения одному получателю и прием сообщения от другого отправителя. Получателем и отправителем может быть тот же самый процесс. Эта операция весьма полезна для выполнения сдвига по цепи процессов. Если для такого сдвига были использованы блокирующие приемы и передачи, тогда нужно корректно упорядочить эти приемы и передачи (например, четные процессы передают, затем принимают, нечетные процессы сначала принимают, затем передают) так, чтобы предупредить циклические зависимости, которые могут привести к дедлоку. Когда используется операция send-receive, коммуникационная система решает эти проблемы. Операция send-receive может быть использована в сочетании с функциями, описанными в главе 6, для выполнения сдвигов на различных топологиях. К тому же операция send-receive полезна для реализации удаленных процедурных вызовов.
Сообщение, посланное операцией send-receive, может быть получено обычной операцией приема или опробовано операцией probe; send-receive может также получать сообщения, посланные обычной операцией передачи.
Синтаксис функции MPI_SENDRECV представлен ниже.
MPI_SENDRECV(sendbuf, sendcount, sendtype, dest, sendtag,
recvbuf, recvcount, recvtype, source, recvtag, comm, status)
| IN | sendbuf | начальный адрес буфера отправителя (альтернатива) | |
| IN | sendcount | число элементов в буфере отправителя (целое) | |
| IN | sendtype | тип элементов в буфере отправителя (дескриптор) | |
| IN | dest | номер процесса-получателя (целое) | |
| IN | sendtag | тэг процесса-отправителя (целое) | |
| OUT | recvbuf | начальный адрес приемного буфера (альтернатива) | |
| IN | recvcount | число элементов в в приемном буфере (целое) | |
| IN | recvtype | тип элементов в приемном буфере (дескриптор) | |
| IN | source | номер процесса-отправителя (целое) | |
| IN | recvtag | тэг процесса-получателя (целое) | |
| IN | comm | коммуникатор (дескриптор) | |
| OUT | status | статус (статус) |
int MPI_Sendrecv(void *sendbuf, int sendcount, MPI_Datatype sendtype,
int dest, int sendtag, void *recvbuf, int recvcount,
MPI_Datatype recvtype, int source, MPI_Datatype recvtag,
MPI_Comm comm, MPI_Status *status)
MPI_SENDRECV(SENDBUF, SENDCOUNT, SENDTYPE, DEST, SENDTAG, RECVBUF,
RECVCOUNT, RECVTYPE, SOURCE, RECVTAG, COMM, STATUS, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNT, SENDTYPE, DEST, SENDTAG, RECVCOUNT, RECVTYPE,
SOURCE, RECVTAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR
void MPI::Comm::Sendrecv(const void *sendbuf, int sendcount,
const MPI::Datatype& sendtype, int dest, int sendtag,
void *recvbuf, int recvcount, const MPI::Datatype& recvtype,
int source, int recvtag, MPI::Status& status) const
void MPI::Comm::Sendrecv(const void *sendbuf, int sendcount,
const MPI::Datatype& sendtype, int dest, int sendtag,
void *recvbuf, int recvcount, const MPI::Datatype& recvtype,
int source, int recvtag) const
Функция MPI_SENDRECV выполняет операции блокирующей передачи и приема. Передача и прием используют тот же самый коммуникатор, но возможно различные тэги. Буфера отправителя и получателя должны быть разделены и могут иметь различную длину и типы данных.
Синтаксис функции MPI_SENDRECV_REPLACE представлен ниже.
MPI_SENDRECV_REPLACE(buf, count, datatype, dest,
sendtag, source, recvtag, comm, status)
| INOUT | buf | начальный адрес буфера отправителя и получателя (альтернатива) | |
| IN | count | число элементов в буфере отправителя и получателя (целое) | |
| IN | datatype | тип элементов в буфере отправителя и получателя (дескриптор) | |
| IN | dest | номер процесса-получателя (целое) | |
| IN | sendtag | тэг процесса-отправителя (целое) | |
| IN | source | номер процесса-отправителя (целое) | |
| IN | recvtag | тэг процесса-получателя (целое) | |
| IN | comm | коммуникатор (дескриптор) | |
| OUT | status | статус (статус) |
int MPI_Sendrecv_replace(void* buf, int count, MPI_Datatype datatype,
int dest, int sendtag, int source, int recvtag, MPI_Comm comm,
MPI_Status *status)
MPI_SENDRECV_REPLACE(BUF, COUNT, DATATYPE, DEST, SENDTAG,
SOURCE, RECVTAG, COMM, STATUS, IERROR)
<type> BUF(*)
INTEGER COUNT, DATATYPE, DEST, SENDTAG, SOURCE, RECVTAG,
COMM, STATUS(MPI_STATUS_SIZE), IERROR
void MPI::Comm::Sendrecv_replace (void* buf, int count,
const MPI::Datatype& datatype, int dest, int sendtag,
int source, int recvtag, MPI::Status& status) const
void MPI::Comm::Sendrecv_replace(void* buf, int count,
const MPI::Datatype& datatype, int dest, int sendtag,
int source, int recvtag) const
Функция MPI_SENDRECV_REPLACE выполняет блокирующие передачи и приемы. Тот же самый буфер используется для отправки и получения, так что посланное сообщение замещается полученным. Семантика операции send-receive похожа на запуск двух конкурирующих потоков, когда один выполняет передачу, а другой - прием, с последующим объединением этих потоков.
Совет разработчикам: Для варианта "замещения" необходима дополнительная промежуточная буферизация.[]
Во многих случаях удобно описать ``фиктивного'' отправителя или получателя для коммуникаций. Это упрощает код, который необходим для работы с границами, например, в случае нециклического сдвига, выполненного по вызову send-receive.
Когда в вызове нужны аргументы отправителя или получателя, вместо номера может быть использовано специальное значение MPI_PROC_NULL. Обмен с процессом, который имеет значение MPI_PROC_NULL, не дает результата. Передача в процесс MPI_PROC_NULL успешна и заканчивается сразу, как только возможно. Прием от процесса MPI_PROC_NULL успешен и заканчивается сразу, как только возможно без измененения буфера приема. Когда выполняется прием из source = MPI_PROC_NULL, тогда статус возвращает source = MPI_PROC_NULL, tag = MPI_ANY_TAG и count = 0.
До сих пор все парные обмены использовали только непрерывные буферы, содержащие последовательности элементов одного типа. Это слишком большое ограничение по двум причинам. Часто необходимо передавать сообщения, которые содержат значения различных типов (например, целое число с последующим набором вещественных чисел); или нужно посылать несмежные данные (например, подблоки матрицы). Одно из решений состоит в том, чтобы упаковать несмежные данные в смежный буфер на стороне отправителя и распаковать обратно на приемной стороне. Недостаток состоит в том, что требуется дополнительная операция копирования память-память на обеих сторонах, даже когда коммуникационная подсистема имеет возможностиscatter-gather (разборки-сборки). Вместо этого MPI обеспечивает механизм для описания более общих буферов для несмежных коммуникаций, в которых используются производные типы данных, образуемые конструкторами, описанными в этом разделе. Этот метод конструирования производных типов данных может использоваться рекурсивно.
Универсальный тип данных (general datatype) есть скрытый объект, который описывается двумя составляющими:
При этом не требуется, чтобы смещения были положительными, различными или возрастающего порядка. Поэтому порядок объектов не обязан совпадать с их порядком в памяти, и объект может появляться более, чем один раз. Последовательность указанных выше пар называется картой типа (a type map). Последовательность базисных типов данных (смещения игнорируются) есть сигнатура типа.
Пусть
Typemap = { (type![]() ,disp
,disp![]() ),
..., (type
),
..., (type![]() , disp
, disp![]() )} ,
)} ,
является такой картой типа, где type![]() есть
базисные типы и disp
есть
базисные типы и disp![]() есть смещения. Пусть
есть смещения. Пусть
Typesig = { type![]() , ... , type
, ... , type![]() }
}
является связанной с типом сигнатурой. Карта типа вместе с адресом buf описывает коммуникационный буфер, который состоит из nэлементов, где i -ый элемент расположен по адресу buf
+ disp![]() и имеет тип type
и имеет тип type![]() . Сообщение,
полученное из такого коммуникационного буфера, будет состоять из n значений с типами, определенными Typesig.
. Сообщение,
полученное из такого коммуникационного буфера, будет состоять из n значений с типами, определенными Typesig.
Можно использовать дескриптор общего типа данных как аргумент в операциях передачи или приема вместо аргумента базисного типа данных. Операция MPI_SEND (buf, 1, datatype,...) будет использовать буфер посылки, определенный адресом buf и общим типом данных, связанным с datatype; она будет генерировать сообщение с сигнатурой типа, определенной аргументом datatype. MPI_RECV(buf, 1, datatype,...) будет использовать приемный буфер, определенный базовым адресом buf и универсальный тип данных, связанный с datatype.
Универсальные типы данных могут использоваться во всех операциях приема и передачи. В разделе 3.12.5 будет обсужден случай, когда второй аргумент count имеет значение > 1.
Базисный тип данных, представленный в разделе 3.2.2 есть частный случай универсального типа и является предопределенным. Поэтому MPI_INT есть предопределенный указатель на тип данных с картой {(int, 0)} с одним элементом типа int и смещением нуль. Другие базисные типы подобны.
Экстент (extent) типа данных определяется как пространство, от первого байта до последнего байта, занятое элементами в этом типе данных, округленное вверх с учетом требований выравнивания данных. Это означает, что если
Typemap = { (type![]() ,disp
,disp![]() ),
..., (type
),
..., (type![]() , disp
, disp![]() ) } ,
) } ,
то
lb(Typemap) = min (j) disp![]()
extent(typemap) = ub(Typemap) - lb(Type map).
Если type![]() требует выравнивания по байтовому
адресу, то есть имеется множество k
требует выравнивания по байтовому
адресу, то есть имеется множество k![]() , тогда
, тогда ![]() соответствует самому меньшему неотрицательному инкременту, необходимому,
чтобы округлить extent(Typemap) до следующего множества из max
соответствует самому меньшему неотрицательному инкременту, необходимому,
чтобы округлить extent(Typemap) до следующего множества из max![]() k
k![]() . Полное определение extent дается в
разделе 3.12.3.
. Полное определение extent дается в
разделе 3.12.3.
Пример 3.19 Допустим, что Type = { (double, 0), (char, 8) } (double на смещении нуль с последующим char на смещении восемь). Предположим далее, что удвоенные значения должны быть выравнены по адресам, кратным восьми. Тогда экстент этого типа данных равен 16 (9 округлено к следующему значению, кратному 8). Тип данных, который состоит из знака, за которым сразу следует удвоенное значение, будет также иметь длину 16.
Объяснение: Определение экстента учитывает допущение, что сумма добавок на конце каждой структуры в массиве структур по крайней мере необходима для выполнения условий выравнивания. Более очевидное управление экстентом представлено в разделе 3.12.3. Такое явное управление необходимо в случаях, где допущение не выполняется, например, где используются объединенные типы (union types).[]
Contiguous. Простейшим типом конструктора типа данных является конструктор MPI_TYPE_CONTIGUOUS, который позволяет копировать тип данных в смежные области.
Синтаксис функции MPI_TYPE_CONTIGUOUS представлен ниже.
MPI_TYPE_CONTIGUOUS (count, oldtype, newtype)
| IN | count | число повторений (неотрицательное целое) | |
| IN | oldtype | старый тип данных (дескриптор) | |
| OUT | newtype | новый тип данных (дескриптор) |
int MPI_Type_contiguous(int count, MPI_Datatype oldtype,
MPI_Datatype *newtype)
MPI_TYPE_CONTIGUOUS(COUNT, OLDTYPE, NEWTYPE, IERROR)
INTEGER COUNT, OLDTYPE, NEWTYPE, IERROR
MPI::Datatype MPI::Datatype::Create_contiguous (int count) const
Новый тип newtype есть тип, полученный конкатенацией (сцеплением) count копий старого типа oldtype.
Пример 3.20 Пусть oldtype имеет карту type map { ( double, 0), (char, 8) } с длиной 16 и пусть count = 3. Карта нового типа будет:
{ (double, 0), (char, 8), (double, 16), (char, 24), (double, 32), (char, 40) } ;
то есть содержать меняющиеся удвоенные значения и символьные элементы со смещением 0, 8, 16, 24, 32, 40.
В общем предположим, что карта типа для oldtype есть
{ (type![]() ,disp
,disp![]() ), ...,
(type
), ...,
(type![]() , disp
, disp![]() )} ,
)} ,
с длиной ex, Тогда newtype имеет карту с count ![]() n элементами, определяемыми:
n элементами, определяемыми:
{ (type![]() , disp
, disp![]() ), ...,
(type
), ...,
(type![]() , disp
, disp![]() ), (type
), (type![]() , disp
, disp![]() +ex), ... ,(type
+ex), ... ,(type![]() ,
disp
,
disp![]() + ex) , ...
+ ex) , ...
(type![]() , disp
, disp![]() +ex
+ex ![]() (
count-1)), ... , (type
(
count-1)), ... , (type![]() , disp
, disp![]() + ex
+ ex ![]() (count-1)) }.
(count-1)) }.
Vector. Функция MPI_TYPE_VECTOR является более универсальным конструктором, который позволяет реплицировать типы данных в области, состоящие из блоков равного объема. Каждый блок получается конкатенацией некоторого количества копий старого типа. Пространство между блоками кратно размеру old datatype.
Синтаксис функции MPI_TYPE_VECTOR представлен ниже.
MPI_TYPE_VECTOR(count, blocklength, stride, oldtype, newtype)
| IN | count | число блоков (неотрицательное целое) | |
| IN | blocklength | число элементов в каждом блоке (неотрицательное целое) | |
| IN | stride | число элементов между началами каждого блока (целое) | |
| IN | oldtype | старый тип данных (дескриптор) | |
| OUT | newtype | новый тип данных (дескриптор) |
int MPI_Type_vector(int count, int blocklength, int stride,
MPI_Datatype oldtype, MPI_Datatype *newtype)
MPI_TYPE_VECTOR(COUNT, BLOCKLENGTH, STRIDE, OLDTYPE, NEWTYPE, IERROR)
INTEGER COUNT, BLOCKLENGTH, STRIDE, OLDTYPE, NEWTYPE, IERROR
MPI::Datatype MPI::Datatype::Create_vector(int count,
int blocklength, int stride) const
Пример 3.21 Предположим снова, что oldtype имеет карту type map {(double, 0), (char, 8)}, с размером 16. Обращение MPI_TYPE_VECTOR(2, 3, 4, oldtype, newtype) будет создавать тип с картой:
type map, { (double, 0), (char, 8), (double, 16), (char, 24), ( double, 32), (char, 40),
(double, 64), (char, 72), (double, 80), (char, 88), (double, 96), (char, 104) } .
Это означает, что в новой карте есть два блока, каждый с тремя копиями
старого типа, со страйдом (stride) 4 элемента (4![]() 16
байтов) между блоками.
16
байтов) между блоками.
Пример 3.22 Обращение MPI_TYPE_VECTOR(3, 1, -2, oldtype, newtype) будет создавать тип:
{ (double, 0), (char, 8), (double, -32), (char, -24), (double, -64), (char, -56) } .
В общем случае предположим, что oldtype имеет карту:
{ (type![]() , disp
, disp![]() ), ...,
(type
), ...,
(type![]() , disp
, disp![]() ) },
) },
с экстентом ex. Пусть bl - длина блока. Вновь созданный
тип данных будет иметь карту с
![]() элементами:
элементами:
{ (type![]() , disp
, disp![]() ), ... ,
(type
), ... ,
(type![]() , disp
, disp![]() ),
),
(type![]() ,disp
,disp![]() + ex) , ... ,
(type
+ ex) , ... ,
(type![]() , disp
, disp![]() + ex), ...,
+ ex), ...,
(type![]() , disp
, disp![]() + (bl
-1)
+ (bl
-1) ![]() ex) , ... , (type
ex) , ... , (type![]() , disp
, disp![]() + (bl -1)
+ (bl -1) ![]() ex) ,
ex) ,
(type![]() ,disp
,disp![]() + stride
+ stride![]() ex) , ... , (type
ex) , ... , (type![]() , disp
, disp![]() + stride
+ stride![]() ex), ... ,
ex), ... ,
(type![]() , disp
, disp![]() + (stride +
bl -1)
+ (stride +
bl -1) ![]() ex) , ... , (type_n-1,
disp_n-1+ (stride + bl -1)
ex) , ... , (type_n-1,
disp_n-1+ (stride + bl -1) ![]() ex) , ....,
ex) , ....,
(type![]() ,disp
,disp![]() + stride
+ stride
![]() (count-1)
(count-1) ![]() ex), ... ,
ex), ... ,
(type![]() , disp
, disp![]() + stride
+ stride ![]() (count -1)
(count -1) ![]() ex) , ... ,
ex) , ... ,
(type![]() , disp
, disp![]() + (stride
+ (stride
![]() (count -1) + bl -1)
(count -1) + bl -1)![]() ex) , ... ,
ex) , ... ,
(type![]() , disp
, disp![]() + (
stride
+ (
stride ![]() (count -1) + bl -1)
(count -1) + bl -1) ![]() ex) } .
ex) } .
Обращение к MPI_TYPE_CONTIGUOUS (count, oldtype, newtype)
эквивалентно обращению
MPI_TYPE_VECTOR(count, 1, 1,
oldtype, newtype) или обращению MPI_TYPE_VECTOR (1, count, n,
oldtype, newtype), где n - произвольное.
Hvector. Функция MPI_TYPE_HVECTOR идентична MPI_TYPE_VECTOR за исключением того, что страйд задается в байтах, а не в элементах. Использование обоих типов векторных конструкторов иллюстрируется в разделе 3.12.7. (H обозначает heterogeneous - неоднородный).
Синтаксис функции MPI_TYPE_HVECTOR представлен ниже.
MPI_TYPE_HVECTOR(count, blocklength, stride, oldtype, newtype)
| IN | count | число блоков (неотрицательное целое) | |
| IN | blocklength | число элементов в каждом блоке (неотрицательное целое) | |
| IN | stride | число байтов между стартом каждого блока (целое) | |
| IN | oldtype | старый тип данных (дескриптор) | |
| OUT | newtype | новый тип данных (дескриптор) |
int MPI_Type_hvector(int count, int blocklength, MPI_Aint stride,
MPI_Datatype oldtype, MPI_Datatype *newtype)
MPI_TYPE_HVECTOR(COUNT, BLOCKLENGTH, STRIDE, OLDTYPE, NEWTYPE, IERROR)
INTEGER COUNT, BLOCKLENGTH, STRIDE, OLDTYPE, NEWTYPE, IERROR
MPI::Datatype MPI::Datatype::Create_hvector(int count,
int blocklength, MPI::Aint stride) const
Предположим, что oldtype имеет карту
{ (type![]() , disp
, disp![]() ), ...,
(type
), ...,
(type![]() , disp
, disp![]() ) } ,
) } ,
с расширением ex. Пусть bl - длина блока. Вновь созданный
тип данных будет иметь карту с
![]() элементами:
элементами:
{ (type![]() , disp
, disp![]() ), ... ,
(type
), ... ,
(type![]() , disp
, disp![]() ),
),
(type![]() ,disp
,disp![]() + ex) , ... ,
(type
+ ex) , ... ,
(type![]() , disp
, disp![]() + ex), ...,
+ ex), ...,
(type![]() , disp
, disp![]() + (bl -1)
+ (bl -1)
![]() ex) , ... , (type
ex) , ... , (type![]() , disp
, disp![]() + (bl -1)
+ (bl -1)![]() ex) ,
ex) ,
(type![]() ,disp
,disp![]() + stride) , ... , (type
+ stride) , ... , (type![]() , disp
, disp![]() +
stride) , ... ,
+
stride) , ... ,
(type![]() , disp
, disp![]() + stride + (
bl -1)
+ stride + (
bl -1)![]() ex) , ... ,
ex) , ... ,
(type![]() , disp
, disp![]() + stride + (bl -1)
+ stride + (bl -1)![]() ex) , ....,
ex) , ....,
(type![]() ,disp
,disp![]() + stride
+ stride
![]() (count-1)) , ... , (type
(count-1)) , ... , (type![]() ,
disp
,
disp![]() + stride
+ stride ![]() (count
-1)) , ... ,
(count
-1)) , ... ,
(type![]() , disp
, disp![]() + stride
+ stride
![]() (count -1) + (bl -1)
(count -1) + (bl -1)![]() ex) , ... ,
ex) , ... ,
(type![]() , disp
, disp![]() + stride
+ stride ![]() (count -1) + (bl -1)
(count -1) + (bl -1) ![]() ex) } .
ex) } .
Indexed. Функция MPI_TYPE_INDEXED позволяет реплицировать старый тип old datatype в последовательность блоков (каждый блок есть конкатенация old datatype), где каждый блок может содержать различное число копий и иметь различное смещение. Все смещения блоков кратны длине старого блока old type.
Синтаксис функции MPI_TYPE_INDEXED представлен ниже.
MPI_TYPE_INDEXED(count, array_of_blocklengths,
array_of_displacements, oldtype, newtype)
| IN | count | число блоков | |
| IN | array_of_blocklengths | число элементов в каждом блоке (массив неотрицательных целых) | |
| IN | array_of_displacements | смещение для каждого блока (массив целых) | |
| IN | oldtype | старый тип данных (дескриптор) | |
| OUT | newtype | новый тип данных (дескриптор) |
int MPI_Type_indexed(int count, int *array_of_blocklengths,
int *array_of_displacements, MPI_Datatype oldtype, MPI_Datatype *newtype)
MPI_TYPE_INDEXED(COUNT, ARRAY_OF_BLOCKLENGTHS,
ARRAY_OF_DISPLACEMENTS, OLDTYPE, NEWTYPE, IERROR)
INTEGER COUNT, ARRAY_OF_BLOCKLENGTHS(*), ARRAY_OF_DISPLACEMENTS(*),
OLDTYPE, NEWTYPE, IERROR
MPI::Datatype MPI::Datatype::Create_indexed(int count,
const int array_of_blocklengths[],
const int array_of_displacements[]) const
Пример 3.23 Пусть oldtype имеет карту type map { ( double, 0), (char, 8) } с экстентом16. Пусть B = (3, 1) и D = (4, 0). Обращение MPI_TYPE_INDEXED (2, B, D, oldtype, newtype) возвращает тип данных с картой:
{ (double, 64), (char, 72), (double, 80), (char, 88), (double, 96), (char, 104),
(double, 0), (char, 8) } .
Это означает, что в новом типе имеется три копии старого типа old type, начиная со смещения 64 и одна копия стартует со смещения 0.
В общем случае предположим, что oldtype имеет карту
{ (type![]() , disp
, disp![]() ), ...,
(type
), ...,
(type![]() , disp
, disp![]() ) } ,
) } ,
с экстентом ex. Пусть В является аргументом массива длин и
D - аргументом массива смещений. Тогда вновь созданный тип данных
имеет
![]() элементов:
элементов:
{(type![]() , disp
, disp![]() + D[0]
+ D[0] ![]() ex),..., (type
ex),..., (type![]() ,
disp
,
disp![]() + D[0]
+ D[0]![]() ex)
ex)
(type![]() , disp
, disp![]() + D[0] +B[0]
-1)
+ D[0] +B[0]
-1)![]() ex),..., (type
ex),..., (type![]() , disp
, disp![]() + (D[0] + В[0] -1)
+ (D[0] + В[0] -1)![]() ex),...,
ex),...,
(type![]() , disp
, disp![]() + D[count -
1]
+ D[count -
1]![]() ex),..., (type
ex),..., (type![]() ,
disp
,
disp![]() + D[count - 1]
+ D[count - 1]![]() ex)...
,
ex)...
,
(type![]() , disp
, disp![]() + (D[count
- 1] + B[count -1)
+ (D[count
- 1] + B[count -1)![]() ex),...,
ex),...,
(type![]() , disp
, disp![]() +
+![]() D[count - 1] + B[count -1)
D[count - 1] + B[count -1)![]() ex).
ex).
Обращение к MPI_TYPE_VECTOR (count, blocklength, stride, oldtype, newtype) будет эквивалентно обращению к MPI_TYPE_INDEXED(count, B, D, oldtype, newtype), где
D[j] = j![]() strade, j = 0,..., count - 1,
strade, j = 0,..., count - 1,
и
B[j] = blocklength, j = 0,..., count - 1
Hindexed. Функция MPI_TYPE_HINDEXED идентична MPI_TYPE_INDEXED, за исключением того, что смещения блоков в массиве array_of_displacements задаются в байтах, а не в кратностях величины старого типа oldtype.
Синтаксис функции MPI_TYPE_HINDEXED представлен ниже.
MPI_TYPE_HVECTOR(count, blocklength, stride, oldtype, newtype)
| IN | count | число блоков (неотрицательное целое) | |
| IN | blocklength | число элементов в каждом блоке (неотрицательное целое) | |
| IN | stride | число байтов между стартом каждого блока (целое) | |
| IN | oldtype | старый тип данных (дескриптор) | |
| OUT | newtype | новый тип данных (дескриптор) |
int MPI_Type_hvector(int count, int blocklength, MPI_Aint stride,
MPI_Datatype oldtype, MPI_Datatype *newtype)
MPI_TYPE_HVECTOR(COUNT, BLOCKLENGTH, STRIDE, OLDTYPE, NEWTYPE, IERROR)
INTEGER COUNT, BLOCKLENGTH, STRIDE, OLDTYPE, NEWTYPE, IERROR
MPI::Datatype MPI::Datatype::Create_hvector(int count,
int blocklength, MPI::Aint stride) const
Предположим, что oldtype имеет карту
{ (type0, disp0), ..., (typen-1, dispn-1) }
с расширением ex. Пусть В - это аргумент
array_of_blocklength, а D - аргумент
array_of_displacements. Вновь созданный тип данных имеет
карту с
![]() элементов:
элементов:
{(type![]() ,disp
,disp![]() + D[0]),..., (type
+ D[0]),..., (type![]() , disp
, disp![]() + D[0]),...,
+ D[0]),...,
(type![]() , disp
, disp![]() + D[0] +
(B[0] -1)
+ D[0] +
(B[0] -1)![]() ex),...,
ex),...,
(type![]() disp
disp![]() + D[0] + (B[0] -1)
+ D[0] + (B[0] -1)![]() ex),...,
ex),...,
(type![]() , disp
, disp![]() + D[count -
1]),..., (type
+ D[count -
1]),..., (type![]() disp
disp![]() + D[count - 1]), ...,
+ D[count - 1]), ...,
(type![]() , disp
, disp![]() + D[count -
1]) + (B[count - 1] - 1)
+ D[count -
1]) + (B[count - 1] - 1)![]() ex),...,
ex),...,
(type![]() disp
disp![]() + D[count - 1]) + (B[count - 1] - 1)
+ D[count - 1]) + (B[count - 1] - 1)![]() ex)}
ex)}
Struct. MPI_TYPE_STRUCT является наиболее общим типом конструктора. Он отличается от предыдущего тем, что позволяет каждому блоку состоять из репликаций различного типа.
Синтаксис функции MPI_TYPE_STRUCT представлен ниже.
=1cm
MPI_TYPE_STRUCT(count, array_of_blocklengths,
array_of_displacements, array_of_types, newtype)
| IN | count | число блоков (целое) | |
| IN | array_of_blocklength | число элементов в каждом блоке (массив целых) | |
| IN | array_of_displacements | смещение каждого блока в байтах (массив целых) | |
| IN | array_of_types | тип элементов в каждом блоке (массив дескрипторов объектов типов данных) | |
| OUT | newtype | новый тип данных (дескриптор) |
=1cm
int MPI_Type_struct(int count, int *array_of_blocklengths,
MPI_Aint *array_of_displacements, MPI_Datatype *array_of_types,
MPI_Datatype *newtype)
=1cm
MPI_TYPE_STRUCT(COUNT, ARRAY_OF_BLOCKLENGTHS, ARRAY_OF_DISPLACEMENTS,
ARRAY_OF_TYPES, NEWTYPE, IERROR)
INTEGER COUNT, ARRAY_OF_BLOCKLENGTHS(*), ARRAY_OF_DISPLACEMENTS(*),
ARRAY_OF_TYPES(*), NEWTYPE, IERROR
Пример 3.24 Пусть type1 имеет карту типа
{ (double, 0), (char, 8) } ,
с шириной 16. Пусть B = (2, 1, 3), D = (0, 16, 26), и T = (MPI_FLOAT, type1, MPI_CHAR). Тогда обращение MPI_TYPE_STRUCT(3, B, D, T, newtype) возвращает тип с картой:
{ (float, 0), (float, 4), (double, 16), (char, 24), (char, 26), (char, 27), (char, 28) },
то есть две копии MPI_FLOAT, начиная с 0, с последующей одной копией type1, начиная с 16, с последующими тремя копиями MPI_CHAR, начиная с 26. (Предполагается, что число с плавающей точкой занимает четыре байта).
Обращение к MPI_TYPE_HINDEXED(count, B, D, oldtype, newtype) эквивалентно обращению к MPI_TYPE_STRUCT(count, B, D, T, newtype), где каждый вход T равен oldtype.
Смещения в универсальном типе данных задаются относительно начального буферного адреса. Этот начальный ``нулевой адрес'' отмечается константой MPI_BOTTOM. Поэтому тип данных может описывать абсолютный адрес элементов в коммуникационном буфере, в этом случае аргумент buf получает значение MPI_BOTTOM.
Адрес ячейки памяти может быть найден путем использования функции MPI_ADDRES.
Синтаксис функции MPI_ADDRESS представлен ниже.
MPI_TYPE_HINDEXED(count, array_of_blocklengths,
array_of_displacements, oldtype, newtype)
| IN | count | число блоков (неотрицательное целое) | |
| IN | array_of_blocklengths | число элементов в каждом блоке (массив неотри-цательных целых) | |
| IN | array_of_displacements | смещение каждого блока в байтах (массив целых) | |
| IN | oldtype | старый тип данных (дескриптор) | |
| OUT | newtype | новый тип данных (дескриптор) |
int MPI_Type_hindexed(int count, int *array_of_blocklengths,
MPI_Aint *array_of_displacements, MPI_Datatype oldtype,
MPI_Datatype *newtype)
MPI_TYPE_HINDEXED(COUNT, ARRAY_OF_BLOCKLENGTHS, ARRAY_OF_DISPLACEMENTS,
OLDTYPE, NEWTYPE, IERROR)
INTEGER COUNT, ARRAY_OF_BLOCKLENGTHS(*), ARRAY_OF_DISPLACEMENTS(*),
OLDTYPE, NEWTYPE, IERROR
Функция MPI_ADDRESS возвращает байтовый адрес ячейки.
Пример 3.25 Использование MPI_ADDRESS для массива.
REAL A(100,100) INTEGER I1, I2, DIFF CALL MPI_ADDRESS(A(1,1), I1, IERROR) CALL MPI_ADDRESS(A(10,10), I2, IERROR) DIFF = I2 - I1 ! Значение DIFF есть 909*sizeofreal; значение I1 и I2 зависят от ! реализации.
Совет пользователям: Пользователи языка Си иногда стараются избежать использования MPI_ADDRESS, надеясь на доступность адресного оператора &. Заметим, однако, что & - выражение - это указатель (pointer), а не адрес. ANSI Си не требует, чтобы значение указателя было абсолютным адресом объекта, хотя это общий случай. Более того, ссылка может не иметь уникального определения на машине с сегментным адресным пространством. Использование MPI_ADDRESS в языке Си гарантирует также мобильность для таких машин.[]
Совет пользователям: Чтобы предупредить проблему с копированием аргументов и оптимизацией регистров, выполняемую компиляторами языка ФОРТРАН, следует обратить внимание на раздел 10.2.2 в стандарте MPI-2.[]
Следующая вспомогательная функция обеспечивает полезную информацию о производных типах данных.
Синтаксис функции MPI_TYPE_EXTENT представлен ниже.
MPI_TYPE_EXTENT(datatype, extent)
| IN | datatype | тип данных (дескриптор) | |
| OUT | extent | экстент типа данных (целое) |
int MPI_Type_extent(MPI_Datatype datatype, MPI_Aint *extent) MPI_TYPE_EXTENT(DATATYPE, EXTENT, IERROR) INTEGER DATATYPE, EXTENT, IERROR
Функция MPI_TYPE_EXTENT возвращает экстент типа данных, где экстент определяется так, как описано в разделе 3.12.3.
Синтаксис функции MPI_TYPE_SIZE представлен ниже.
MPI_TYPE_SIZE (datatype, size)
| IN | datatype | тип данных (дескриптор) | |
| OUT | size | размер типа данных (целое) |
int MPI_Type_size(MPI_Datatype datatype, int *size) MPI_TYPE_SIZE(DATATYPE, SIZE, IERROR) INTEGER DATATYPE, SIZE, IERROR int MPI::Datatype::Get_size() const
Функция MPI_TYPE_SIZE возвращает общий размер в байтах элементов в сигнатуре типа, связанной с datatype; это общий размер данных в сообщении, которое было бы создано с этим типом данных. Элементы, которые появляются в типе данных несколько раз, подсчитываются с учетом их кратности.
При разработке MPI использовались наиболее привлекательные особенности ряда существующих компьютеров, поэтому на проектирование MPI оказали сильное влияние работы в IBM T. J. Watson Research Center [1,2], Intel's NX/2 [23], Express [22], nCUBE's Vertex [21], p4 [7,6], и PARMACS [5,8]. Другие важные вклады внесли Zipcode [24,25], Chimp [14,15], PVM [4,11], Chameleon [19], и PICL [18]. В работе по стандартизации MPI участвовало около 60 человек из 40 организаций, преимущественно из США и Европы. В разработку MPI были вовлечены большинство основных поставщиков параллельных компьютеров, исследователи из университетов, правительственных лабораторий и промышленности. Процесс стандартизации начался с рабочего совещания по стандартам для передачи сообщений в среде распределенной памяти (the Workshop on Standards for Message Passing in a Distributed Memory Environment). Спонсором совещания, которое состоялось 29-30 апреля 1992 года в Williamsburg, Virginia, был Центр исследований по параллельным вычислениям (the Center for Research on Parallel Computing) [29].
На этом совещании были обсуждены главные особенности стандарта интерфейса для передачи сообщений и были созданы рабочие группы для продолжения процесса стандартизации.
Предварительные предложения, известные как MPI-1, были сделаны Dongarra, Hempel, Hey, Walker в ноябре 1992 года и после ревизиии эта версия была завершена в феврале 1993 года. MPI-1 включал главное из того, что на рабочем совещании в Williamsburg было признано необходимым иметь в стандарте передачи сообщений. MPI-1 первоначально был в основном сфокусирован на парных обменах (point-to-point communications). MPI-1 поднял много важных проблем стандартизации, но не включал никаких процедур для коллективных обменов и не поддерживал обработку потоков.
В ноябре 1992 года в Minneapolis состоялась встреча рабочей группы по MPI, на которой было решено поставить процесс стандартизации на более формальную основу и вообще адаптировать процедуры и организацию the High Performance Fortran Forum. На встрече были сформированы подкомитеты по главным компонентам сферы стандартизации и для каждого подкомитета был установлен дискуссионный почтовый сервис. В дополнение к этому, срок представления проекта стандарта MPI был установлен на осень 1993 года. Чтобы достичь этой цели, рабочая группа MPI встречалась каждые 6 недель на два дня первые 9 месяцев 1993 года и представила проект стандарта на конференции ``Supercomputing 93'' в ноябре 1993 года. Эти встречи и дискуссии по почте вместе создали MPI Форум, членство в котором стало открытым для всех членов сообщества высоких компьютерных технологий.
Главное преимущество создания стандарта передачи сообщений состоит в его мобильности (portability) и простоте использования. В коммуникационной среде с распределенной памятью, в которой высший уровень процедур и/или абстракций построен над слоем процедур передачи сообщений, выгода стандартизации особенно очевидна. Более того, определение стандарта обеспечивает производителей четко определенным набором процедур, которые они могут эффективно реализовать или в некоторых случаях обеспечить аппаратную поддержку для них, увеличивая тем самым масштабируемость.
Целью MРI является создание широко используемого стандарта для написания программ на основе передачи сообщений. Следовательно, интерфейс должен быть практичным, мобильным, эффективным и гибким стандартом для передачи сообщений.
Полный список целей таков:
Часто удобно явно указать нижнюю и верхнюю границы карты типа. Это позволяет определить тип данных, который имеет ``дыры'' в начале или конце, или тип с элементами, которые идут выше верхней или ниже нижней границы. Пример такого использования представлен в разделе 3.12.7. Пользователь также может пожелать обойти правила выравнивания для некоторых структур внутри программ. Пользователь может явно описать границы типа данных, которые соответствуют этим структурам.
Чтобы достичь этого, вводятся два дополнительных ``псевдо-типа данных'': MPI_LB и MPI_UB, которые могут быть использованы соответственно для маркировки нижней и верхней границ типа данных. Эти псевдотипы не занимают места (экстент(MPI_LB)= экстент (MPI_UB)= 0). Они не меняют size или count типа данных и не влияют на содержание сообщения, созданного с этим типом данных. Однако они влияют на определение экстента типа данных и, следовательно, влияют на результат репликации этого типа данных конструктором типа данных.
Пример 3.26 Пусть D = (-3, 0, 6); T = (MPI_LB, MPI_INT, MPI_UB), и B = (1, 1, 1). Тогда обращение к MPI_TYPE_STRUCT(3, B, D, T, type1) создает новый тип данных, который имеет экстент величиной 9 (от -3 до 5, 5) и содержит целое значение на смещении 0. Это тип данных, определенный последовательностью {(lb, -3), (int, 0), (ub, 6)}. Если этот тип повторяется дважды вызовом MPI_TYPE_CONTIGUOUS(2, type1, type2), тогда вновь созданный тип может быть описан последовательностью {(lb, -3), (int, 0), (int,9), (ub, 15)}. (Входной тип ub может быть удален, если имеется другой входной тип ub с более высоким смещением; входной тип lb может быть удален, если имеется другой входной тип lb с более низким смещением).
Две функции ниже могут быть использованы для нахождения нижней и верхней границ типа данных.
Синтаксис функции MPI_TYPE_LB представлен ниже.
MPI_TYPE_LB(datatype, displacement)
| IN | datatype | тип данных (дескриптор) | |
| OUT | displacement | смещение нижней границы от исходной в байтах (целое) |
int MPI_Type_lb(MPI_Datatype datatype, MPI_Aint* displacement) MPI_TYPE_LB(DATATYPE, DISPLACEMENT, IERROR) INTEGER DATATYPE, DISPLACEMENT, IERROR
Синтаксис функции MPI_TYPE_UB представлен ниже.
MPI_TYPE_UB(datatype, displacement)
| IN | datatype | тип данных (дескриптор) | |
| OUT | displacement | смещение верхней границы от исходной в байтах (целое) |
int MPI_Type_ub(MPI_Datatype datatype, MPI_Aint* displacement) MPI_TYPE_UB(DATATYPE, DISPLACEMENT, IERROR) INTEGER DATATYPE, DISPLACEMENT, IERROR
Объекты типов данных должны быть объявлены (committed) перед их использованием в коммуникациях. Объявленный тип данных может быть использован как аргумент в конструкторах типов данных. Базисные типы данных объявлять не нужно, поскольку они ``предобъявлены'' (``pre-committed'').
Синтаксис функции MPI_TYPE_COMMIT представлен ниже.
MPI_TYPE_COMMIT(datatype)
| INOUT | datatype | тип данных, который объявляется (дескриптор) |
int MPI_Type_commit(MPI_Datatype *datatype) MPI_TYPE_COMMIT(DATATYPE, IERROR) INTEGER DATATYPE, IERROR void MPI::Datatype::Commit()
Операция commit объявляет тип данных, то есть формально описывает коммуникационный буфер, но не содержимое этого буфера. Поэтому после того, как тип данных объявлен, он может быть многократно использован, чтобы передавать изменяемое содержимое буфера или различных буферов с различными стартовыми адресами.
Совет разработчикам: Система может во время объявления ``компилировать'' внутреннее представление для типа данных, которое облегчает коммуникации, например, перейти от компактного представления типа данных к прямому, и выбирать наиболее удобный механизм передачи.[]
Синтаксис функции MPI_TYPE_FREE представлен ниже.
MPI_TYPE_FREE(datatype)
| INOUT | datatype | тип данных, который удаляется (дескриптор) |
int MPI_Type_free(MPI_Datatype *datatype) MPI_TYPE_FREE (DATATYPE, IERROR) INTEGER DATATYPE, IERROR void MPI::Datatype::Free()
Функция MPI_TYPE_FREE маркирует объекты типа данных, связанные с datatype для удаления и установки типа данных в MPI_DATATYPE_NULL. Любой обмен, который использует этот тип данных, будет завершен нормально. Производные типы данных, которые произошли от удаленного типа, не меняются.
Пример 3.27 Следующий фрагмент кода дает пример использования MPI_TYPE_COMMIT.
INTEGER type1, type2
CALL MPI_TYPE_CONTIGUOUS(5, MPI_REAL, type1, ierr)
! создан новый объект типа данных
CALL MPI_TYPE_COMMIT(type1, ierr)
! теперь type1 может быть использован для обмена
type2 = type1
! type2 может быть использован для обмена
! (это дескриптор к такому же объекту как type1)
CALL MPI_TYPE_VECTOR(3, 5, 4, MPI_REAL, type1, ierr)
! создан новый необъявленный объект типа
CALL MPI_TYPE_COMMIT(type1, ierr)
! теперь type1 может быть использован снова для обмена
Удаление типа данных не воздействует на другой тип, который является производным от удаленного типа. Система ведет себя, как если бы аргументы входного типа данных были переданы конструктору производного типа данных по значению.
Совет разработчикам: Реализация может вести подсчет активных коммуникаций, которые используют некоторый тип данных, чтобы решить, когда удалить его. Кроме того, можно реализовать конструкторы производных типов так, чтобы они хранили указатели на аргументы их типа данных, а не копировали их. В этом случае нужно хранить трек активных ссылок на определения типа данных, чтобы знать, когда объект типа данных может быть освобожден.[]
Дескрипторы производных типов данных могут быть переданы в коммуникационный вызов, где бы ни потребовался аргумент типа данных. Вызов вида MPI_SEND (buf, count, datatype , ...), где count > 1, интерпретируется как если бы вызов был передан новому типу данных, который является конкатенацией некоторого числа копий типа данных. Поэтому MPI_SEND (buf, count, datatype, dest, tag, comm) эквивалентен:
MPI_TYPE_CONTIGUOUS(count, datatype, newtype) MPI_TYPE_COMMIT(newtype) MPI_SEND(buf, 1, newtype, dest, tag, comm).
Аналогичное утверждение применимо ко всем коммуникационным функциям, которые имеют аргументы count и datatype.
Предположим, что выполнена операция передачи MPI_SEND(buf,
count, datatype, dest,
tag, comm), где тип задается картой:
{(type0, disp0),...,(typen-1, dispn-1)},
и экстентом extent. (Пустые элементы ``псевдотипа'' MPI_UB и MPI_LB не указаны в карте типа, но они влияют на
значение extent). Операция передачи посылает
![]() элементов, где элемент
элементов, где элемент
![]() находится
в ячейке с адресом addr
находится
в ячейке с адресом addr![]() = buf + extent
= buf + extent ![]() i + disp
i + disp![]() и имеет тип type
и имеет тип type![]() , for
i = 0 ,..., count-1 and j = 0 ,..., n-1. Эти
элементы не обязаны быть ни смежными, ни различными; их порядок может быть
произвольным.
, for
i = 0 ,..., count-1 and j = 0 ,..., n-1. Эти
элементы не обязаны быть ни смежными, ни различными; их порядок может быть
произвольным.
Переменная, хранимая по адресу addr![]() в
вызывающей подпрограмме должна иметь тип, соответствующий type
в
вызывающей подпрограмме должна иметь тип, соответствующий type![]() , где типовое соответствие определяется как в разделе
3.3.1. Посланное сообщение содержит n
, где типовое соответствие определяется как в разделе
3.3.1. Посланное сообщение содержит n ![]() count элементов,
где элемент i
count элементов,
где элемент i ![]() n +j имеет тип type
n +j имеет тип type![]() .
.
Аналогично предположим, что выполнена операция приема MPI_RECV (buf, count, datatype, source, tag, comm, status), где тип данных имеет карту
{(type0, disp0) ,...,(typen-1, dispn-1) },
с экстентом extent. (Опять пустые элементы ``псевдотипа''
не указываются в списке карты, но они влияют на значение extent). Эта операция принимает n ![]() countэлементов, где элемент i
countэлементов, где элемент i ![]() n + j есть в ячейке buf + extent
n + j есть в ячейке buf + extent ![]() i + disp
i + disp![]() и имеет тип type
и имеет тип type![]() .
Если входящее сообщение состоит из k элементов, тогда мы обязаны
иметь k<=n
.
Если входящее сообщение состоит из k элементов, тогда мы обязаны
иметь k<=n![]() count; элемент i
count; элемент i ![]() n + j
должен иметь тип, соответствующий type
n + j
должен иметь тип, соответствующий type![]() .
.
Соответствие типа определяется согласно типу сигнатуры соответствующих типов данных, то есть последовательностью компонент базисного типа данных. Соответствие типов не зависит от некоторых аспектов определения типа данных, таких как смещение (расположение в памяти) или использованных промежуточных типов.
Пример 3.28 Этот пример показывает, что типовое соответствие определяется в терминах базисного типа, из которого состоит производный тип.
... CALL MPI_TYPE_CONTIGUOUS(2, MPI_REAL, type2, ...) CALL MPI_TYPE_CONTIGUOUS(4, MPI_REAL, type4, ...) CALL MPI_TYPE_CONTIGUOUS(2, type2, type22, ...) ... CALL MPI_SEND(a, 4, MPI_REAL, ...) CALL MPI_SEND(a, 2, type2, ...) CALL MPI_SEND(a, 1, type22, ...) CALL MPI_SEND(a, 1, type4, ...) ... CALL MPI_RECV(a, 4, MPI_REAL, ...) CALL MPI_RECV(a, 2, type2, ...) CALL MPI_RECV(a, 1, type22, ...) CALL MPI_RECV(a, 1, type4, ...)
Каждая из этих передач соответствует любой операции приема.
Тип данных может описывать перекрывающиеся элементы. Использование такого типа в операциях приема неверно. (Это неверно, даже если полученное сообщение достаточно короткое, чтобы не записывать любой элемент более, чем однажды).
Предположим, что выполнена операция MPI_RECV (buf, count, datatype, dest, tag, comm, status), где тип данных таков
{(type0, disp0) ,...,(typen-1, dispn-1).
Принятое сообщение не обязано ни заполнять весь буфер, ни заполнять число
ячеек, которое кратно n. Может быть принято любое число k базисных элементов, где 0 ![]() k
k ![]() count
count ![]() n. Количество полученных базисных элементов
может быть получено из статуса с помощью функции MPI_GET_ELEMENTS.
n. Количество полученных базисных элементов
может быть получено из статуса с помощью функции MPI_GET_ELEMENTS.
Синтаксис функции MPI_GET_ELEMENTS представлен ниже.
MPI_GET_ELEMENTS(status, datatype, count)
| IN | status | возвращает статус операции приема (статус) | |
| IN | datatype | тип данных операции приема (дескриптор) | |
| OUT | count | число принятых базисных элементов (целое) |
int MPI_Get_elements(MPI_Status *status, MPI_Datatype datatype, int *count) MPI_GET_ELEMENTS(STATUS, DATATYPE, COUNT, IERROR) INTEGER STATUS(MPI_STATUS_SIZE), DATATYPE, COUNT, IERROR int MPI::Status::Get_elements(const MPI::Datatype& datatype) const
Ранее определенная функция MPI_GET_COUNT (раздел 3.2.5) имеет
различное поведение. Она возвращает количество полученных ``элементов
верхнего уровня'', то есть количество ``копий'' типа данных. В предыдущем
примере MPI_GET_COUNT может возвратить любое целое число k, где 0 ![]() k
k ![]() count
count ![]() n. Если MPI_GET_COUNT возвращает k,
тогда число принятых базисных элементов (и значение, возвращенное
MPI_GET_ELEMENTS) есть n
n. Если MPI_GET_COUNT возвращает k,
тогда число принятых базисных элементов (и значение, возвращенное
MPI_GET_ELEMENTS) есть n ![]() k. Если число
полученных базисных элементов не кратно n, то есть операция
приема не получила общее число ``копий'' datatype, то
MPI_GET_COUNT возвращает значение MPI_UNDEFINED.
k. Если число
полученных базисных элементов не кратно n, то есть операция
приема не получила общее число ``копий'' datatype, то
MPI_GET_COUNT возвращает значение MPI_UNDEFINED.
Пример 3.29 Использование MPI_GET_COUNT и MPI_GET_ELEMENT
...
CALL MPI_TYPE_CONTIGUOUS(2, MPI_REAL, Type2, ierr)
CALL MPI_TYPE_COMMIT(Type2, ierr)
...
CALL MPI_COMM_RANK(comm, rank, ierr)
IF(rank.EQ.0) THEN
CALL MPI_SEND(a, 2, MPI_REAL, 1, 0, comm, ierr)
CALL MPI_SEND(a, 3, MPI_REAL, 1, 0, comm, ierr)
ELSE
CALL MPI_RECV(a, 2, Type2, 0, 0, comm, stat, ierr)
CALL MPI_GET_COUNT(stat, Type2, i, ierr) ! возвращает i=1
CALL MPI_GET_ELEMENTS(stat, Type2, i, ierr) ! возвращает i=2
CALL MPI_RECV(a, 2, Type2, 0, 0, comm, stat, ierr)
CALL MPI_GET_COUNT(stat,Type2,i,ierr) ! возвращает
! i=MPI_UNDEFINED
CALL MPI_GET_ELEMENTS(stat, Type2, i, ierr) ! возвращает i=3
END IF
Функция MPI_GET_ELEMENTS также может использоваться после операции probe, чтобы найти число элементов в опробованном сообщении. Заметим, что две функции MPI_GET_COUNT и MPI_GET_ELEMENTS возвращают то же самое значение, когда они используются с базисным типом данных.
Объяснение: Расширение, данное в определении MPI_GET_COUNT, представляется естественным: хотелось бы, чтобы эта функция возвращала значение аргумента count, когда приемный буфер полон. Иногда datatype представляет базисную единицу данных, которую желательно передать, например, запись в массиве записей (структур). Хотелось бы обладать возможностью выяснять, как много компонентов было получено, без забот о разделении числа элементов в каждом компоненте. Однако в другом случае тип данных используется для определения комплексного размещения данных в приемной памяти и не представляет базисную единицу данных для передачи. В таких случаях необходимо использовать функцию MPI_GET_ELEMENTS. []
Совет пользователям: Определение MPI требует, чтобы прием не изменял памяти вне элементов, определенных в качестве составляющих буфера. В частности, определение говорит, что заполненное пространство в структуре не может модифицироваться, когда такая структура скопирована из одного процесса в другой. Это ограничивало бы очевидную оптимизацию копирования структуры вместе с заполнением как один непрерывный блок. Реализация MPI свободна делать такую оптимизацию, если она не воздействует на результат вычислений. Пользователь может ``создать'' эту оптимизацию явным включением заполнения как части сообщения.[]
Переменные, последовательно декларированные в языках Си или ФОРТРАН, не обязательно хранятся в смежных ячейках. Поэтому необходимо, чтобы смещения этих переменных не пересекались. К тому же в машине с сегментным адресным пространством адреса не уникальны, и адресная арифметика имеет некоторые необычные свойства. Поэтому использование addresses, то есть смещений относительно стартового адреса MPI_BOTTOM должно быть ограничено.
Переменные принадлежат той же самой последовательной памяти, если они принадлежат тому же массиву, тому же COMMON блоку в языке ФОРТРАН или той же самой структуре в языке Си.
Приведенные выше правила не ограничивают использование производных типов до тех пор, пока они определяют коммуникационный буфер, который целиком расположен в той же самой последовательной памяти. Однако, конструкция коммуникационного буфера, которая содержит переменные, не находящиеся внутри той же самой последовательной памяти, обязана иметь определенные ограничения. В общем случае коммуникационный буфер с переменными вне той же самой последовательной памяти может быть использован только путем описания в коммуникационном вызове buf = MPI_BOTTOM, count = 1, и c использованием аргумент типа данных, где все смещения есть правильные (абсолютные) адреса.
Совет пользователям: Трудно ожидать, что реализации MPI будут способны определять ошибки выхода смещения ``за границы'', если это не переполнение пространства пользователя, поскольку вызов MPI может не знать участок массива и записи в хост программе.[]
Совет разработчикам: Нет никакой необходимости различать адреса (абсолютные) и смещения (относительные) на машине с непрерывным адресным пространством: MPI_BOTTOM есть ноль и оба адреса и смещения есть целые. На машинах, где требуется различие, адреса распознаются как выражения, которые используют MPI_BOTTOM.[]
Заметим, что числа INTEGER в языке ФОРТРАН могут быть слишком малы, чтобы поддерживать адреса (например, 32-разрядные INTEGER на машине с 64-разрядными ссылками). Вследствие этого в языке ФОРТРАН реализации MPI могут ограничивать использование абсолютных адресов только частью памяти процессов и ограничивать использование относительных смещений подразделами памяти процессов, ограниченых размером типа INTEGER языка ФОРТРАН.
Следующие примеры демонстрируют использование производных типов данных
Пример 3.30 Передача и прием секции 3D массива.
REAL a(100,100,100), e(9,9,9)
INTEGER oneslice, twoslice, threeslice, sizeofreal, myrank,
ierr
INTEGER status(MPI_STATUS_SIZE)
C извлекает секцию a(1:17:2, 3:11, 2:10)
C и запоминает ее в e(:,:,:).
CALL MPI_COMM_RANK(MPI_COMM_WORLD, myrank)
CALL MPI_TYPE_EXTENT(MPI_REAL, sizeofreal, ierr)
C создает тип данных для секции 1D
CALL MPI_TYPE_VECTOR(9, 1, 2, MPI_REAL, oneslice, ierr)
C создает тип данных для секции 2D
CALL MPI_TYPE_HVECTOR(9, 1, 100*sizeofreal, oneslice, twoslice,
ierr)
C создает тип данных для секции в целом
CALL MPI_TYPE_HVECTOR(9, 1, 100*100*sizeofreal, twoslice,
threeslice, ierr)
CALL MPI_TYPE_COMMIT(threeslice, ierr)
CALL MPI_SENDRECV(a(1,3,2), 1, threeslice, myrank, 0, e, 9*9*9,
MPI_REAL, myrank, 0, MPI_COMM_WORLD, status,
ierr)
Пример 3.31 Копирование (строгое) нижней треугольной части матрицы
REAL a(100,100), b(100,100)
INTEGER disp(100), blocklen(100), ltype, myrank, ierr
INTEGER status(MPI_STATUS_SIZE)
C копирует нижнюю треугольную часть массива a
C в нижнюю треугольную часть массива b
CALL MPI_COMM_RANK(MPI_COMM_WORLD, myrank)
C вычисляет начало и размер каждого столбца
DO i=1, 100
disp(i) = 100*(i-1) + i
block(i) = 100-i
END DO
C создает тип данных для нижней треугольной части
CALL MPI_TYPE_INDEXED(100, block, disp, MPI_REAL, ltype, ierr)
CALL MPI_TYPE_COMMIT(ltype, ierr)
CALL MPI_SENDRECV(a, 1, ltype, myrank, 0, b, 1,
ltype, myrank, 0, MPI_COMM_WORLD, status, ierr)
Пример 3.32 Транспонирование матрицы.
REAL a(100,100), b(100,100)
INTEGER row, xpose, sizeofreal, myrank, ierr
INTEGER status(MPI_STATUS_SIZE)
C транспонирование матрицы a в матрицу b
CALL MPI_COMM_RANK(MPI_COMM_WORLD, myrank)
CALL MPI_TYPE_EXTENT(MPI_REAL, sizeofreal, ierr)
C создание типа данных для одной строки
CALL MPI_TYPE_VECTOR(100, 1, 100, MPI_REAL, row, ierr)
C создание типа данных для матрицы с расположением по строкам
CALL MPI_TYPE_HVECTOR(100, 1, sizeofreal, row, xpose, ierr)
CALL MPI_TYPE_COMMIT(xpose, ierr)
C посылка матрицы с расположением по строкам и получение матрицы
С с расположением по столбцам
CALL MPI_SENDRECV(a, 1, xpose, myrank, 0, b, 100*100,
MPI_REAL, myrank, 0, MPI_COMM_WORLD, status, ierr)
Пример 3.33 Другой подход к проблеме транспонирования:
REAL a(100,100), b(100,100)
INTEGER disp(2), blocklen(2), type(2), row, row1, sizeofreal
INTEGER myrank, ierr
INTEGER status(MPI_STATUS_SIZE)
CALL MPI_COMM_RANK(MPI_COMM_WORLD, myrank)
C транспонирование матрицы a в матрицу b
CALL MPI_TYPE_EXTENT(MPI_REAL, sizeofreal, ierr)
C создание типа данных для одной строки
CALL MPI_TYPE_VECTOR(100, 1, 100, MPI_REAL, row, ierr)
C создание типа данных для одной строки
disp(1) = 0
disp(2) = sizeofreal
type(1) = row
type(2) = MPI_UB
blocklen(1) = 1
blocklen(2) = 1
CALL MPI_TYPE_STRUCT(2, blocklen, disp, type, row1, ierr)
CALL MPI_TYPE_COMMIT(row1, ierr)
C посылка 100 строк и получение с расположением по столбцам
CALL MPI_SENDRECV(a, 100, row1, myrank, 0, b, 100*100,
MPI_REAL, myrank, 0, MPI_COMM_WORLD, status, ierr)
Пример 3.34 Манипуляция с массивом структур.
struct Partstruct
{
int class; /* класс частицы */
double d[6]; /* координаты частицы */
char b[7]; /* некоторая дополнительная информация */
};
struct Partstruct particle[1000];
int i, dest, rank;
MPI_Comm comm;
/* построение типа данных описываемой структуры */
MPI_Datatype Particletype;
MPI_Datatype type[3] = {MPI_INT, MPI_DOUBLE, MPI_CHAR};
int blocklen[3] = {1, 6, 7};
MPI_Aint disp[3];
int base;
/* вычисление смещений элементов структуры */
MPI_Address(particle, disp);
MPI_Address(particle[0].d, disp+1);
MPI_Address(particle[0].b, disp+2);
base = disp[0];
for (i=0; i <3; i++) disp[i] -= base;
MPI_Type_struct(3, blocklen, disp, type, &Particletype);
MPI_Datatype type1[4] = {MPI_INT, MPI_DOUBLE, MPI_CHAR, MPI_UB};
int blocklen1[4] = {1, 6, 7, 1};
MPI_Aint disp1[4];
/* вычисление смещений элементов структуры */
MPI_Address(particle, disp1);
MPI_Address(particle[0].d, disp1+1);
MPI_Address(particle[0].b, disp1+2);
MPI_Address(particle+1, disp1+3);
base = disp1[0];
for (i=0; i <4; i++) disp1[i] -= base;
/* построение типа данных описываемой структуры */
MPI_Type_struct(4, blocklen1, disp1, type1, &Particletype);
/* 4.1:
посылка массива целиком */
MPI_Type_commit(&Particletype);
MPI_Send(particle, 1000, Particletype, dest, tag, comm);
/* 4.2:
посылка только элементов класса нулевых частиц, предваряемых
количеством таких элементов */
MPI_Datatype Zparticles; /* тип данных, описывающий все частицы
класса нуль (необходимо повторное
вычисление , если класс изменяется) */
MPI_Datatype Ztype;
MPI_Aint zdisp[1000];
int zblock[1000], j, k;
int zzblock[2] = {1,1};
MPI_Aint zzdisp[2];
MPI_Datatype zztype[2];
/* вычисление смещений класса нулевых частиц */
j = 0;
for(i=0; i < 1000; i++)
if (particle[i].class==0)
{
zdisp[j] = i;
zblock[j] = 1;
j++;
}
/* создание типа данных для класса нулевых частиц */
MPI_Type_indexed(j, zblock, zdisp, Particletype, &Zparticles);
/* количество частиц */
MPI_Address(&j, zzdisp);
MPI_Address(particle, zzdisp+1);
zztype[0] = MPI_INT;
zztype[1] = Zparticles;
MPI_Type_struct(2, zzblock, zzdisp, zztype, &Ztype);
MPI_Type_commit(&Ztype);
MPI_Send(MPI_BOTTOM, 1, Ztype, dest, tag, comm);
/* возможно более эффективный путь определения Zparticles */
/* последовательные частицы с индексом нуль обрабатываются как один блок */
j=0;
for (i=0; i < 1000; i++)
if (particle[i].index==0)
{
for (k=i+1; (k < 1000)&&(particle[k].index == 0) ; k++);
zdisp[j] = i;
zblock[j] = k-i;
j++;
i = k;
}
MPI_Type_indexed(j, zblock, zdisp, Particletype, &Zparticles);
/* 4.3:
посылка первых двух координат всем элементам */
MPI_Datatype Allpairs; /* datatype for all pairs of coordinates */
MPI_Aint sizeofentry;
MPI_Type_extent(Particletype, &sizeofentry);
/* размер элемента также может быть вычислен вычитанием адреса
particle[0] из адреса particle[1] */
MPI_Type_hvector(1000, 2, sizeofentry, MPI_DOUBLE, &Allpairs);
MPI_Type_commit(&Allpairs);
MPI_Send(particle[0].d, 1, Allpairs, dest, tag, comm);
/* альтернативное решение для 4.3 */
MPI_Datatype Onepair; /* тип данных для одной пары координат */
MPI_Aint disp2[3];
MPI_Datatype type2[3] = {MPI_LB, MPI_DOUBLE, MPI_UB};
int blocklen2[3] = {1, 2, 1};
MPI_Address(particle, disp2);
MPI_Address(particle[0].d, disp2+1);
MPI_Address(particle+1, disp2+2);
base = disp2[0];
for (i=0; i<2; i++) disp2[i] -= base;
MPI_Type_struct(3, blocklen2, disp2, type2, &Onepair);
MPI_Type_commit(&Onepair);
MPI_Send(particle[0].d, 1000, Onepair, dest, tag, comm);
Пример 3.35 Те же манипуляции, как и в предыдущем примере, но с использованием абсолютных адресов в типах данных.
struct Partstruct
{
int class;
double d[6];
char b[7];
};
struct Partstruct particle[1000];
/* строится тип данных, описывающий первый элемент массива */
MPI_Datatype Particletype;
MPI_Datatype type[3] = {MPI_INT, MPI_DOUBLE, MPI_CHAR};
int block[3] = {1, 6, 7};
MPI_Aint disp[3];
MPI_Address(particle, disp);
MPI_Address(particle[0].d, disp+1);
MPI_Address(particle[0].b, disp+2);
MPI_Type_struct(3, block, disp, type, &Particletype);
/* тип частицы описывает первый элемент массива - используя
абсолютные адреса */
/* 5.1:
посылка массива целиком */
MPI_Type_commit(&Particletype);
MPI_Send(MPI_BOTTOM, 1000, Particletype, dest, tag, comm);
/* 5.2:
посылка элементов класса нуль,
предваряемых числом таких элементов */
MPI_Datatype Zparticles, Ztype;
MPI_Aint zdisp[1000]
int zblock[1000], i, j, k;
int zzblock[2] = {1,1};
MPI_Datatype zztype[2];
MPI_Aint zzdisp[2];
j=0;
for (i=0; i < 1000; i++)
if (particle[i].index==0)
{
for (k=i+1; (k < 1000)&&(particle[k].index = 0) ; k++);
zdisp[j] = i;
zblock[j] = k-i;
j++;
i = k;
}
MPI_Type_indexed(j, zblock, zdisp, Particletype, &Zparticles);
/* Zparticles описывают частицы класса нуль,
используя их абсолютные адреса*/
/* количество частиц */
MPI_Address(&j, zzdisp);
zzdisp[1] = MPI_BOTTOM;
zztype[0] = MPI_INT;
zztype[1] = Zparticles;
MPI_Type_struct(2, zzblock, zzdisp, zztype, &Ztype);
MPI_Type_commit(&Ztype);
MPI_Send(MPI_BOTTOM, 1, Ztype, dest, tag, comm);
Пример 3.36 Обработка объединений (unions).
union {
int ival;
float fval;
} u[1000]
int utype;
/* все элементы uмеют идентичный тип; переменная
utype хранит трек их текущего типа */
MPI_Datatype type[2];
int blocklen[2] = {1,1};
MPI_Aint disp[2];
MPI_Datatype mpi_utype[2];
MPI_Aint i,j;
/* вычисляет тип данных MPI для каждого возможного типа union;
считаем, что значения в памяти union выровнены по левой границе. */
MPI_Address(u, &i);
MPI_Address(u+1, &j);
disp[0] = 0; disp[1] = j-i;
type[1] = MPI_UB;
type[0] = MPI_INT;
MPI_Type_struct(2, blocklen, disp, type, &mpi_utype[0]);
type[0] = MPI_FLOAT;
MPI_Type_struct(2, blocklen, disp, type, &mpi_utype[1]);
for(i=0; i<2; i++) MPI_Type_commit(&mpi_utype[i]);
/* фактический обмен */
MPI_Send(u, 1000, mpi_utype[utype], dest, tag, comm);
MPI-2 замещает некоторые функции конструирования и доступа, определенные в MPI-1, по следующим двум причинам.
Ниже дается список устаревших функций и констант MPI-1 с их определениями для языков Си и ФОРТРАН и приводится их замена. Как обычно устаревшие функции продолжают оставаться частью стандарта MPI, однако пользователю настоятельно рекомендуется использовать новые функции, где это возможно (см. раздел 1.9.1 о статусе устаревших функций).
MPI_TYPE_EXTENT(datatype, extent)
int MPI_Type_extent (MPI_Datatype datatype, MPI_Aint *extent)
MPI_TYPE_EXTENT (DATATYPE, EXTENT, ERROR)
INTEGER DATATYPE, EXTENT, IERROR
MPI_TYPE_LB(datatype, displacement)
int MPI_Type_lb(MPI_Datatype datatype, MPI_Aint* displacement)
MPI_TYPE_LB (DATATYPE, DISPLACEMENT, IERROR)
INTEGER DATATYPE, DISPLACEMENT, IERROR
MPI_TYPE_UB (datatype, displacement)
int MPI_Type_ub (MPI_Datatype datatype, MPI_Aint* displacement)
MPI_TYPE_UB (DATATYPE, DISPLACEMENT, IERROR)
INTEGER DATATYPE, DISPLACEMENT, IERROR
Эти три функции замещаются функцией MPI_TYPE_GET_EXTENT (datatype, extent, lb). Новая функция возвращает в одном вызове нижнюю границу и экстент типа данных, на основе которых может быть вычислена верхняя граница; в MPI-1 каждый из этих трех параметров возвращался отдельным вызовом. Более того, представление старых функций в языке ФОРТРАН указывает, что возвращаемое значение имеет тип INTEGER, в то время, как новая функция возвращает аргумент типа INTEGER (KIND=MPI_ADDRESS_KIND).
MPI_TYPE_HVECTOR(count, blocklength, stride, oldtype, newtype) int MPI_Type-hvector (int count, int blocklength, MPI_Aint stride, MPI_Datatype oldtype, MPI_Datatype *newtype) MPI_TYPE_HVECTOR (COUNT, BLOCKLENGTH, STRIDE, OLDTYPE, NEWTYPE, IERROR) INTEGER COUNT, BLOCKLENGTH, STRIDE, OLDTYPE, NEWTYPE, IERROR
Функция MPI_TYPE_HVECTOR замещается функцией MPI_TYPE_CREATE_HVECTOR (count,
blocklength, stride, oldtype,
newtype). Нейтральное в отношении языка определение и вызов для языка
Си - те же самые. Вызов для языка ФОРТРАН отличается в том, что
старая функция использовала аргумент INTEGER STRIDE, а новая функция
использует аргумент типа INTEGER (KIND=MPI_ADDRESS_KIND).
MPI_TYPE_HINDEXED(count, array_of_blocklengths,
array_of_displacements, old_type, newtype)
int MPI_Type_hindexed (int count, int *array_of_blocklengths,
MPI_Aint *array_of_displacements, MPI_Datatype oldtype,
MPI_Datatype *newtype)
MPI_TYPE_HINDEXED (COUNT, ARRAY_OF_BLOCKLENGTHS,
ARRAY_OF_DISPLACEMENTS, OLDTYPE, NEWTYPE, IERROR)
INTEGER COUNT, ARRAY_OF_BLOCKLENGTHS (*),
ARRAY_OF_DISPLACEMENTS (*), OLDTYPE, NEWTYPE, IERROR
Эта функция замещается функцией
MPI_TYPE_CREATE_HINDEXED(count,
array_of_blocklengths,
array_ of_displacements, oldtype, newtype).
Нейтральное определение и вызов для языка Си - те же самые.
В языке ФОРТРАН для старой функции используется аргумент
INTEGER ARRAY_OF_DISPLACEMENTS(*), а новая функция использует аргумент
типа INTEGER (KIND=MPI_ADDRESS_KIND).
MPI_TYPE_STRUCT(count, array_of_blocklengths, array_of_displacements,
array_of_types, newtype)
int MPI_Type_struct (int count, int *array_of_blocklengths,
MPI_Aint *array_of_displacements, MPI_Datatype *array_of_types,
MPI_Datatype *newtype)
MPI_TYPE_STRUCT(COUNT, ARRAY_OF_BLOCKLENGTHS, AR-RAY_OF_DISPLACEMENTS,
ARRAY_OF_TYPES, NEWTYPE, IERROR) INTEGER COUNT,
ARRAY_OF_BLOCKLENGTHS (*), ARRAY_OF_DISPLACEMENTS),
AR-RAY_OF-TYPES (*), NEWTYPE, IERROR
MPI_TYPE_STRUCT замещается функцией
MPI_TYPE_CREATE_STRUCT(count,
array_of_blocklengths,
array_of_displacements, array_of_types, newtype).
В языке
ФОРТРАН старая функция использовала аргумент
INTEGER ARRAY_OF_DISPLACEMENTS), а новая использует аргумент
типа INTEGER(KIND=MPI_ADDRESS_KIND).
MPI_ADDRESS (location, address)
int MPI_Address (void* location, MPI_Aint *address)
MPI_ADDRESS (LOCATION, ADDRESS, IERROR)
<type> LOCATION (*)
INTEGER ADDRESS, IERROR
Эта функция замещается функцией MPI_GET_ADDRESS(location,
address). Нейтральное языковое определение и обращение в языке Си -
те же самые. В языке ФОРТРАН старая функция использовала аргумент
INTEGER ADDRESS, а новая функция использует аргумент типа
INTEGER(KIND=MPI_ADDRESS_KIND).
Использование двух ``псевдотипов'' MPI_LB и MPI_UB
замещается обращением к функции
MPI_TYPE_CREATE_RESIZED.
Пример 3.37 Рассмотрим последовательность вызовов в примере 3.22. Тогда первый вызов может быть заменен следующим эквивалентным (MPI-1) кодом.
MPI_Datatype types [3]; MPI_Aint disps [3]; int blens [3]; types [0] = MPI_LB; types [1] = MPI_UB; types [2] = type0; disps [0] = -4; disps [1] = 8; disps [2] = 0; blens [0] = blens [1] = blens [2] = 1; MPI_Type_struct (3, blens, disps, types, &type l);
Кода, эквивалентного второму обращению к MPI_TYPE_CREATE_RESIZED, в MPI-1 не имеется. Это происходит, потому что этот вызов перемещает существующий маркер MPI_LB вверх, что не может быть сделано в MPI-1.
Ниже дается синтаксис ряда новых функций.
Синтаксис функции MPI_TYPE_CREATE_HVECTOR представлен ниже.
MPI_TYPE_CREATE_HVECTOR(count, blocklength, stride, oldtype, newtype)
| IN | count | число блоков (неотрицательное целое) | |
| IN | blocklength | число элементов в каждом блоке (неотрицательное целое) | |
| IN | stride | число байтов между началом каждого блока (целое) | |
| IN | oldtype | старый тип (дескриптор) | |
| OUT | newtype | новый тип (дескриптор) |
int MPI_Type_create_hvector (int count, int blocklength, MPI_Aint stride,
MPI_Datatype oldtype, MPI_Datatype *newtype)
MPI_TYPE_CREATE_HVECTOR(COUNT, BLOCKLENGTH, STIDE, OLDTYPE, NEWTYPE, IERROR)
INTEGER COUNT, BLOCKLENGTH, OLDTYPE, NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) STRIDE
MPI::Datatype MPI::Datatype::Create_hvector(int count,
int blocklength, MPI::Aint stride) const
Синтаксис функции MPI_TYPE_CREATE_HINDEXED представлен ниже.
MPI_TYPE_CREATE_HINDEXED(count, array_of_blocklengths,
array_of_displacements, oldtype, newtype)
| IN | count | число блоков (целое) | |
| IN | array_of_blocklengths | число элементов в каждом блоке (массив целых) | |
| IN | array_of_displacements | смещение каждого блока в байтах (массив целых) | |
| IN | oldtype | старый тип (дескриптор) | |
| OUT | newtype | новый тип (дескриптор) |
int MPI_Type_create_hindexed(int count, int array_of_blocklengths[],
MPI_Aint array_of_displacements[], MPI_Datatype oldtype,
MPI_Datatype *newtype)
MPI_TYPE_CREATE_HINDEXED(COUNT, ARRAY_OF_BLOCKLENGTHS,
ARRAY_OF_DISPLACEMENTS, OLDTYPE, NEWTYPE, IERROR)
INTEGER COUNT, ARRAY_OF_BLOCKLENGTHS(*), OLDTYPE, NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ARRAY_OF_DISPLACEMENTS(*)
MPI::Datatype MPI::Datatype::Create_hindexed(int count,
const int array_of_blocklengths[],
const MPI::Aint array_of_displacements[]) const
Синтаксис функции MPI_TYPE_CREATE_STRUCT представлен ниже.
MPI_TYPE_CREATE_STRUCT(count, array_of_blocklengths, array_of_displacements, array_of_types, newtype)
| IN | count | число блоков (целое) | |
| IN | array_of_blocklength | число элементов в каждом блоке (массив целых) | |
| IN | array_of_displacements | смещение каждого блока в байтах (массив целых) | |
| IN | array_of_types | тип элементов каждого блока (массив дескрипторов для объектов типа данных) | |
| OUT | newtype | новый тип (дескриптор) |
int MPI_Type_create_struct(int count,
int array_of_blocklengths[], MPI_Aint array_of_displacements[],
MPI_Datatype array_of_types[], MPI_Datatype *newtype)
MPI_TYPE_CREATE_STRUCT(COUNT, ARRAY_OF_BLOCKLENGTHS,
ARRAY_OF_DISPLACEMENTS, ARRAY_OF_TYPES, NEWTYPE, IERROR)
INTEGER COUNT, ARRAY_OF_BLOCKLENGTHS(*), ARRAY_OF_TYPES(*), NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) ARRAY_OF_DISPLACEMENTS(*)
static MPI::Datatype MPI::Datatype::Create_struct(
int count,
const int array_of_blocklengths[],
const MPI::Aint array_of_displacements[],
const MPI::Datatype array_of_types[])
Синтаксис функции MPI_GET_ADDRESS представлен ниже.
MPI_GET_ADDRESS(location, address)
| IN | location | ячейка в памяти (альтернатива) | |
| OUT | address | адрес ячейки (целое) |
int MPI_Get_address(void *location, MPI_Aint *address) MPI_GET_ADDRESS(LOCATION, ADDRESS, IERROR) <type> LOCATION(*) INTEGER IERROR INTEGER(KIND=MPI_ADDRESS_KIND) ADDRESS MPI::Aint MPI::Get_address(void* location)
Совет пользователям: Существующие программы MPI для
языка ФОРТРАН будут выполняться не модифицированными и будут подходить
к любой системе. Однако, они могут не выполняться, если в программе
используются адреса больше, чем 2![]() -1. Новые программы с новыми
функциями преодолевают этот недостаток, они также обеспечивают совместимость
с языками Си/С++. Однако, вновь написанные программы могут потребовать
небольшой переделки для совместимости со старой средой ФОРТРАН77,
которая не поддерживает декларации KIND.[]
-1. Новые программы с новыми
функциями преодолевают этот недостаток, они также обеспечивают совместимость
с языками Си/С++. Однако, вновь написанные программы могут потребовать
небольшой переделки для совместимости со старой средой ФОРТРАН77,
которая не поддерживает декларации KIND.[]
Синтаксис функции MPI_TYPE_GET_EXTENT представлен ниже.
MPI_TYPE_GET_EXTENT(datatype, lb, extent)
| IN | datatype | тип данных (дескриптор) | |
| OUT | lb | нижняя граница типа (целое) | |
| OUT | extent | экстент типа данных (целое) |
int MPI_Type_get_extent(MPI_Datatype datatype, MPI_Aint *lb, MPI_Aint *extent) MPI_TYPE_GET_EXTENT(DATATYPE, LB, EXTENT, IERROR) INTEGER DATATYPE, IERROR INTEGER(KIND = MPI_ADDRESS_KIND) LB, EXTENT void MPI::Datatype::Get_extent(MPI::Aint& lb, MPI::Aint& extent) const
Синтаксис функции MPI_TYPE_CREATE_RESIZED представлен ниже.
MPI_TYPE_CREATE_RESIZED(oldtype, lb, extent, newtype)
| IN | oldtype | входной тип данных (дескриптор) | |
| IN | lb | новая нижняя граница типа данных (целое) | |
| IN | extent | новый экстент типа данных (целое) | |
| OUT | newtype | выходной тип данных (дескриптор) |
int MPI_Type_create_resized(MPI_Datatype oldtype, MPI_Aint lb,
MPI_Aint extent, MPI_Datatype *newtype)
MPI_TYPE_CREATE_RESIZED(OLDTYPE, LB, EXTENT, NEWTYPE, IERROR)
INTEGER OLDTYPE, NEWTYPE, IERROR
INTEGER(KIND=MPI_ADDRESS_KIND) LB, EXTENT
MPI::Datatype MPI::Datatype::Resized(const MPI::Aint lb,
const MPI::Aint extent) const
Некоторые существующие библиотеки для передачи сообщений обеспечивают
функции вида
pack/unpack (распаковка и упаковка) для передачи
несмежных
данных. При этом пользователь явно пакует данные в смежный буфер перед их
посылкой и распаковывает смежный буфер при приеме. Производные типы данных,
которые описаны в разделе 3.12, позволяют в большинстве случаев избежать
упаковки и распаковки. Пользователь описывает размещение данных, которые
должны быть посланы или приняты и коммуникационная библиотека прямо
обращается в несмежный буфер. Процедуры pack/unpack обеспечивают
совместимость с предыдущими библиотеками. К тому же они обеспечивают
некоторые возможности, которые другим образом недоступны в MPI.
Например, сообщение может быть принято в нескольких частях, где приемная
операция, выполняемая для поздней части, может зависеть от содержания первой
части. Другое удобство состоит в том, что исходящее сообщение может быть
явно буферизовано в предоставленном пользователю пространстве, превышая
таким образом возможности системной политики буферизации. Наконец, доступность
операций pack и unpack облегчает развитие дополнительных
коммуникационных библиотек, расположенных на верхнем уровне MPI.
Синтаксис функции MPI_PACK представлен ниже.
MPI_PACK(inbuf, incount, datatype, outbuf, outsize, position, comm)
| IN | inbuf | начало входного буфера (альтернатива) | |
| IN | incount | число единиц входных данных (целое) | |
| IN | datatype | тип данных каждой входной единицы (дескриптор) | |
| OUT | outbuf | начало выходного буфера (альтернатива) | |
| IN | outsize | размер выходного буфера в байтах (целое) | |
| INOUT | position | текущая позиция в буфере в байтах (целое) | |
| IN | comm | коммуникатор для упакованного сообщения (дескриптор) |
int MPI_Pack(void* inbuf, int incount, MPI_Datatype datatype,
void *outbuf, int outsize, int *position, MPI_Comm comm)
MPI_PACK(INBUF, INCOUNT, DATATYPE, OUTBUF, OUTSIZE, POSITION, COMM, IERROR)
<type> INBUF(*), OUTBUF(*)
INTEGER INCOUNT, DATATYPE, OUTSIZE, POSITION, COMM, IERROR
void MPI::Datatype::Pack (const void* inbuf, int incount, void *outbuf,
int outsize, int& position, const MPI::Comm &comm) const
Операция MPI_PACK пакует сообщение в буфер посылки, описанный
аргументами inbuf,
incount, datatype в буферном пространстве,
описанном аргументами outbuf и outsize. Входным буфером
может быть любой коммуникационный буфер, разрешенный в MPI_SEND.
Выходной буфер есть смежная область памяти, содержащая outsize байтов,
начиная с адреса outbuf (длина подсчитывается в байтах, а не в
элементах, как если бы это был коммуникационный буфер для сообщения типа
MPI_PACKED).
Входное значение position есть первая ячейка в выходном буфере, которая должна быть использована для упаковки. рosition инкрементируется размером упакованного сообщения и выходное значение рosition есть первая ячейка в выходном буфере, следующая за ячейками, занятыми упакованным сообщением. Аргумент comm есть коммуникатор, который будет использован для передачи упакованного сообщения.
Синтаксис функции MPI_UNPACK представлен ниже.
MPI_UNPACK(inbuf, insize, position, outbuf, outcount, datatype, comm)
| IN | inbuf | начало входного буфера (альтернатива) | |
| IN | insize | размер входного буфера в байтах (целое) | |
| INOUT | position | текущая позиция в байтах (целое) | |
| OUT | outbuf | начало выходного буфера (альтернатива) | |
| IN | outcount | число единиц для распаковки (целое) | |
| IN | datatype | тип данных каждой выходной единицы данных (дескриптор) | |
| IN | comm | коммуникатор для упакованных сообщений (дескриптор) |
int MPI_Unpack(void* inbuf, int insize, int *position,
void *outbuf, int outcount, MPI_Datatype datatype, MPI_Comm comm)
MPI_UNPACK(INBUF, INSIZE, POSITION, OUTBUF, OUTCOUNT, DATATYPE, COMM, IERROR)
<type> INBUF(*), OUTBUF(*)
INTEGER INSIZE, POSITION, OUTCOUNT, DATATYPE, COMM, IERROR
void MPI::Datatype::Unpack(const void* inbuf, int insize,
void *outbuf, int outcount, int& position, const MPI::Comm& comm) const
Функция MPI_UNPACK распаковывает сообщение в приемный буфер, описанный аргументами outbuf, outcount, datatype из буферного пространства, описанного аргументами inbuf и insize. Выходным буфером может быть любой коммуникационный буфер, разрешенный в MPI_RECV. Входной буфер есть смежная область памяти, содержащая insize байтов, начиная с адреса inbuf. Входное значение position есть первая ячейка во входном буфере, занятом упакованным сообщением. рosition инкрементируется размером упакованного сообщения, так что выходное значение рosition есть первая ячейка во входном буфере после ячеек, занятых сообщением, которое было упаковано. сomm есть коммуникатор для приема упакованного сообщения.
Совет пользователям: Укажем на разницу между MPI_RECV и MPI_UNPACK: в MPI_RECV аргумент count описывает максимальное число единиц, которое может быть получено. Действительное же число определяется длиной входного сообщения. В MPI_UNPACK аргумент count описывает действительное число единиц, которые распакованы; ``размер'' соответствующего сообщения инкрементируется в position. Причина для этого изменения состоит в том, что ``размер входного сообщения'' не предопределен, поскольку пользователь решает, сколько распаковывать; да и нелегко определить ``размер сообщения'' по числу распакованных единиц. Фактически в неоднородной системе это число не может быть определено априори.[]
Чтобы понять поведение pack и unpack, удобно предположить, что часть данных сообщения есть последовательность, полученная конкатенацией последующих значений, посланных в сообщении. Операция pack сохраняет эту последовательность в буферном пространстве, как при посылке сообщения в этот буфер. Операция unpack обрабатывает последовательность из буферного пространства, как при приеме сообщения из этого буфера. (Полезно вспомнить о внутренних файлах языка ФОРТРАН или о sscanf в языке Си для подобной функции).
Несколько сообщений могут быть последовательно упакованы в один упакованный объект (packing unit). Это достигается несколькими последовательными связанными обращениями к MPI_PACK, где первый вызов обеспечивает position = 0, и каждый последующий вызов вводит значение position, которое было выходом для предыдущего вызова, и то же самое значение для outbuf, outcount и comm. Этот упакованный объект теперь содержит эквивалентную информацию, которая хранилась бы в сообщении по одной передаче с буфером передачи, который является ``конкатенацией'' индивидуальных буферов передачи.
Упакованный объект может быть послан операцией MPI_PACKED. Любая парная или коллективная коммуникационная функция может быть использована для передачи последовательности байтов, которая формирует упакованный объект, из одного процесса в другой. Этот упакованный объект также может быть получен любой приемной операцией: типовые правила соответствия ослаблены для сообщений, посланных с помощью MPI_PACKED.
Сообщение, посланное с любым типом (включая MPI_PACKED) могут быть получены с помощью MPI_PACKED. Такое сообщение может быть распаковано обращением к MPI_UNPACK.
Упакованный объект (или сообщение, созданное обычной ``типовой'' передачей) может быть распаковано в несколько последовательных сообщений. Это достигается несколькими последовательными обращениями к MPI_UNPACK, где первое обращение обеспечивает position = 0 и каждый последовательный вызов вводит значение position, которое было выходом предыдущего обращения, и то же самое значение для inbuf, insize и comm.
Конкатенация двух упакованных объектов не обязательно является упакованным объектом; подстрока упакованного объекта также не обязательно есть упакованный объект. Поэтому нельзя ни производить конкатенацию двух упакованных объектов и затем распаковывать результат как один упакованный объект; ни распаковывать подстроку упакованного объекта, как отдельный упакованный объект. Каждый упакованный объкт, который был создан соответствующей последовательностью операций упаковки или обычными send, обязан быть распакован как объект последовательностью связанных распаковывающих обращений.
Объяснение: Ограничение на ``атомарную'' (``atomic'') упаковку и распаковку упакованных объектов позволяет реализации добавлять в заголовок упакованных объектов дополнительную информацию, такую, как описание архитектуры отправителя (используется для преобразования типов в неоднородной среде).[]
Следующий вызов позволяет пользователю выяснить, сколько пространства нужно для упаковки объекта, что позволяет управлять распределением буферов.
Синтаксис функции MPI_PACK_SIZE представлен ниже.
MPI_PACK_SIZE(incount, datatype, comm, size)
| IN | incount | аргумент count для упакованного вызова (целое) | |
| IN | datatype | аргумент datatype для упакованного вызова (дескриптор) | |
| IN | comm | аргумент communicator для упакованного вызова (дескриптор) | |
| OUT | size | верхняя граница упакованного сообщения в байтах (целое) |
int MPI_Pack_size(int incount, MPI_Datatype datatype, MPI_Comm comm, int *size) MPI_PACK_SIZE(INCOUNT, DATATYPE, COMM, SIZE, IERROR) INTEGER INCOUNT, DATATYPE, COMM, SIZE, IERROR int MPI::Datatype::Pack_size(int incount, const MPI::Comm& comm) const
Обращение к MPI_PACK_SIZE(incount, datatype, comm, size) возвращает в size верхнюю границу по инкременту в position, которая создана обращением к MPI_PACK(inbuf, incount, datatype, outbuf, outcount, position, comm).
Объяснение: Вызов возвращает верхнюю границу, а не точную границу, поскольку точный объем пространства, необходимый для упаковки сообщения, может зависеть от контекста (например, первое сообщение, упакованное в упакованный объект, может занимать больше объема).[]
Пример 3.38 Пример использования MPI_PACK.
int position, i, j, a[2];
char buff[1000];
...
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
if (myrank == 0)
{
/ * код отправителя */
position = 0;
MPI_Pack(&i, 1, MPI_INT, buff, 1000, &position, MPI_COMM_WORLD);
MPI_Pack(&j, 1, MPI_INT, buff, 1000, &position, MPI_COMM_WORLD);
MPI_Send(buff, position, MPI_PACKED, 1, 0, MPI_COMM_WORLD);
}
else /* код получателя */
MPI_Recv(a, 2, MPI_INT, 0, 0, MPI_COMM_WORLD)
}
Пример 3.39 Усложненный пример.
int position, i;
float a[1000];
char buff[1000]
...
MPI_Comm_rank(MPI_Comm_world, &myrank);
if (myrank == 0)
{
/ * код отправителя */
int len[2];
MPI_Aint disp[2];
MPI_Datatype type[2], newtype;
/* построение типа данных для i с последующими a[0]...a[i-1] */
len[0] = 1;
len[1] = i;
MPI_Address(&i, disp);
MPI_Address(a, disp+1);
type[0] = MPI_INT;
type[1] = MPI_FLOAT;
MPI_Type_struct(2, len, disp, type, &newtype);
MPI_Type_commit(&newtype);
/* упаковка i с последующими a[0]...a[i-1]*/
position = 0;
MPI_Pack(MPI_BOTTOM, 1, newtype, buff, 1000, &position, MPI_COMM_WORLD);
/* посылка */
MPI_Send(buff, position, MPI_PACKED, 1, 0,
MPI_COMM_WORLD)
/* *****
можно заменить последние три строки
MPI_Send(MPI_BOTTOM, 1, newtype, 1, 0, MPI_COMM_WORLD);
***** */
}
else /* myrank == 1 */
{
/* код получателя */
MPI_Status status;
/* прием */
MPI_Recv(buff, 1000, MPI_PACKED, 0, 0, &status);
/* распаковка i */
position = 0;
MPI_Unpack(buff, 1000, &position, &i, 1, MPI_INT, MPI_COMM_WORLD);
/* распаковка a[0]...a[i-1] */
MPI_Unpack(buff, 1000, &position, a, i, MPI_FLOAT, MPI_COMM_WORLD);
}
Пример 3.40 Каждый процесс посылает число, прибавляя знаки числа к корню, корень производит конкатенацию всех знаков в одну строку.
int count, gsize, counts[64], totalcount, k1, k2, k,
displs[64], position, concat_pos;
char chr[100], *lbuf, *rbuf, *cbuf;
...
MPI_Comm_size(comm, &gsize);
MPI_Comm_rank(comm, &myrank);
/* создать локальный буфер для упаковки */
MPI_Pack_size(1, MPI_INT, comm, &k1);
MPI_Pack_size(count, MPI_CHAR, comm, &k2);
k = k1+k2;
lbuf = (char *)malloc(k);
/* упаковать count, */
position = 0;
MPI_Pack(&count, 1, MPI_INT, lbuf, k, &position, comm);
MPI_Pack(chr, count, MPI_CHAR, lbuf, k, &position, comm);
if (myrank != root)
/* собрать на корневом процессе размеры всех упакованных сообще-ний */
MPI_Gather(&position, 1, MPI_INT, NULL, NULL,
NULL, root, comm);
/* собрать на корневом процессе упакованные сообщения */
MPI_Gatherv(&buf, position, MPI_PACKED, NULL,
NULL, NULL, NULL, root, comm);
else { /* код корневого процесса */
/* собрать размеры всех упакованных сообщений */
MPI_Gather(&position, 1, MPI_INT, counts, 1,
MPI_INT, root, comm);
/* собрать все упакованные сообщения */
displs[0] = 0;
for (i=1; i < gsize; i++)
displs[i] = displs[i-1] + counts[i-1];
totalcount = dipls[gsize-1] + counts[gsize-1];
rbuf = (char *)malloc(totalcount);
cbuf = (char *)malloc(totalcount);
MPI_Gatherv(lbuf, position, MPI_PACKED, rbuf,
counts, displs, MPI_PACKED, root, comm);
/* распаковать все сообщения и соединить строки */
concat_pos = 0;
for (i=0; i < gsize; i++) {
position = 0;
MPI_Unpack(rbuf+displs[i], totalcount-displs[i],
&position, &count, 1, MPI_INT, comm);
MPI_Unpack(rbuf+displs[i], totalcount-displs[i],
&position, cbuf+concat_pos, count, MPI_CHAR, comm);
concat_pos += count;
}
cbuf[concat_pos] = `\0';
}
К операциям коллективного обмена относятся:
рис. 4.1)
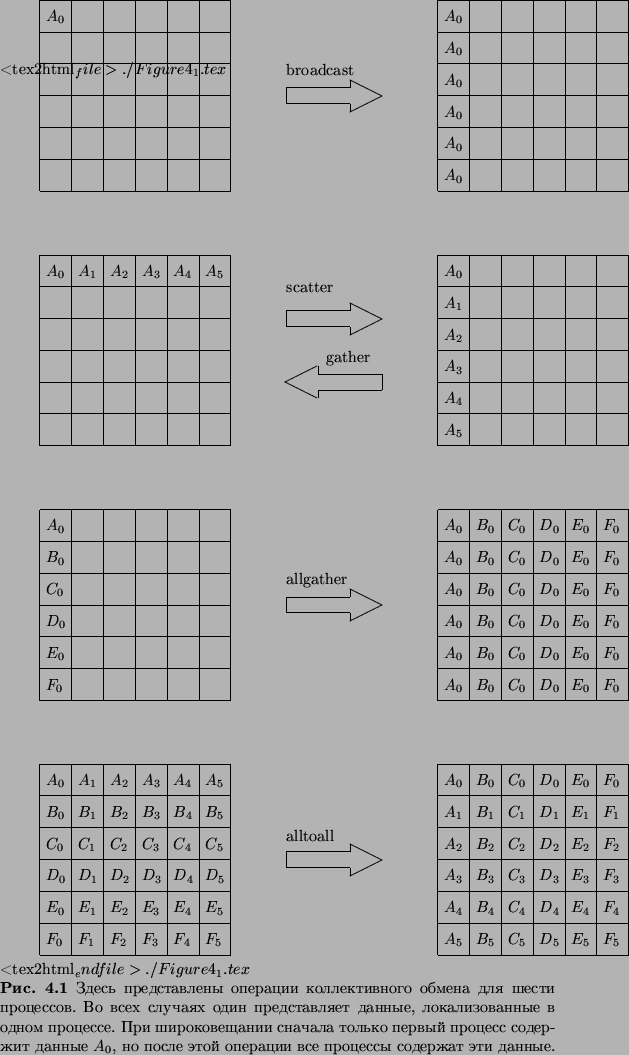
Коллективная операция исполняется путем вызова всеми процессами в группе коммуникационных функций с соответствующими аргументами. Синтаксис и семантика коллективных операций определяются далее подобно синтаксису и семантике операций парного обмена между процессами. Это в частности означает, что в коллективных операциях используются основные типы данных и они должны должны совпадать у процесса-отправителя и процесса-получателя, как определено в главе 3. Один из ключевых аргументов - это коммуникатор, который определяет группу участвующих в обмене процессов и обеспечивает контекст для этой операции.
Различные коллективные операции, такие как широковещание и сбор данных, имеют единственный процесс-отправитель или процесс-получатель. Такие процессы называются корневыми (root). Некоторые аргументы в коллективных функциях определены как ``существенные только для корневого процесса'' и игнорируются для всех других участников операции.
Информация относительно буферов обмена, основных типов данных и правил приведения типов представлена в главе 3, а информация о группах и коммуникаторах - в главе 5.
Условия соответствия типов для коллективных операций более строгие, чем аналогичные условия для парного обмена. А именно, для коллективных операций количество посланных данных должно точно соответствовать количеству данных, описанных в процессе-получателе.
Однако, допускается различие в картах типов данных у процесса-отправителя и процесса-получателя (раздел 3.12).
Вызов коллективной функции может (но это не требуется) возвращать управление сразу, как только его участие в коллективной операции завершено. Завершение вызова показывает, что процесс-отправитель уже может обращаться к буферу обмена. Это однако не означает, что другие процессы в группе завершили операцию. Таким образом, вызов операции коллективного обмена может иметь (а может и не иметь) эффект синхронизации всех процессов в группе. Это утверждение, конечно, не относится к барьерной функции.
Вызовы коллективных операций могут использовать те же коммуникаторы, что и парный обмен, при этом MPI гарантирует, что сообщения, созданные коллективными операциями, не будут смешаны с сообщениями, созданными парным обменом. Более детальное обсуждение корректного использования коллективных операций имеется в разделе 4.12.
Объяснение: Ограничение на количество данных (совпадающих по типу) было сделано с целью избежать осложнений при обеспечении возможности определения количества посланных данных, аналогичной для статусного аргумента в MPI_RECV. Некоторые коллективные функции могут использовать массив статусных величин.
Утверждения о синхронизации сделаны так, чтобы позволить различные реализации коллективных функций.
Коллективные операции не поддерживают аргумент тэга. Если в будущих версиях MPI будут определены неблокирующие коллективные функции, то, чтобы добиться четкости в выполнении коллективных операций, нужно будет добавить тэги.[]
Совет пользователям: С точки зрения корректности программы не следует рассчитывать на побочный эффект синхронизации, который свойственен коллективным операциям. Например, частная реализация может создать функцию широковещания с побочным эффектом синхронизации, но стандарт этого не требует, и программа, полагающаяся на это, не будет переносимой.
С другой стороны, корректная переносимая программа должна учитывать факт, что коллективная операция может быть синхронизирована. Нельзя полагаться на этот побочный эффект синхронизации, но необходимо учитывать, что он может иметь место. Это обсуждается в разделе 4.12.[]
Совет разработчикам: Пока поставщики будут создавать оптимизированные для их архитектур процедуры коллективных операций, можно написать завершенную библиотеку функций коллективного обмена, используя коммуникационные функции парного обмена MPI и несколько дополнительных функций. Чтобы реализовать такую библиотеку на основе парного обмена, нужно создать специальные скрытые коммуникаторы для коллективных операций, чтобы избежать пересечения с каким-либо другим явным парным обменом во время вызова коллективной операции. Это обсуждается далее в разделе 4.12.[]
Этот стандарт предназначен для пользователей, которые хотят писать мобильные программы для передачи сообщений на языках ФОРТРАН77 и Си. К ним относятся прикладные программисты, разработчики программного обеспечения для параллельных машин и создатели исполнительных сред, реализующих MPI. Чтобы быть привлекательным для этой широкой аудитории, стандарт обязан обеспечивать простой, легкий в использовании интерфейс для основного пользователя, в то же время семантически не мешая высокоэффективным операциям передачи сообщений, доступным на перспективных машинах.
Синтаксис функции MPI_BARRIER приводится ниже.
MPI_BARRIER(comm)
| IN | comm | коммуникатор(дескриптор) |
int MPI_Barrier(MPI_Comm comm)
MPI_BARRIER(COMM, IERROR)
INTEGER COMM, IERROR
void MPI::Intracomm::Barrier() const
Функция барьерной синхронизации MPI_BARRIER блокирует вызывающий процесс, пока все процессы группы не вызовут её. В каждом процессе управление возвращается только тогда, когда все процессы в группе вызовут процедуру.
Синтаксис функции широковещательной посылки данных MPI_BCAST приводится ниже.
MPI_BCAST(buffer, count, datatype, root, comm)
| INOUT | buffer | адрес начала буфера (альтернатива) | |
| IN | count | количество записей в буфере (целое) | |
| IN | datatype | тип данных в буфере (дескриптор) | |
| IN | root | номер корневого процесса (целое) | |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Bcast(void* buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm)
MPI_BCAST(BUFFER, COUNT, DATATYPE, ROOT, COMM, IERROR)
<type> BUFFER(*)
INTEGER COUNT, DATATYPE, ROOT, COMM,
IERROR
void MPI::Intracomm::Bcast(void* buffer, int count,
const Datatype& datatype, int root) const
Функция широковещательной передачи MPI_BCAST посылает сообщение из корневого процесса всем процессам группы, включая себя. Она вызывается всеми процессами группы с одинаковыми аргументами для comm и root. В момент возврата управления содержимое корневого буфера обмена будет уже скопировано во все процессы.
В аргументе datatype можно задавать производные типы данных. Сигнатура типа данных count, datatype любого процесса обязана совпадать с соответствующей сигнатурой в корневом процессе. Необходимо, чтобы количество посланных и полученных данных совпадало попарно для корневого и каждого другого процессов. Такое ограничение имеют и все остальные коллективные операции, выполняющие перемещение данных. Однако по-прежнему разрешается различие в картах типов данных между отправителями и получателями.
Пример 4.1. Широковещательная передача 100 целых чисел от процесса 0 каждому процессу в группе.
MPI_Comm comm; int array[100]; int root = 0; ... MPI_Bcast(array, 100, MPI_INT, root, comm);
Как и в большинстве примеров дальше предполагается, что некоторым переменным (таким, как comm выше) уже было присвоено соответствующее значение.
Синтаксис функции сборки данных MPI_GATHER приводится ниже.
MPI_GATHER(sendbuf,sendcount, sendtype, recvbuf, recvcount, recvtype, root, comm)
| IN | sendbuf | начальный адрес буфера процесса-отправителя (альтернатива) | |
| IN | sendcount | количество элементов в отсылаемом сообщении (целое) | |
| IN | sendtype | тип элементов в отсылаемом сообщении (дескриптор) | |
| OUT | recvbuf | начальный адрес буфера процесса сборки данных (альтернатива, существенно только для корневого процесса) | |
| IN | recvcount | количество элементов в принимаемом сообщении (целое, имеет значение только для корневого процесса) | |
| IN | recvtype | тип данных элементов в буфере процесса-получателя (дескриптор) | |
| IN | root | номер процесса-получателя (целое) | |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Gather(void* sendbuf, int sendcount,
MPI_Datatype sendtype, void* recvbuf, int recvcount,
MPI_Datatype recvtype, int root, MPI_Comm comm)
MPI_GATHER(SENDBUF, SENDCOUNT,
SENDTYPE, RECVBUF, RECVCOUNT,
RECVTYPE,
ROOT, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNT,
SENDTYPE, RECVCOUNT, RECVTYPE, ROOT, COMM, IERROR
void MPI::Intracomm::Gather(const void* sendbuf, int sendcount,
const Datatype& sendtype, void* recvbuf, int recvcount,
const Datatype& recvtype, int root) const
При выполнении операции сборки данных MPI_GATHER каждый процесс, включая корневой, посылает содержимое своего буфера в корневой процесс. Корневой процесс получает сообщения, располагая их в порядке возрастания номеров процессов. Результат будет такой же, как если бы каждый из n процессов группы (включая корневой процесс) выполнил вызов
MPI_Send(sendbuf, sendcount, sendtype, root, ...),
и корневой процесс выполнил n вызовов
MPI_Recv(recvbuf + i * recvcount * extent(recvtype), recvcount, recvtype, i,
...),
где extent (recvtype) - размер типа данных, получаемый с помощью
MPI_Type_extent().
В общем случае как для sendtype, так и для recvtype разрешены производные типы данных. Сигнатура типа данных sendcount, sendtype у процесса i должна быть такой же, как сигнатура recvcount, recvtype корневого процессе. Это требует, чтобы количество посланных и полученных данных совпадало попарно для корневого и каждого другого процессов. Однако по-прежнему разрешается различие в картах типов между отправителями и получателями.
В корневом процессе используются все аргументы функции, в то время как у остальных процессов используются только аргументы sendbuf, sendcount, sendtype, root, comm. Аргументы comm и root должны иметь одинаковые значения во всех процессах.
Описанные в функции MPI_GATHER количества и типы данных не должны являться причиной того, чтобы любая ячейка корневого процесса записывалось бы более одного раза. Такой вызов является неверным.
Отметим, что аргумент recvcount в главном процессе показывает количество элементов, которые он получил от каждого процесса, а не общее количество полученных элементов.
Ниже приводится синтаксис функции MPI_GATHERV, обеспечивающей переменное число посылаемых данных.
MPI_GATHERV(sendbuf,sendcount, sendtype, recvbuf,
recvcounts, displs, recvtype, root, comm)
| IN | sendbuf | начальный адрес буфера процесса-отправителя (альтернатива) | |
| IN | sendcount | количество элементов в отсылаемом сообщении (целое) | |
| IN | sendtype | тип элементов в отсылаемом сообщении (дескриптор) | |
| OUT | recvbuf | начальный адрес буфера процесса сборки данных (альтернатива, существенно только для корневого процесса) | |
| IN | recvcounts | массив целых чисел (по размеру группы), содержащий количества элементов, которые получены от каждого из процессов (используется только корневым процессом) | |
| IN | displs | массив целых чисел (по размеру группы). Элемент i определяет смещение относительно recvbuf, в котором размещаются данные из процесса i (используется только корневым процессом) | |
| IN | recvtype | тип данных элементов в буфере процесса-получателя (дескриптор) | |
| IN | root | номер процесса-получателя (целое) | |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Gatherv(void* sendbuf, int sendcount, MPI_Datatype sendtype,
void* recvbuf, int *recvcounts, int *displs, MPI_Datatype recvtype,
int root, MPI_Comm comm)
MPI_GATHERV(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF,
RECVCOUNTS, DISPLS, RECVTYPE, ROOT, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNT, SENDTYPE,
RECVCOUNTS(*), DISPLS(*), RECVTYPE, ROOT, COMM, IERROR
void MPI::Intracomm::Gatherv(const void* sendbuf, int sendcount,
const Datatype& sendtype, void* recvbuf, const int recvcounts[],
const int displs[], const Datatype& recvtype, int root) const
По сравнению с MPI_GATHER при использовании функции MPI_GATHERV разрешается принимать от каждого процесса переменное число элементов данных, поэтому в функции MPI_GATHERV аргумент recvcount является массивом. Она также обеспечивает большую гибкость в размещении данных в корневом процессе. Для этой цели используется новый аргумент displs.
Выполнение MPI_GATHERV будет давать такой же результат, как если бы каждый процесс, включая корневой, послал бы корневому процессу сообщение
MPI_Send(sendbuf, sendcount, sendtype, root, ...),и корневой процесс выполнил бы n операций приема
MPI_Recv(recvbuf + displs[i] * extern(recvtype), recvcounts[i], recvtype, i, ...).
Сообщения помещаются в принимающий буфер корневого процесса в порядке возрастания их номеров, то есть данные, посланные процессом j помещаются в j-ю часть принимающего буфера recvbuf на корневом процессе. j-я часть recvbuf начинается со смещения displs[j]. Номер принимающего буфера игнорируется во всех некорневых процессах.
Сигнатура типа, используемая sendcount, sendtype в процессе i должна быть такой же, как и сигнатура, используемая recvcounts[i], recvtype в корневом процессе. Необходимо, чтобы количество посланных и полученных данных совпадало попарно для корневого и каждого другого процессов. Однако по-прежнему разрешается различие в картах типов между отправителями и получателями, как показано в примере 4.6.
В корневом процессе используются все аргументы функции
MPI_GATHERV, а на всех других процессах используются только
аргументы sendbuf, sendcount, sendtype, root, comm .
Переменные comm и root должны иметь одинаковые значения во всех
процессах.
Описанные в функции MPI_GATHERV количества, типы данных и смещения не должны приводить к тому, чтобы любая область корневого процесса записывалась бы более одного раза. Такой вызов является неверным.
Пример 4.2 Сбор 100 целых чисел с каждого процесса группы в корневой процесс (рис. 4.2).
MPI_Comm comm;
int gsize, sendarray[100];
int root, *rbuf;
...
MPI_Comm_size(comm, &gsize);
rbuf = (int *)malloc(gsize*100*sizeof(int));
MPI_Gather(sendarray, 100, MPI_INT, rbuf, 100, MPI_INT, root, comm);
Пример 4.3 Предыдущий пример модифицирован - только корневой процесс выделяет память для буфера приема.
MPI_Comm comm;
int gsize,sendarray[100];
int root, myrank, *rbuf;
...
MPI_Comm_rank(comm, myrank);
if (myrank == root) {
MPI_Comm_size(comm, &gsize);
rbuf = (int *)malloc(gsize*100*sizeof(int));
}
MPI_Gather(sendarray, 100, MPI_INT, rbuf, 100, MPI_INT, root, comm);
Пример 4.4. Программа делает то же, что и в предыдущем примере, но использует производные типы данных. Отметим, что тип не может быть полным множеством gsize*100 чисел типа int, поскольку соответствующие типы определены попарно между каждым процессом, участвующим в сборе данных, и корневым процессом.
MPI_Comm comm;
int gsize,sendarray[100];
int root, *rbuf;
MPI_Datatype rtype;
...
MPI_Comm_size(comm, &gsize);
MPI_Type_contiguous(100, MPI_INT, &rtype);
MPI_Type_commit(&rtype);
rbuf = (int *)malloc(gsize*100*sizeof(int));
MPI_Gather(sendarray, 100, MPI_INT, rbuf, 1, rtype, root, comm);
Пример 4.5 Здесь каждый процесс посылает 100 чисел типа int корневому процессу, но каждое множество (100 элементов) размещается с некоторым шагом (stride) относительно конца размещения предыдущего множества. Чтобы получить этот эффект нужно использовать MPI_GATHERV и аргумент displs. Полагаем, что stride > 100 (рис. 4.3).
MPI_Comm comm;
int gsize,sendarray[100];
int root, *rbuf, stride;
int *displs,i,*rcounts;
...
MPI_Comm_size(comm, &gsize);
rbuf = (int *)malloc(gsize*stride*sizeof(int));
displs = (int *)malloc(gsize*sizeof(int));
rcounts = (int *)malloc(gsize*sizeof(int));
for (i=0; i<gsize; ++i) {
displs[i] = i*stride;
rcounts[i] = 100;
}
MPI_Gatherv(sendarray, 100, MPI_INT, rbuf, rcounts, displs,
MPI_INT, root, comm);
Отметим, что программа неверна, если stride < 100.
![\includegraphics[width=5.77in,height=2.82in]{Ch4figure3.eps}](img23.png)
Пример 4.6. Со стороны процесса-получателя пример такой же, как и 4.5, но посылается 100 чисел типа int из 0-го столбца C-массива 100x150 чисел типа int (рис. 4.4).
MPI_Comm comm;
int gsize,sendarray[100][150];
int root, *rbuf, stride;
MPI_Datatype stype;
int *displs,i,*rcounts;
...
MPI_Comm_size(comm, &gsize);
rbuf = (int *)malloc(gsize*stride*sizeof(int));
displs = (int *)malloc(gsize*sizeof(int));
rcounts = (int *)malloc(gsize*sizeof(int));
for (i=0; i<gsize; ++i) {
displs[i] = i*stride;
rcounts[i] = 100;
}
/* Create datatype for 1 column of array
*/
MPI_Type_vector(100, 1, 150, MPI\_INT, &stype);
MPI_Type_commit(&stype);
MPI_Gatherv(sendarray, 1, stype, rbuf, rcounts, displs, MPI_INT, root,
comm);
![\includegraphics[width=5.83in,height=2.99in]{Ch4figure4.eps}](img24.png)
Пример 4.7 Процесс i посылает (100-i) чисел типа int из i-ого столбца C - массива 100x150 чисел типа int на языке Си (рис.4.5)
MPI_Comm comm;
int gsize,sendarray[100][150],*sptr;
int root, *rbuf, stride, myrank;
MPI_Datatype stype;
int *displs,i,*rcounts;
...
MPI_Comm_size(comm, &gsize);
MPI_Comm_rank(comm, &myrank);
rbuf = (int *)malloc(gsize*stride*sizeof(int));
displs = (int *)malloc(gsize*sizeof(int));
rcounts = (int *)malloc(gsize*sizeof(int));
for (i=0; i<gsize; ++i) {
displs[i] = i*stride;
rcounts[i] = 100-i; /* отличие от предыдущего примера */
}
/* создается тип данных для посылаемого столбца */
MPI_Type_vector(100-myrank, 1, 150, MPI_INT, &stype);
MPI_Type_commit(&stype);
/* sptr есть адрес начала столбца "myrank"
*/
sptr = &sendarray[0][myrank];
MPI_Gatherv(sptr, 1, stype, rbuf, rcounts, displs, MPI_INT,
root, comm);
Отметим, что из каждого процесса получено различное количество данных.
![\includegraphics[width=5.33in,height=2.84in]{Ch4figure5.eps}](img25.png)
Пример 4.8. Пример такой же, как и 4.7, но содержит отличие на передающей стороне. Создается тип данных с корректным страйдом на передающей стороне для чтения столбца массива на языке Си. Подобная вещь была сделана в примере 3.33, раздел 3.12.7.
MPI_Comm comm;
int gsize, sendarray[100][150], *sptr;
int root, *rbuf, stride, myrank, disp[2], blocklen[2];
MPI_Datatype stype,type[2];
int *displs,i,*rcounts;
...
MPI_Comm_size(comm, &gsize);
MPI_Comm_rank(comm, &myrank);
rbuf = (int *)malloc(gsize*stride*sizeof(int));
displs = (int *)malloc(gsize*sizeof(int));
rcounts = (int *)malloc(gsize*sizeof(int));
for (i=0; i<gsize; ++i) {
displs[i] = i*stride;
rcounts[i] = 100-i;
}
/* создается тип данных для одного числа типа int с расширением на
полню строку
*/
disp[0] = 0; disp[1] = 150*sizeof(int);
type[0] = MPI_INT; type[1] = MPI_UB;
blocklen[0] = 1; blocklen[1] = 1;
MPI_Type_struct(2, blocklen, disp, type, &stype);
MPI_Type_commit(&stype);
sptr = &sendarray[0][myrank];
MPI_Gatherv(sptr, 100-myrank, stype, rbuf, rcounts, displs,
MPI_INT, root, comm);
Пример 4.9 Такой же, как пример 4.7 на передающей стороне, но на приемной стороне устанавливается страйд между принимаемыми блоками, изменяющийся от блока к блоку (рис.4.6).
MPI_Comm comm;
int gsize,sendarray[100][150],*sptr;
int root, *rbuf, *stride, myrank, bufsize;
MPI_Datatype stype;
int *displs,i,*rcounts,offset;
...
MPI_Comm_size(comm, &gsize);
MPI_Comm_rank(comm, &myrank);
stride = (int *)malloc(gsize*sizeof(int));
...
/* сначала устанавливаются вектора displs и rcounts
*/
displs = (int *)malloc(gsize*sizeof(int));
rcounts = (int *)malloc(gsize*sizeof(int));
offset = 0;
for (i=0; i<gsize; ++i) {
displs[i] = offset;
offset += stride[i];
rcounts[i] = 100-i;
}
/* теперь легко получается требуемый размер буфера для rbuf
*/
bufsize = displs[gsize-1]+rcounts[gsize-1];
rbuf = (int *)malloc(bufsize*sizeof(int));
/* создается тип данных для посылаемого столбца
*/
MPI_Type_vector(100-myrank, 1, 150, MPI_INT, &stype);
MPI_Type_commit(&stype);
sptr = &sendarray[0][myrank];
MPI_Gatherv(sptr, 1, stype, rbuf, rcounts, displs, MPI_INT, root, comm);
![\includegraphics[width=5.77in,height=2.82in]{Ch4figure7.eps}](img26.png)
Пример 4.10 В этом примере процесс i посылает num чисел типа int из i-го столбца массива 100x150 чисел типа int на языке Си. Усложнение состоит в том, что различные значения num неизвестны корневому процессу, так что требуется сначала выполнить отдельную операцию gather, чтобы найти их. Данные на приемной стороне размещаются непрерывно.
MPI_Comm comm;
int gsize,sendarray[100][150],*sptr;
int root, *rbuf, stride, myrank, disp[2], blocklen[2];
MPI_Datatype stype,types[2];
int *displs,i,*rcounts,num;
...
MPI_Comm_size(comm, &gsize);
MPI_Comm_rank(comm, &myrank);
/* снчала собираются nums для root
*/
rcounts = (int *)malloc(gsize*sizeof(int));
MPI_Gather(&num, 1, MPI_INT, rcounts, 1, MPI_INT, root, comm);
/* root теперь имеет правильные rcounts, это позволяет установить
displs[] так, чтобы данные на приемной стороне размещались
непрерывно (или на основе конкатенации)
*/
displs = (int *)malloc(gsize*sizeof(int));
displs[0] = 0;
for (i=1; i<gsize; ++i) {
displs[i] = displs[i-1]+rcounts[i-1];
}
/* создается буфер получения
*/
rbuf = (int *)malloc(gsize*(displs[gsize-1]+rcounts[gsize-1])
*sizeof(int));
/* создается тип данных для единственной int с расширением на полную
строку
*/
disp[0] = 0; disp[1] = 150*sizeof(int);
type[0] = MPI_INT; type[1] = MPI_UB;
blocklen[0] = 1; blocklen[1] = 1;
MPI_Type_struct(2, blocklen, disp, type, &stype);
MPI_Type_commit(&stype);
sptr = &sendarray[0][myrank];
MPI_Gatherv(sptr, num, stype, rbuf, rcounts, displs, MPI_INT,
root, comm);
Синтаксис функции рассылки MPI_SCATTER представлен ниже.
MPI_SCATTER(sendbuf, sendcount, sendtype, recvbuf, recvcount, recvtype, root, comm)
| IN | sendbuf | начальный адрес буфера рассылки (альтернатива, используется только корневым процессом) | |
| IN | sendcount | количество элементов, посылаемых каждому процессу (целое, используется только корневым процессом) | |
| IN | sendtype | тип данных элементов в буфере посылки (дескриптор, используется только корневым процессом) | |
| OUT | recvbuf | адрес буфера процесса-получателя (альтернатива) | |
| IN | recvcount | количество элементов в буфере корневого (целое) | |
| IN | recvtype | тип данных элементов приемного буфера (дескриптор) | |
| IN | root | номер процесса-получателя (целое) | |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Scatter(void* sendbuf, int sendcount, MPI_Datatype sendtype,
void* recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm)
MPI_SCATTER(SENDBUF, SENDCOUNT,
SENDTYPE, RECVBUF, RECVCOUNT,
RECVTYPE, ROOT,
COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*) INTEGER SENDCOUNT, SENDTYPE,
RECVCOUNT,
RECVTYPE, ROOT, COMM, IERROR
void MPI::Intracomm::Scatter(const void* sendbuf, int sendcount,
const Datatype& sendtype, void* recvbuf, int recvcount,
const Datatype& recvtype, int root) const
Операция MPI_SCATTER обратна операции MPI_GATHER. Результат ее выполнения таков, как если бы корневой процесс выполнил n операций посылки
MPI_Send(senbuf + i * extent(sendtype), sendcount, sendtype, i,...),и каждый процесс выполнит приём
MPI_Recv(recvbuf, recvcount, recvtype, i,...)
Буфер отправки игнорируется всеми некорневыми процессами.
Сигнатура типа, связанная с sendcount, sendtype, должна быть одинаковой для корневого процесса и всех других процессов (хотя карты типов могут быть разными). Необходимо, чтобы количество посланных и полученных данных совпадало попарно для корневого и каждого другого процессов. Однако по-прежнему разрешается различие в картах типов между отправителями и получателями.
Корневой процесс использует все аргументы функции, а другие процессы
используют только аргументы recvbuf, recvcount, recvtype, root, comm.
Аргументы root и comm должны быть одинаковыми во всех процессах.
Описанные в функции MPI_SCATTER количества и типы данных не должны являться причиной того, чтобы любая ячейка корневого процесса записывалось бы более одного раза. Такой вызов является неверным.
Объяснение: Последнее ограничение введено (хотя это не вызывается необходимостью), чтобы достигнуть симметрии с MPI_GATHER, где соответствующее ограничение требуется.[]
Синтаксис функции рассылки MPI_SCATTERV представлен ниже.
MPI_SCATTERV(sendbuf,
sendcounts, displs, sendtype, recvbuf, recvcount, recvtype,
root,
comm)
| IN | sendbuf | адрес буфера посылки (альтернатива, используется только корневым процессом) | |
| IN | sendcounts | целочисленный массив (размера группы), определяющий число элементов, для отправки каждому процессу | |
| IN | displs | целочисленный массив (размера группы). Элемент i указывает смещение (относительно sendbuf, из которого берутся данные для процесса take the i) | |
| IN | sendtype | тип элементов посылающего буфера (дескриптор) | |
| OUT | recvbuf | адрес принимающего буфера (альтернатива) | |
| IN | recvcount | число элементов в посылающем буфере (целое) | |
| IN | recvtype | тип данных элементов принимающего буфера (дескриптор) | |
| IN | root | номер посылающего процесса (целое) | |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Scatterv(void* sendbuf, int *sendcounts, int *displs,
MPI_Datatype sendtype, void* recvbuf, int recvcount,
MPI_Datatype recvtype, int root, MPI_Comm comm)
MPI_SCATTERV(SENDBUF, SENDCOUNTS, DISPLS, SENDTYPE,
RECVBUF, RECVCOUNT, RECVTYPE,
ROOT, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNTS(*),
DISPLS(*), SENDTYPE, RECVCOUNT, RECVTYPE, ROOT, COMM, IERROR
void MPI::Intracomm::Scatterv(const void* sendbuf,
const int sendcounts[], const int displs[],
const Datatype& sendtype, void* recvbuf, int recvcount,
const Datatype& recvtype, int root) const
По сравнению с MPI_GATHER при использовании функции MPI_GATHERV разрешается принимать от каждого процесса переменное число элементов данных, поэтому в функции MPI_GATHERV аргумент recvcount является массивом. Она также обеспечивает большую гибкость в размещении данных в корневом процессе. Для этой цели используется новый аргумент displs.
Выполнение MPI_GATHERV будет давать такой же результат, как если бы каждый процесс, включая корневой, послал бы корневому процессу сообщение
MPI_Send(sendbuf + displs[i] * extent(sendtype), sendcounts[i], sendtype, i, ...),
и корневой процесс выполнил n операций приема
MPI_Recv(recvbuf, recvcount, recvtype, i, ...).
Сообщения помещаются в принимающий буфер корневого процесса в порядке возрастания их номеров, то есть данные, посланные процессом j помещено в j-ю часть принимающего буфера recvbuf на корневом процессе. j-я часть recvbuf начинается со смещения displs[j].
Номер принимающего буфера игнорируется во всех некорневых процессах.
![\includegraphics[width=5.34in,height=2.82in]{Ch4figure2.eps}](img28.png)
Сигнатура типа, используемая sendcount, sendtype в процессе i должна быть такой же, как и сигнатура, используемая recvcounts[i], recvtype в корневом процессе. Необходимо, чтобы количество посланных и полученных данных совпадало попарно для корневого и каждого другого процессов. Однако по-прежнему разрешается различие в картах типов между отправителями и получателями, как показано на примере 4.6.
В корневом процессе используются все аргументы функции MPI_GATHERV, а на всех других процессах используются только аргументы sendbuf, sendcount, sendtype, root, comm. Переменные comm и root должны иметь одинаковые значения во всех процессах.
Описанные в функции MPI_GATHERV количества, типы данных и смещения не должны приводить к тому, чтобы любая область корневого процесса записывалась бы более одного раза. Такой вызов является неверным.
Пример 4.11 Обратен примеру 4.2, MPI_SCATTER рассылает 100 чисел типа int из корневого процесса каждому процессу в группе (рис. 4.7).
MPI_Comm comm;
int gsize,*sendbuf;
int root, rbuf[100];
...
MPI_Comm_size(comm, &gsize);
sendbuf = (int *)malloc(gsize*100*sizeof(int));
...
MPI_Scatter(sendbuf, 100, MPI_INT, rbuf, 100, MPI_INT, root, comm);
Пример 4.12 Обратен примеру 4.5. Корневой процесс рассылает множества из 100 чисел типа int остальным процессам, но множества размещены в посылающем буфере с шагом stride, поэтому нужно использовать MPI_SCATTERV. Полагаем stride > 100 (рис. 4.8).
MPI_Comm comm;
int gsize,*sendbuf;
int root, rbuf[100], i, *displs, *scounts;
...
MPI_Comm_size(comm, &gsize);
sendbuf = (int*)malloc(gsize*stride*sizeof(int));
...
displs = (int*)malloc(gsize*sizeof(int));
scounts = (int*)malloc(gsize*sizeof(int));
for (i=0; i<gsize; ++i) {
displs[i] = i*stride;
scounts[i] = 100;
}
MPI_Scatterv(sendbuf, scounts, displs, MPI_INT, rbuf, 100,
MPI_INT, root, comm);
Пример 4.13 Обратен примеру 4.9, на стороне корневого процесса используется изменяющийся stride между блоками чисел, на приемной стороне производится прием в i-й столбец С-массива размера 100x150 (рис. 4.9).
MPI_Comm comm;
int gsize,recvarray[100][150],*rptr;
int root, *sendbuf, myrank, bufsize, *stride;
MPI_Datatype rtype;
int i, *displs, *scounts, offset;
...
MPI_Comm_size(comm, &gsize);
MPI_Comm_rank(comm, &myrank);
stride = (int *)malloc(gsize*sizeof(int));
...
/* stride[i] for i = 0 to gsize-1 is set somehow
* sendbuf comes from elsewhere
*/
...
displs = (int*)malloc(gsize*sizeof(int));
scounts = (int*)malloc(gsize*sizeof(int));
offset = 0;
for (i=0; i<gsize; ++i) {
displs[i] = offset;
offset += stride[i];
scounts[i] = 100 - i;
}
/* создается тип данных для посылаемого столбца
*/
MPI_Type_vector(100-myrank, 1, 150, MPI_INT, &rtype);
MPI_Type_commit(&rtype);
rptr = &recvarray[0][myrank];
MPI_Scatterv(sendbuf, scounts, displs, MPI_INT, rptr,
1, rtype, root, comm);
Синтаксис функции сборки Gather-to-all представлен ниже.
MPI_ALLGATHER(sendbuf, sendcount, sendtype, recvbuf, recvcount, recvtype, comm)
| IN | sendbuf | начальный адрес посылающего буфера (альтернатива) | |
| IN | sendcount | количество элементов в буфере (целое) | |
| IN | sendtype | тип данных элементов в посылающем буфере (дескриптор) | |
| OUT | recvbuf | адрес принимающего буфера (альтернатива) | |
| IN | recvcount | количество элементов, полученных от любого процесса (целое) | |
| IN | recvtype | тип данных элементов принимающего буфера (дескриптор) | |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Allgather(void* sendbuf,
int sendcount, MPI_Datatype sendtype, void* recvbuf,
int recvcount, MPI_Datatype recvtype, MPI_Comm comm)
MPI_ALLGATHER(SENDBUF, SENDCOUNT,
SENDTYPE, RECVBUF, RECVCOUNT,
RECVTYPE, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*) INTEGER SENDCOUNT, SENDTYPE,
RECVCOUNT, RECVTYPE,
COMM, IERROR
void MPI::Intracomm::Allgather(const void* sendbuf, int sendcount,
const Datatype& sendtype, void* recvbuf, int recvcount,
const Datatype& recvtype) const
Функцию MPI_ALLGATHER можно представить как MPI_GATHER, где результат принимают все процессы, а не только главный. Блок данных, посланный j-м процессом принимается каждым процессом и помещается в j-й блок буфера recvbuf.
Сигнатура типа, связанная с sendcount, sendtype, должна быть одинаковой во всех процессах.
Результат выполнения вызова MPI_ALLGATHER(...) такой же, как если бы все процессы выполнили n вызовов
MPI_GATHER(sendbuf, sendcount, sendtype, recvbuf, recvcount, recvtype, root, comm),для root = 0, ..., n-1. Правила корректного использования MPI_ALLGATHER соответствуют правилам для MPI_GATHER.
Синтаксис функции сборки MPI_ALLGATHERV представлен ниже.
MPI_ALLGATHERV(sendbuf,sendcount,sendtype,recvbuf,recvcounts, displs,recvtype,comm)
| IN | sendbuf | начальный адрес посылающего буфера (альтернатива) | |
| IN | sendcount | количество элементовв посылающем буфере (целое) | |
| IN | sendtype | тип данных элементов в посылающем буфере (дескриптор) | |
| OUT | recvbuf | адрес принимающего буфера (альтернатива) | |
| IN | recvcounts | целочисленный массив (размера группы) содержащий количество элементов, полученых от каждого процесса | |
| IN | displs | целочисленный массив (размера группы). Элемент i представляет смещение области (относительно recvbuf), где на помещаются принимаемые данные от процесса i | |
| IN | recvtype | тип данных элементов принимающего буфера(дескриптор) | |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Allgatherv(void* sendbuf, int sendcount,
MPI_Datatype sendtype, void *recvbuf,int *recvcounts,
int *displs, MPI_Datatype recvtype, MPI_Comm comm)
MPI_ALLGATHERV(SENDBUF, SENDCOUNT, SENDTYPE, RECVBUF,
RECVCOUNTS, DISPLS, RECVTYPE, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*) INTEGER SENDCOUNT, SENDTYPE,
RECVCOUNTS(*), DISPLS(*), RECVTYPE, COMM, IERROR
void MPI::Intracomm::Allgatherv(const void* sendbuf,
int sendcount, const Datatype& sendtype, void* recvbuf,
const int recvcounts[], const int displs[],
const Datatype& recvtype) const
Функцию MPI_ALLGATHERV можно представить как MPI_GATHERV, но при ее использовании результат получают все процессы, а не только один корневой. j-й блок данных, посланный каждым процессом, принимается каждым процессом и помещается в j-й блок буфера recvbuf. Эти блоки не обязаны быть одинакового размера.
Сигнатура типа, связанного с sendcount, sendtype в процессе j должна быть такой же, как сигнатура типа, связанного с recvcounts[j], recvtype в любом другом процессе.
Результат вызова MPI_ALLGATHERV(...) такой же, как если бы все процессы выполнили n вызовов
MPI_GATHERV(sendbuf, sendcount, sendtype, recvbuf,
recvcounts, displs, recvtype, root, comm),
для root = 0, ..., n-1. Правила корректного использования MPI_ALLGATHERV соответствуют правилам для MPI_GATHERV.
Пример 4.14 Это версия примера 4.2 с использованием all-gather. Здесь осуществляется сбор 100 чисел типа int от каждого процесса в группе для каждого процесса.
MPI_Comm comm;
int gsize,sendarray[100];
int *rbuf;
...
MPI_Comm_size(comm, &gsize);
rbuf = (int *)malloc(gsize*100*sizeof(int));
MPI_Allgather(sendarray, 100, MPI_INT, rbuf, 100, MPI_INT, comm);
После исполнения вызова каждый процесс содержит конкатенацию данных всей группы.
Синтаксис функции All-to-all Scatter/Gather представлен ниже.
MPI_ALLTOALL(sendbuf, sendcount, sendtype, recvbuf, recvcount, recvtype, comm)
| IN | sendbuf | начальный адрес посылающего буфера (альтернатива) | |
| IN | sendcount | количество элементов, посылаемых в каждый процесс (целое) | |
| IN | sendtype | тип данных элементов посылающего буфера (дескриптор) | |
| OUT | recvbuf | адрес принимающего буфера (альтернатива) | |
| IN | recvcount | количество элементов, принятых от какого-либо процесса (целое) | |
| IN | recvtype | тип данных элементов принимающего буфера (дескриптор) | |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Alltoall(void* sendbuf, int sendcount, MPI_Datatype sendtype,
void* recvbuf, int recvcount, MPI_Datatype recvtype, MPI_Comm comm)
MPI_ALLTOALL(SENDBUF, SENDCOUNT,
SENDTYPE, RECVBUF, RECVCOUNT,
RECVTYPE, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNT, SENDTYPE, RECVCOUNT, RECVTYPE, COMM, IERROR
void MPI::Intracomm::Alltoall(const void* sendbuf, int sendcount,
const Datatype& sendtype, void* recvbuf, int recvcount,
const Datatype& recvtype) const
MPI_ALLTOALL - это расширение функции MPI_ALLGATHER для случая, когда каждый процесс посылает различные данные каждому получателю. j-й блок, посланный процессом i, принимается процессом j и помещается в i-й блок буфера recvbuf.
Сигнатура типа, связанная с sendcount, sendtype
в каждом процессе должна быть такой же, как и в любом другом
процессе. Необходимо, чтобы количество посланных данных было равно количеству
полученных данных между каждой парой процессов. Как обычно, карты типа могут
отличаться.
Результат выполнения функции MPI_ALLTOALL такой же, как если бы каждый процесс выполнил посылку данных каждому процессу (включая себя) вызовом
MPI_Send(sendbuf + i * sendcount * extent(sendtype),
sendcount, sendtype, i, ...),
и принял данные от всех остальных процессов путем вызова
MPI_Recv(recvbuf + i* recvcount* extent(recvtype), recvcount, i, ...).
Все аргументы используются всеми процессами. Аргумент comm должен иметь одинаковое значение во всех процессах.
Синтаксис функции MPI_ALLTOALLV представлен ниже.
MPI_ALLTOALLV(sendbuf,sendcounts,sdispls,sendtype, recvbuf,recvcounts,rdispls,recvtype,comm)
| IN | sendbuf | начальный адрес посылающего буфера (альтернатива) | |
| IN | sendcounts | целочисленный массив (размера группы), определяющий количество посылаемых каждому процессу элементов | |
| IN | sdispls | целочисленный массив(размера группы). Элемент j содержит смещение области (относительно sendbuf), из которой берутся данные для процесса j | |
| IN | sendtype | тип данных элементов посылающего буфера (дескриптор) | |
| OUT | recvbuf | адрес принимающего буфера (альтернатива) | |
| IN | recvcounts | целочисленный массив (размера группы), содержащий число элементов, которые могут быть приняты от каждого процессса | |
| IN | rdispls | целочисленный массив (размера группы). Элемент i определяет смещение области (относительно recvbuf), в которой размещаются данные, получаемые из процесса i | |
| IN | recvtype | тип данных элементов приинмающего буфера (дескриптор) | |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Alltoallv(void *sendbuf, int *sendcounts, int *sdispls,
MPI_Datatype sendtype, void *recvbuf, int *recvcounts, int *rdispls,
MPI_Datatype recvtype, MPI_Comm comm)
MPI_ALLTOALLV(SENDBUF, SENDCOUNTS,
SDISPLS, SENDTYPE, RECVBUF,
RECVCOUNTS,
RDISPLS, RECVTYPE, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER SENDCOUNTS(*),
SDISPLS(*), SENDTYPE, RECVCOUNTS(*),
RDISPLS(*), RECVTYPE, COMM,
IERROR
void MPI::Intracomm::Alltoallv(const void* sendbuf, const int sendcounts[],
const int sdispls[], const Datatype& sendtype, void* recvbuf,
const int recvcounts[], const int rdispls[], const Datatype& recvtype) const
MPI_ALLTOALLV обладает большей гибкостью, чем функция
MPI_ALLTOALL, поскольку размещение данных на передающей
стороне определяется аргументом sdispls, а на стороне
приема - независимым аргументом rdispls.
j-й блок, посланный процессом i, принимается процессом j и помещается в i-й блок recvbuf. Эти блоки не обязаны быть одного размера.
Сигнатура типа, связанная с sendcount[j], sendtype
в процессе i, должна быть такой же и для процесса j. Необходимо,
чтобы количество посланных данных было равно количеству полученных данных
для каждой пары процессов. Карты типа для отправителя и приемника могут
отличаться.
Результат выполнения MPI_ALLTOALLV такой же, как если бы процесс посылал сообщение всем остальным процессам с помощью функции
MPI_Send(sendbuf + displs[i] * extent(sendtype), sendcounts[i], sendtype, i, ...),и принимал сообщение от всех остальных процессов, вызывая
MPI_Recv(recvbuf + displs[i] * extent(recvtype), recvcounts[i],
recvtype, i, ...).
Все аргументы используются всеми процессами. Значение аргумента comm должно быть одинаковым во всех процессах.
Объяснение: Определения функций MPI_ALLTOALL и MPI_ALLTOALLV дают столько же гибкости, сколько можно было бы получить, используя n независимых парных межпроцессных обменов, но с двумя исключениями: все сообщения используют один и тот же тип данных, и сообщения разосланы из (или собраны от) непрерывной памяти.[]
Совет разработчикам: Хотя обсуждение коллективных операций с помощью парных обменов подразумевает, что каждое сообщение перемещено непосредственно от процесса-отправителя процессу-получателю, реализации могут использовать древовидную схему связи. Сообщения могут быть посланы промежуточными узлами, где они разделяются (для scatter) или объединяются (для gather), если это более эффективно.[]
Привлекательность парадигмы передачи сообщений по крайней мере частично объясняется мобильностью. Программы, написанные таким способом, могут выполняться на мультипроцессорах с распределенной памятью, сетях рабочих станций или на комбинации тех и других. К тому же, возможны реализации с распределенной памятью. Парадигма не должна устаревать в отношении архитектуры при комбинировании разделяемой и распределенной памяти или из-за увеличения скорости сетей. Именно поэтому следует включить обе возможности и полезно реализовать этот стандарт на большом разнообразии машин, включая ``машины'', состоящие из собрания других машин, парллельных либо нет, соединенных коммуникационной сетью.
Интерфейс пригоден как для написания MIMD программ, так и программ, написанных в более ограниченном стиле для SPMD машин. Хотя никакой явной поддержки потоков нет, интерфейс спроектирован так, чтобы не ущемлять их использование. В этой версии MPI не предусмотрено никакой поддержки для динамического распределения задач.
MPI предоставляет много возможностей для улучшению характеристик на масштабируемых параллельных компьютерах со специализированным межпроцессорным коммуникационным оборудованием. Поэтому ожидается, что реализация, соответствующая природе MPI, будет создана именно на таких машинах. В то же самое время реализация MPI на основе протоколов межпроцессорного обмена стандарта Unix обеспечит мобильность для кластеров рабочих станций и неоднородных сетей рабочих станций. На момент написания стандарта в состоянии разработки находятся несколько реализаций MPI, работа выполняется частными компаниями и государственными организациями [17,13].
Функции, описанные в этом разделе, предназначены для выполнения операций глобальной редукции (суммирование, нахождение максимума, логическое И, и т.д.) для всех элементов группы. Операция редукции может быть выбрана из предопределенного списка операций, или определяться пользователем. Функции глобальной редукции имеют несколько разновидностей: операции, возвращающие результат в один узел; функции (all-reduce), возвращающие результат во все узлы; операция просмотра. Дополнительно, операция редукции - раздачи (reduce-scatter) сочетает возможности этих операций.
Синтаксис функции редукции MPI_REDUCE представлен ниже.
MPI_REDUCE(sendbuf, recvbuf, count, datatype, op, root, comm)
| IN | sendbuf | адрес посылающего буфера (альтернатива) | |
| OUT | recvbuf | адрес принимающего буфера (альтернатива, используется только корневым процессом) | |
| IN | count | количество элементов в посылающем буфере (целое) | |
| IN | datatype | тип данных элементов посылающего буфера (дескриптор) | |
| IN | op | операция редукции (дескриптор) | |
| IN | root | номер главного процесса (целое) | |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Reduce(void* sendbuf, void* recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm)
MPI_REDUCE(SENDBUF, RECVBUF, COUNT, DATATYPE, OP, ROOT, COMM,
IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER COUNT, DATATYPE, OP, ROOT, COMM, IERROR
void MPI::Intracomm::Reduce(const void* sendbuf, void* recvbuf,
int count, const Datatype& datatype, const Op& op, int root) const
Функция MPI_REDUCE объединяет элементы входного буфера каждого процесса в группе, используя операцию op , и возвращает объединенное значение в выходной буфер процесса с номером root. Буфер ввода определен аргументами sendbuf, count и datatype; буфер вывода определен параметрами recvbuf, count и datatype; оба буфера имеют одинаковое число элементов одинакового типа. Функция вызывается всеми членами группы с одинаковыми аргументами count, datatype, op, root и comm. Таким образом, все процессы имеют входные и выходные буферы одинаковой длины и с элементами одного типа. Каждый процесс может содержать либо один элемент, либо последовательность элементов, в последнем случае операция выполняется над всеми элементами в этой последовательности. Например, если выполняется операция MPI_MAX , и посылающий буфер содержит два элемента - числа с плавающей точкой (count = 2, datatype = MPI_FLOAT), то recvbuf(1) = sendbuf(1) и recvbuf(2) = sendbuf(2).
В разделе 4.9.2 представлен список предопределенных операций редукций в MPI . В этом разделе также перечислены все типы данных, к которым могут быть применены эти операции. Дополнительно пользователи могут определять свои собственные операции, которые могут быть применены для различных типов данных, как базовых, так и переопределенных. Это объясняется далее в разделе 4.9.4.
Операция op всегда считается ассоциативной, а все предопределенные операции - коммутативными. Пользователи могут создавать операции, которые могут быть ассоциативными, но не коммутативными. ``Канонический'' порядок оценки редукции определен нумерацией процессов в группе. Однако, реализация может воспользоваться преимуществом либо ассоциативности, либо ассоциативности и коммутативности, чтобы изменить порядок оценки. Но это может изменить результат редукции для операций, которые не строго ассоциативны и коммутативны, например, для сложения чисел с плавающей точкой.
Совет разработчикам: Настоятельно рекомендуется, чтобы операция MPI_REDUCE была реализована так, чтобы всякий раз, когда функция вызывается с теми же параметрами, поставленными в том же порядке, получался одинаковый результат. Возможно, это может ограничивать оптимизацию, которую можно было бы получить, используя преимущество физического расположения процессоров.[]
Аргумент datatype в MPI_REDUCE должен быть совместимым с аргументом op. Предопределенные операции работают только с типами MPI , описанными в разделах 4.9.2 и 4.9.3. Определяемые пользователем операции могут оперировать и с производными типами. В этом случае каждый аргумент, к которому применяется операция редукции - это аргумент, описанный таким datatype , который может содержать несколько базисных значений. Это далее объяснено в разделе 4.9.4.
Следующие предопределенные операции могут использоваться MPI_REDUCE и родственными функциями MPI_ALLREDUCE, MPI_REDUCE_SCATTER и MPI_SCAN. Аргумент op может принимать следующие значения:
| Имя | Значение |
| MPI_MAX | максимум |
| MPI_MIN | минимум |
| MPI_SUM | сумма |
| MPI_PROD | произведение |
| MPI_LAND | логическое И |
| MPI_BAND | поразрядное И |
| MPI_LOR | логическое ИЛИ |
| MPI_BOR | поразрядное ИЛИ |
| MPI_LXOR | логическое исключающее ИЛИ |
| MPI_BXOR | поразрядное исключающее ИЛИ |
| MPI_MAXLOC | максимальное значение и местонахождения |
| MPI_MINLOC | минимальное значение и местонахождения |
Операции MPI_MINLOC и MPI_MAXLOC обсуждаются далее в разделе 4.9.3. Для остальных предопределенных операций ниже приводятся разрешенные комбинации аргументов op и datatype. Но прежде определим группу основных типов данных MPI следующим образом:
| Си integer: | MPI_INT, MPI_LONG, MPI_SHORT, MPI_UNSIGNED_SHORT, MPI_UNSIGNED, MPI_UNSIGNED_LONG |
| ФОРТРАН integer: | MPI_INTEGER |
| Floating point: | MPI_FLOAT, MPI_DOUBLE, MPI_REAL, MPI_DOUBLE_PRECISION, MPI_LONG_DOUBLE |
| Logical: | MPI_LOGICAL |
| Complex: | MPI_COMPLEX |
| Byte: | MPI_BYTE |
Правильные типы данных для каждой операции определены ниже.
| Op | Разрешенные типы |
| MPI_MAX, MPI_MIN | Си integer, ФОРТРАН integer, Floating point |
| MPI_SUM, MPI_PROD | Си integer, ФОРТРАН integer, Floating point, Complex |
| MPI_LAND, MPI_LOR, MPI_LXOR | Си integer, Logical |
| MPI_BAND, MPI_BOR, MPI_BXOR | Си integer, ФОРТРАН integer, Byte |
Пример 4.15 Процедура вычисляет скалярное произведение двух векторов, распределенных в группе процессов, и возвращает результат в нулевой узел.
SUBROUTINE PAR_BLAS1(m, a, b, c, comm) REAL a(m), b(m) ! локальная часть массива REAL c ! результат (на узле ноль) REAL sum INTEGER m, comm, i, ierr ! локальная сумма sum = 0.0 DO i = 1, m sum = sum + a(i)*b(i) END DO } !глобальная сумма CALL MPI_REDUCE(sum, c, 1, MPI_REAL, MPI_SUM, 0, comm, ierr) RETURN
Пример 4.16 Процедура вычисляет произведение вектора на массив, которые распределены в группе процессов, и возвращает результат в нулевой узел.
SUBROUTINE PAR_BLAS2(m, n, a, b, c, comm)
REAL a(m), b(m,n) ! локальная часть массива
REAL c(n) ! результат
REAL sum(n)
INTEGER n, comm, i, j, ierr
!локальная сумма
DO j= 1, n
sum(j) = 0.0
DO i = 1, m
sum(j) = sum(j) + a(i)*b(i,j)
END DO
END DO
! глобальная сумма
CALL MPI_REDUCE(sum, c, n, MPI_REAL, MPI_SUM, 0, comm, ierr)
RETURN
Оператор MPI_MINLOC используется для расчета глобального минимума и соответствующего ему индекса. MPI_MAXLOC аналогично считает глобальный максимум и индекс. Одно из применений этих операций - вычисление глобального минимума (максимума) и номера процесса, содержащего это значение.
Операция, которая определяет MPI_MAXLOC , такова:
где w = max(u, v) и

MPI_MINLOC определен аналогично:
где w = min(u, v) и
Обе операции ассоциативны и коммутативны. Отметим, что если
MPI_MAXLOC применяется для последовательности пар (u![]() , 0),
(u
, 0),
(u![]() , 1), ..., (u
, 1), ..., (u![]() , n-1), то возвращаемое значение есть (u,
r), где u=max
, n-1), то возвращаемое значение есть (u,
r), где u=max![]() (u
(u![]() и r - индекс первого глобального максимума в
последовательности. Таким образом, если каждый процесс предоставляет
значение и свой номер в группе, тогда операция редукции с op =
MPI_MAXLOC возвратит значение максимума и номер первого процесса с этим
значением. Аналогично, MPI_MINLOC может быть использована для
получения минимума и его индекса. В общем, MPI_MINLOC вычисляет
лексикографический минимум , где элементы упорядочены согласно первому
компоненту каждой пары, и отношение разрешается согласно второму компоненту.
и r - индекс первого глобального максимума в
последовательности. Таким образом, если каждый процесс предоставляет
значение и свой номер в группе, тогда операция редукции с op =
MPI_MAXLOC возвратит значение максимума и номер первого процесса с этим
значением. Аналогично, MPI_MINLOC может быть использована для
получения минимума и его индекса. В общем, MPI_MINLOC вычисляет
лексикографический минимум , где элементы упорядочены согласно первому
компоненту каждой пары, и отношение разрешается согласно второму компоненту.
Операция редукции определена для работы с аргументами, содержащими пару: значение и индекс. Как в языке ФОРТРАН , так и для языка Си имеются типы данных для описания этой пары. Потенциально смешанная природа таких параметров является проблемой для языка ФОРТРАН. Для языка ФОРТРАН проблема обойдена благодаря наличию в MPI типа, состоящего из пары того же типа, что и значение, и присоединенного к этому типу индекса. Для языка Си MPI предоставляет парный тип, части которого имеют различный тип и индекс имеет тип int .
Чтобы использовать MPI_MINLOC и MPI_MAXLOC в операции редукции, нужно обеспечить аргумент datatype, который представляет пару (значение и индекс). MPI предоставляет девять таких предопределенных типов данных. Операции MPI_MAXLOC и MPI_MINLOC могут быть использованы со следующими типами данных:
| ФОРТРАН: | |
| Название | Описание |
| MPI_2REAL | пара переменных типа REAL |
| MPI_2DOUBLE_PRECISION | пара переменных типа DOUBLE PRECISION |
| MPI_2INTEGER | пара переменных типа INTEGER |
| Си: | |
| Название | Описание |
| MPI_FLOAT_INT | переменные типа float и int |
| MPI_DOUBLE_INT | переменные типа double и int |
| MPI_LONG_INT | переменные типа long и int |
| MPI_2INT | пара переменных типа int |
| MPI_SHORT_INT | переменные типа short и int |
| MPI_LONG_DOUBLE_INT | переменные типа long double и int |
Тип данных MPI_2REAL аналогичен тому, как если бы он был определен следующим образом (см. раздел 3.12).
MPI_TYPE_CONTIGOUS(2, MPI_REAL, MPI_2REAL)
Аналогичными выражениями задаются MPI_2INTEGER, MPI_2DOUBLE_PRECISION и MPI_2INT.
Тип данных MPI_FLOAT_INT аналогичен тому, как если бы он был объявлен следующей последовательностью инструкций.
type[0] = MPI_FLOAT
type[1] = MPI_INT
disp[0] = 0
disp[1] = sizeof(float)
block[0] = 1
block[1] = 1
MPI_TYPE_STRUCT(2, block, disp, type, MPI_FLOAT_INT)
Подобные выражения относятся и к MPI_LONG_INT и MPI_DOUBLE_INT.
Пример 4.17 Каждый процесс имеет массив 30 чисел типа double на языке Си. Для каждой из 30 областей надо вычислить значение и номер процесса, содержащего наибольшее значение.
...
/* каждый процесс имет массив из 30 чисел двойной точности: ain[30]
*/
double ain[30], aout[30];
int ind[30];
struct {
double val;
int rank;
} in[30], out[30];
int i, myrank, root;
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
for (i=0; i<30; ++i) {
in[i].val = ain[i];
in[i].rank = myrank;
}
MPI_Reduce(in, out, 30, MPI_DOUBLE_INT, MPI_MAXLOC, root, comm);
/* в этой точке результат помещается на корневой процесс
*/
if (myrank == root) {
/* читаются выходные номера
*/
for (i=0; i<30; ++i) {
aout[i] = out[i].val;
ind[i] = out[i].rank; !номер обратно преобразуется в целое
}
}
Пример 4.18 Тот же пример для языка ФОРТРАН.
...
! каждый процесс имеет массив из 30 чисел двойной точности: ain(30)
DOUBLE PRECISION ain(30), aout(30)
INTEGER ind(30);
DOUBLE PRECISION in(2,30), out(2,30)
INTEGER i, myrank, root, ierr;
MPI_COMM_RANK(MPI_COMM_WORLD, myrank);
DO I=1, 30
in(1,i) = ain(i)
in(2,i) = myrank ! myrank преобразуется к типу double
END DO
MPI_REDUCE(in, out, 30, MPI_2DOUBLE_PRECISION, MPI_MAXLOC, root,
comm, ierr);
! в этой точке результат помещается на корневой процесс
IF (myrank .EQ. root) THEN
! читаются выходные номера
DO I= 1, 30
aout(i) = out(1,i)
ind(i) = out(2,i)
END DO
END IF
Пример 4.19 Каждый процесс имеет непустой массив чисел. Требуется найти минимальное глобальное число, номер процесса, хранящего его, и его индекс в этом процессе.
#define LEN 1000
float val[LEN]; /* локальный массив значений */
int count; /* локальное количество значений */
int myrank, minrank, minindex;
float minval;
struct {
float value;
int index;
} in, out;
/* локальный minloc */
in.value = val[0];
in.index = 0;
for (i=1; i < count; i++)
if (in.value > val[i]) {
in.value = val[i];
in.index = i;
}
/* глобальный minloc */
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
in.index = myrank*LEN + in.index;
MPI_Reduce(in, out, 1, MPI_FLOAT_INT, MPI_MINLOC, root, comm);
/* в этой точке результат помещается на корневой процесс
*/
if (myrank == root) {
minval = out.value;
minrank = out.index / LEN;
minindex = out.index % LEN;
}
Объяснение: Данное здесь определение MPI_MINLOC и MPI_MAXLOC имеет то достоинство, что оно не приводит к необходимости какой-либо специальной обработки для этих двух операций: они обрабатываются, как и другие операции редукции. Если необходимо, программист может создать собственные определения MPI_MAXLOC и MPI_MINLOC . Недостаток определения состоит в том, что значения и индексы должны чередоваться, и индексы и переменные должны быть приведены к одному типу для языка ФОРТРАН.[]
Синтаксис функции MPI_OP_CREATE представлен ниже.
MPI_OP_CREATE(function, commute, op)
| IN | function | определяемая пользователем операция (функция) | |
| IN | commute | true, если операция коммутативна; иначе false. | |
| OUT | op | операция (дескриптор) |
int MPI_Op_create(MPI_User_function *function, int commute, MPI_Op *op)
MPI_OP_CREATE(FUNCTION, COMMUTE, OP, IERROR)
EXTERNAL FUNCTION
LOGICAL COMMUTE
INTEGER OP, IERROR
void MPI::Op::Init(User_function* function, bool commute)
Функция MPI_OP_CREATE связывает определенную пользователем
глобальную операцию с указателем op, который впоследствии может быть
использован в MPI_REDUCE, MPI_ALLREDUCE,
MPI_SCATTER и
MPI_SCAN. Определенная пользователем операция предполагается
ассоциативной. Если commute = true, то операция должна быть как
коммутативной, так и ассоциативной. Если commute = false, то порядок
операндов фиксирован, операнды располагаются по возрастанию номеров
процессов, начиная с нулевого. Порядок оценки может быть изменен, чтобы
использовать преимущество ассоциативности операции. Если commute =
true, то порядок оценки может быть изменен, чтобы использовать достоинства
коммутативности и ассоциативности.
function - определенная пользователем функция, которая должна иметь следующие аргументы: invec, inoutvec, len и datatype.
В ANSI Си прототип для этой функции следующий:
typedef void MPI_User_function(void *invec,
void *inoutvec, int *len, MPI_Datatype *datatype);
Декларация определяемой пользователем функции для языка ФОРТРАН дана ниже:
SUBROUTINE USER_FUNCTION(INVEC, INOUTVEC, LEN, TYPE) <type> INVEC(LEN), INOUTVEC(LEN) INTEGER LEN, TYPE
Аргумент datatype - это дескриптор типа данных, которые были посланы
в вызове MPI_REDUCE. Пользовательская функция редукции должна быть
написана так, чтобы удовлетворять следующему: пусть u[0], ...,
u[len-1] - len элементов в буфере обмена, описанных параметрами invec, len и datatype при вызове функции; пусть v[0], ...,
v[len-1] - len элементов в буфере обмена, описанных аргументами inoutvec, len и datatype при вызове функции; пусть w[0], ...,
w[len-1] - len элементов в буфере обмена, описанных параметрами inoutvec, len и datatype, когда функция возвращает
управление; тогда w[i] = u[i] ![]() v[i], для i=0, ...
. len-1, где
v[i], для i=0, ...
. len-1, где ![]() -операция редукции, которую вычисляет функция.
-операция редукции, которую вычисляет функция.
Неформально, можно считать inoutvec и invec массивами из len элементов, которые комбинирует function. Результат операции
редукции перезаписывает величины в inoutvec, что и определяет имя.
Результатом каждого вызова функции является поточечная оценка оператором
редукции len элементов: т.е. функция возвращает в inoutvec[i]
значение invec[i] ![]() inoutvec[i] для i = 0, ...,
count-1, где
inoutvec[i] для i = 0, ...,
count-1, где ![]() - операция объединения, считающаяся функцией.
- операция объединения, считающаяся функцией.
Объяснение: Аргумент len позволяет MPI_REDUCE избежать вызова функции для каждого элемента во входном буфуре. Предпочтительнее, чтобы система могла применять функцию к порциям входа. На языке Си это передается по ссылке для совместимости с языком ФОРТРАН.
Сравнение значения параметра datatype с известными показывает, что возможно использование отдельных определенных пользователем функций для нескольких отличающихся данных.[]
В функции пользователя можно использовать общие типы данных, однако, если они не непрерывны, то скорее всего это приведет к неэффективности.
Никакая функции обмена MPI не может вызываться из пользовательской функции. Из пользовательской функции в случае ошибки может быть вызвана функция MPI_ABORT.
Совет пользователям: Предположим, что создается библиотека определяемых пользователем функций редукции, которые являются перегруженными: параметр datatype используется, чтобы выбрать правильный путь выполнения при каждом вызове, согласно типам операндов. Определяемая пользователем функция не может ``декодировать'' параметр datatype, который ей передан, и не может определить самостоятельно соответствие между дескрипторами типа данных и типом данных, который они представляют. Это соответствие было установлено, когда типы данных создавались. Прежде чем использовать библиотеку, должна быть выполнена преамбула библиотечной инициализации. Код преамбулы определит типы данных, которые используются библиотекой, и сохранит дескрипторы этих типов данных в глобальных статических переменных, которые разделяются кодом пользователя и библиотечным кодом.
Версия MPI_REDUCE для языка ФОРТРАН вызовет определяемую пользователем функцию, используя соглашение о вызовах языка ФОРТРАН и передаст аргумент типа данных ФОРТРАН-типа; версия языка Си использует соглашение о вызовах Си и Си-представление дескриптора типа данных. Пользователи, которым придется использовать смешение языков, должны определять свои функции соответственно.[]
Совет разработчикам: Приведем пример наивной и неэффективной реализации MPI_REDUCE.
if (rank > 0) {
RECV(tempbuf, count, datatype, rank-1,...)
User_reduce(tempbuf, sendbuf, count, datatype)
}
if (rank < groupsize-1) {
SEND(sendbuf, count, datatype, rank+1, ...)
}
/* результат, который размещается в процессе groupsize-1 ... теперь
посылается в корневой процесс
*/
if (rank == groupsize-1) {
SEND(sendbuf, count, datatype, root, ...)
}
if (rank == root) {
RECV(recvbuf, count, datatype, groupsize-1,...)
}
Выполнение операции редукции происходит последовательно, от процесса 0 до
процесса
group-size-1. Этот порядок выбран, чтобы учесь
возможную
некоммутативность оператора, определенного функцией User_reduce().
Более эффективную реализацию можно получить, если использовать преимущество
ассоциативности и логарифмическую древовидную редукцию. Коммутативность
может быть использована как преимущество только в случае, когда аргумент
commute в MPI_OP_CREATE есть true. Также можно
уменьшить размер временного буфера и конвейеризовать обмен с вычислением,
пересылая и вычисляя редукцию в порциях размера len < count.
Предопределенные операции редукции могут быть реализованы как библиотека определенных пользователем операций. Однако, будет эффективнее, если MPI_REDUCE будет выполнять эти функции как частный случай.[]
Синтаксис функции MPI_OP_FREE(op) представлен ниже.
MPI_OP_FREE(op)
| INOUT | op | операция (дескриптор) |
int MPI_op_free(MPI_Op *op)
MPI_OP_FREE(OP, IERROR)
INTEGER OP, IERROR
void MPI::Op::Free()
Функция MPI_OP_FREE маркирует определенную пользователем операцию редукции для удаления и устанавливает значение MPI_OP_NULL для аргумента op.
Пример 4.20 Вычислить произведение массива комплексных чисел, язык Си. Используется определенная пользователем операция.
typedef struct {
double real,imag;
} Complex;
/* функция, опредленная пользователем
*/
void myProd(Complex *in, Complex *inout, int *len, MPI_Datatype *dptr)
{
int i;
Complex c;
for (i=0; i< *len; ++i) {
c.real = inout->real*in->real -
inout->imag*in->imag;
c.imag = inout->real*in->imag +
inout->imag*in->real;
*inout = c;
in++; inout++;
}
}
...
/* каждый процесс содержит массив из 100 комплексных чисел
*/
Complex a[100], answer[100];
MPI_Op myOp;
MPI_Datatype ctype;
/* объяснение для MPI, как определяется тип Complex
*/
MPI_Type_contiguous(2, MPI_DOUBLE, &ctype);
MPI_Type_commit(&ctype);
/* создается комплексная операция complex-product
*/
MPI_Op_create(myProd, True, &myOp);
MPI_Reduce(a, answer, 100, ctype, myOp, root, comm);
/* в этой точке результат из 100 Complexes,
* помещается на корневой процесс
*/
MPI имеет варианты каждой из операций редукции, где результат возвращается всем процессам группы. MPI требует, чтобы все процессы, участвующие в этих операциях, получили идентичные результаты.
Синтаксис функции MPI_ALLREDUCE представлен ниже.
MPI_ALLREDUCE(sendbuf, recvbuf, count, datatype, op, comm)
| IN | sendbuf | начальный адрес буфера посылки (альтернатива) | |
| OUT | recvbuf | начальный адрес буфера приема (альтернатива) | |
| IN | count | количество элементов в буфере посылки (целое) | |
| IN | datatype | тип данных элементов буфера посылки () | |
| IN | op | операция (дескриптор) | |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Allreduce(void* sendbuf, void* recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
MPI_ALLREDUCE(SENDBUF, RECVBUF, COUNT, DATATYPE, OP, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER COUNT, DATATYPE, OP, COMM, IERROR
void MPI::Intracomm::Allreduce(const void* sendbuf, void* recvbuf,
int count, const Datatype& datatype, const Op& op) const
Функция MPI_ALLREDUCE отличается от MPI_REDUCE тем, что результат появляется в буфере приема у всех членов группы.
Совет разработчикам: Операции типа all-reduce могут быть реализованы как последовательность операций reduce и bcast. Однако, прямая реализация может быть эффективнее.[]
Пример 4.21 Процедура вычисляет произведение вектора и массива, которые распределены по всем процессам группы, и возвращает ответ всем узлам (см.также пример 4.16).
SUBROUTINE PAR_BLAS2(m, n, a, b, c, comm)
REAL a(m), b(m,n) ! локальная часть иассива
REAL c(n) ! результат
REAL sum(n)
INTEGER n, comm, i, j, ierr
! локальная сумма
DO j= 1, n
sum(j) = 0.0
DO i = 1, m
sum(j) = sum(j) + a(i)*b(i,j)
END DO
END DO
! глобальная сумма
CALL MPI_ALLREDUCE(sum, c, n, MPI_REAL, MPI_SUM, comm, ierr)
! возвращение результата всем узлам
RETURN
MPI имеет варианты каждой из операций редукции, когда результат рассылается всем процессам в группе в конце операции.
Синтаксис функции MPI_REDUCE_SCATTER представлен ниже.
MPI_REDUCE_SCATTER(sendbuf, recvbuf, recvcounts, datatype, op, comm)
| IN | sendbuf | начальный адрес буфера посылки (альтернатива) | |
| OUT | recvbuf | начальный адрес буфера приема (альтернатива) | |
| IN | recvcounts | целочисленный массив, определяющий количество элементов результата, распределенных каждому процессу. Массив должен быть идентичен во всех вызывающих процессах. | |
| IN | datatype | тип данных элементов буфера ввода (дескриптор) | |
| IN | op | операция (дескриптор) | |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Reduce_scatter(void *sendbuf, void *recvbuf,
int *recvcounts, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
MPI_REDUCE_SCATTER(SENDBUF, RECVBUF, RECVCOUNTS,
DATATYPE, OP, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER RECVCOUNTS(*), DATATYPE, OP, COMM, IERROR
void Intracomm::Reduce_scatter(const void* sendbuf, void* recvbuf,
int recvcounts[], const Datatype& datatype, const Op& op) const
Функция MPI_REDUCE_SCATTER сначала производит поэлементную
редукцию вектора из count = ![]() recvcount[i]
элементов в буфере посылки, определенном sendbuf, count и datatype. Далее полученный вектор результатов разделяется на n непересекающихся сегментов, где n - число членов в группе.
Сегмент i содержит recvcount[i] элементов. i-й сегмент
посылается i-му процессу и хранится в буфере приема, определяемом
recvbuf, recvcounts[i] и datatype.
recvcount[i]
элементов в буфере посылки, определенном sendbuf, count и datatype. Далее полученный вектор результатов разделяется на n непересекающихся сегментов, где n - число членов в группе.
Сегмент i содержит recvcount[i] элементов. i-й сегмент
посылается i-му процессу и хранится в буфере приема, определяемом
recvbuf, recvcounts[i] и datatype.
Совет разработчикам: Функция MPI_REDUCE_SCATTER функционально эквивалентна операции MPI_REDUCE с count, равным сумме recvcounts[i], за которой следует MPI_SCATTER с sendcount, равным recvcounts. Однако, прямая реализация может работать быстрее. []
Синтаксис функции MPI_SCAN представлен ниже.
MPI_SCAN(sendbuf, recvbuf, count, datatype, op, comm)
| IN | sendbuf | начальный адрес буфера посылки (альтернатива) | |
| OUT | recvbuf | начальный адрес буфера приема (альтернатива) | |
| IN | count | количество элементов в буфере приема (целое) | |
| IN | datatype | тип данных элементов в буфере приема (дескриптор) | |
| IN | op | операция (дескриптор) | |
| IN | comm | коммуникатор (дескриптор) |
int MPI_Scan(void* sendbuf, void* recvbuf, int count,
MPI_Datatype datatype,
MPI_Op op, MPI_Comm comm)
MPI_SCAN(SENDBUF, RECVBUF, COUNT, DATATYPE, OP, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER COUNT, DATATYPE, OP, COMM, IERROR
void Intracomm::Scan(const void* sendbuf, void* recvbuf,
int count,
const Datatype& datatype, const Op& op) const
Функция MPI_SCAN используется, чтобы выполнить префиксную редукцию данных, распределенных в группе. Операция возвращает в приемный буфер процесса i редукцию значений в посылающих буферах процессов с номерами 0, ..., i (включительно). Тип поддерживаемых операций, их семантика, и ограничения на буфера посылки и приема - такие же, как и для MPI_REDUCE.
Пример 4.22 Этот пример построен на пользовательской операции, чтобы выполнить сегментированный просмотр. При сегментированном просмотре на вход принимается множество значений и множество логических величин, логические значения устанавливают различные сегменты для просмотра. Например:
Оператор, производящий этот эффект
где
Отметим, что это некоммутативный оператор. Код на языке Си, реализующий вычисления, представлен ниже.
typedef struct {
double val;
int log;
} SegScanPair;
/* функция, определенная пользователем
*/
void segScan(SegScanPair *in, SegScanPair *inout,
int *len, MPI_Datatype *dptr)
{
int i;
SegScanPair c;
for (i=0; i< *len; ++i) {
if (in->log == inout->log)
c.val = in->val + inout->val;
else
c.val = inout->val;
c.log = inout->log;
*inout = c;
in++; inout++;
}
}
Заметим, что параметр inout в определяемой пользователем функции соответствует правому операнду оператора. При использовании этого оператора необходимо быть внимательным, чтобы описать, что он некоммутативный, как в следующем листинге.
int i,base;
SeqScanPair a, answer;
MPI_Op myOp;
MPI_Datatype type[2] = {MPI_DOUBLE, MPI_INT};
MPI_Aint disp[2];
int blocklen[2] = { 1, 1};
MPI_Datatype sspair;
/* объяснение для MPI, как определяется тип SegScanPair
*/
MPI_Address(a, disp);
MPI_Address(a.log, disp+1);
base = disp[0];
for (i=0; i<2; ++i) disp[i] -= base;
MPI_Type_struct(2, blocklen, disp, type, &sspair);
MPI_Type_commit(&sspair);
/* создается пользовательская операция segmented-scan
*/
MPI_Op_create(segScan, False, &myOp);
...
MPI_Scan(a, answer, 1, sspair, myOp, root, comm);
Корректная переносимая программа должна работать без дедлоков. Приводимые ниже примеры иллюстрируют опасность использования коллективных опраций.
Пример 4.23 Следующий отрезок программы неверен.
switch(rank) {
case 0:
MPI_Bcast(buf1, count, type, 0, comm);
MPI_Bcast(buf2, count, type, 1, comm);
break;
case 1:
MPI_Bcast(buf2, count, type, 1, comm);
MPI_Bcast(buf1, count, type, 0, comm);
break;
}
Предполагается, что группа comm есть {0,1}. Два процесса выполняют две операции широковещания в обратном порядке. Если операция синхронизирующая, произойдет взаимоблокирование.
Коллективные операции должны быть выполнены в одинаковом порядке во всех элементах группы.
Пример 4.24 Следующий отрезок программы неверен.
switch(rank) {
case 0:
MPI_Bcast(buf1, count, type, 0, comm0);
MPI_Bcast(buf2, count, type, 2, comm2);
break;
case 1:
MPI_Bcast(buf1, count, type, 1, comm1);
MPI_Bcast(buf2, count, type, 0, comm0);
break;
case 2:
MPI_Bcast(buf1, count, type, 2, comm2);
MPI_Bcast(buf2, count, type, 1, comm1);
break;
}
Предположим, что группа из comm0 есть {0,1}, группа из comm1 - {1, 2} и группа из comm2 - {2,0}. Если операция широковещания синхронизирующая, то имеется циклическая зависимость: широковещание в comm2 завершается только после широковещания в comm0 ; широковещание в comm0 завершается только после широковещания в comm1 ; и широковещание в comm1 завершится только после широковещания в comm2. Таким образом, возникнет дедлок.
Коллективные операции должны быть выполнены в таком порядке, чтобы не было циклических зависимостей.
Пример 4.25 Следующий отрезок программы неверен.
switch(rank) {
case 0:
MPI_Bcast(buf1, count, type, 0, comm);
MPI_Send(buf2, count, type, 1, tag, comm);
break;
case 1:
MPI_Recv(buf2, count, type, 0, tag, comm, status);
MPI_Bcast(buf1, count, type, 0, comm);
break;
}
Процесс ноль выполняет широковещательную рассылку (bcast), сопровождаемую блокирующей посылкой данных (send). Процесс один выполняет блокирующий прием (receive), который соответствует посылке с последующей широковещательной передачей, которая соответствует широковещательной операции процесса ноль. Такая программа может вызвать дедлок. Операция широковещания на процессе ноль может вызвать блокирование, пока процесс один не выполнит соответствующее широковещаельную операцию, так что посылка не будет выполняться. Процесс ноль будет неопределенно долго блокироваться на приеме и в этом случае никогда не выполнится операция широковещания.
Относительный порядок выполнения коллективных операций и операций парного обмена должен быть таким, чтобы даже в случае синхронизации не было дедлока.
Пример 4.26 Правильная, но недетерминированная программа.
switch(rank) {
case 0:
MPI_Bcast(buf1, count, type, 0, comm);
MPI_Send(buf2, count, type, 1, tag, comm);
break;
case 1:
MPI_Recv(buf2, count, type, MPI_ANY_SOURCE,
tag, comm, status);
MPI_Bcast(buf1, count, type, 0, comm);
MPI_Recv(buf2, count, type, MPI_ANY_SOURCE,
tag, comm, status);
break;
case 2:
MPI_Send(buf2, count, type, 1, tag, comm);
MPI_Bcast(buf1, count, type, 0, comm);
break;
}
Все три процесса учавствуют в широковещании (broadcast). Процесс 0 посылает сообщение процессу 1 после операции широковещания, а процесс 2 посылает сообщение процессу 1 перед операцией широковещания. Процесс 1 принимает данные перед и после операции широковещания, с произвольным номером процесса-отправителя.
У этой программы существует два возможных варианта выполнения, с разными соответствиями между отправлением и получением, как показано на рисунке 4.10. Заметим, что второй вариант выполнения имеет специфический эффект, заключающийся в том, что посылка, выполненная после операции широковещания, получена в другом узле перед операцией широковещания.
![\includegraphics[width=5.64in,height=3.49in]{Ch4figure8.eps}](img44.png)
Наличие гонок в этом примере делает соответствие посылок и приемов неоднозначным. Не следует рассчитывать на синхронизацию от широковещания.
Этот пример показывает, что нельзя полагаться на специфические эффекты синхронизации. Программа, которая работает правильно только тогда, когда выполнение происходит по первой схеме (только когда операция широковещания выполняет синхронизацию) неверна.
В заключение отметим, что в многопоточных реализациях можно получить на процессе более, чем одну параллельно выполняемую операцию коллективного обмена. В таких ситуациях пользователь должен гарантировать, что тот же самый коммуникатор не используется одновременно двумя разными коллективными операциями, вызываемых из одного и того же процесса.
Совет разработчикам: Предположим, что операция широковещания выполнена на основе парных обменов MPI. Предположим также, что выполняются следующие два правила:
Тогда сообщения, принадлежащие к последовательным операциям широковещания, не могут быть перемешаны, поскольку сохраняется порядок сообщений парного обмена.
Чтобы гарантировать, что сообщения парного обмена не перемешаны с
коллективными сообщениями, нужно всякий раз, когда коммуникатор создан,
также создавать ``скрытый коммуникатор'' для коллективного обмена.
Очевидно можно достичь подобного эффекта проще, например, используя
скрытую отметку или контекстный бит, чтобы указать, используется ли коммуникатор
для парного обмена или для коллективной коммуникации.[]
Стандарт описывает:
В этом разделе рассматриваются средства MPI для поддержки разработки параллельных библиотек. Параллельные библиотеки необходимы для того, чтобы скрыть сложности, свойственные реализациям ключевых алгоритмов, и обеспечить их корректность. Читатель может получить дополнительную информацию по написанию библиотек в MPI в [26] и [3].
Для создания устойчивых параллельных библиотек интерфейс MPI должен обеспечить:
Кроме того, необходим унифицированный механизм или объект для удобного обозначения контекста обмена, группы обменивающихся процессов, для размещения абстрактного обозначения процесса и сохранения созданных пользователем средств.
Для поддержки библиотек MPI обеспечивает:
Коммуникаторы [16,24,27] создают область для всех операций обмена в MPI. Коммуникаторы разделяются на два вида: интра-коммуникаторы (внутригрупповые коммуникаторы), предназначенные для операций в пределах отдельной группы процессов, и интер-коммуникаторы (межгрупповые коммуникаторы), предназначенные для обменов между двумя группами процессов.
Кэширование. Коммуникаторы обеспечивают механизм ``кэширования'', который позволяет связывать с коммуникаторами новые атрибуты на равных правах со встроенными в MPI механизмами. Это может понадобится опытным пользователям, например, чтобы поддерживать функции виртуальной топологии, описанные в главе 6.
Группы. Группы определяют упорядоченную выборку процессов по именам. Таким образом, группы определяют область для парных и коллективных обменов. В MPI группы могут управляться отдельно от коммуникаторов, но в операциях обмена могут использоваться только коммуникаторы.
Интра-коммуникаторы. Обычно наиболее используемые средства для передачи сообщений в MPI - это интра-коммуникаторы. Интра-коммуникаторы содержат образец группы, контексты парных и коллективных обменов, а также допускают включение виртуальной топологии и других атрибутов. Эти свойства означают следующее:
Совет пользователям: Обычно в библиотеках обмена имеется уникальная предопределенная область, включающая все процессы, которые становятся доступными во время инициализации параллельной программы; процессы имеют последовательные номера. Участники парных обменов задаются их номерами; коллективный обмен (такой, как широковещание) всегда вовлекает все процессы. Эта область является коммуникатором с предопределенным в MPI именем MPI_COMM_WORLD. Пользователи, которым достаточно этого коммуникатора, могут использовать его везде, где требуется аргумент коммуникатора.[]
Интер-коммуникаторы. Пока что обсуждение относилось к обмену в пределах группы. MPI также поддерживает обмен между двумя неперекрывающимися группами. Когда приложение состоит из нескольких параллельных модулей, удобно позволить одному модулю связываться с другими, используя локальные номера для адресации в пределах второго модуля. Это особенно удобно в вычислительной системе клиент-сервер, где клиент или сервер имеют параллельную организацию. Поддержка межгрупповых обменов также обеспечивает механизм для расширения MPI до динамической модели, где не все процессы предраспределяются во время инициализации. Межгрупповая связь поддерживается объектами, называемыми интер-коммуникаторами. Эти объекты связывают две группы вместе с коммуникационными контекстами, которые разделяются обеими группами.
Свойства интер-коммуникаторов таковы:
MPI обеспечивает механизмы для создания и управления интер-коммуникаторами. Пользователи, которые в своих приложениях не нуждаются в межгрупповой связи, могут игнорировать это расширение.
В этом разделе дается более формальное определение концепций, представленных выше.
Группа есть упорядоченный набор идентификаторов процессов; процессы есть зависящие от реализации объекты. Каждый процесс в группе связан с целочисленным номером. Нумерация является непрерывной и начинается с нуля. Группы представлены скрытыми объектами группы, и, следовательно, не могут быть непосредственно переданы от одного процесса к другому. Группа используется в пределах коммуникатора для описания участников коммуникационной области и ранжирования этих участников путем предоставления им уникальных имен.
Имеется специальная предопределенная группа: MPI_GROUP_EMPTY, которая является группой без членов. Предопределенная константа MPI_GROUP_NULL является значением, используемым для ошибочных дескрипторов группы.
Совет пользователям: Константу MPI_GROUP_EMPTY, которая является правильным дескриптором для пустой группы, не следует путать с константой MPI_GROUP_NULL, которая дескриптором не является.[]
Совет разработчикам: Группа может быть представлена таблицей перевода номеров процессов в адреса. Каждый объект коммуникатора может иметь указатель на такую таблицу.
Простые реализации MPI будут нумеровать группы, как они представлены в таблице. Однако, когда нужно улучшить масштабируемость и использование памяти при большом количестве процессов, имеют смысл более продвинутых структур данных. В MPI возможны такие реализации.[]
Контекст есть свойство коммуникаторов, которое позволяет разделять пространство обмена. Сообщение, посланное в одном контексте, не может быть получено в другом контексте. Более того, там, где это разрешено, коллективные операции независимы от ждущих операций парного обмена. Контексты не являются явными объектами MPI; они проявляются только как часть реализации коммуникаторов.
Совет разработчикам: Различные коммуникаторы в одном и том же процессе имеют различные контексты. В сущности, контекст - это управляемый системой признак (или признаки), необходимый для обеспечения безопасности внутри коммуникатора для парного и коллективного обмена. Безопасность означает, что коллективный и парный обмен в пределах одного коммуникатора не смешиваются, и что обмены по различным коммуникаторам также не смешивается.
Возможной реализацией контекста является дополнительный тэг, подключаемый к сообщениям при посылке, и сопоставляемый при получении. Каждый интра-коммуникатор сохраняет значения двух cвоих тэгов (один для парного и другой для коллективного обменов).
Аналогично, в межгрупповой связи (которая является строго парной), каждый коммуникатор хранит значения двух cвоих тэгов: один используется группой A для отправки и группой B для приема; второй используется группой B для отправки и группой A для приема.
Так как контексты не являются явными объектами, то возможны и другие их реализации[]
Интра-коммуникаторы объединяют концепции группы и контекста. Для поддержки оптимизации, зависящей от реализации, и прикладных топологий (определенных в главе 6), коммуникаторы также могут ``кэшировать'' дополнительную информацию (см. раздел 5.7). Операции обмена в MPI используют коммуникаторы для определения области, в которой должны выполняться парная или коллективная операция.
Каждый коммуникатор содержит группу правильных участников; эта группа всегда участвует в локальном процессе. Источник и адресат сообщения определяются номером процесса в пределах этой группы.
Для коллективной связи интра-коммуникатор определяет набор процессов, которые участвуют в коллективной операции (и их порядок, когда это существенно). Таким образом, коммуникатор ограничивает ``пространственную'' область коммуникации, и обеспечивает машинно-независимую адресацию процессов их номерами.
Интра-коммуникаторы являются скрытыми интра-коммуникаторными обьектами и, следовательно, не могут быть непосредственно переданы от одного процесса к другому.
Начальный для всех процессов интра-коммуникатор MPI_COMM_WORLD создается сразу при обращении к функции MPI_INIT.
Предопределенная константа MPI_COMM_NULL есть значение, используемое для неверных дескрипторов коммуникатора.
В реализации MPI со статической моделью обработки коммуникатор MPI_COMM_WORLD имеет одинаковое значение во всех процессах. В реализации MPI, где процессы могут порождаться динамически, возможен случай, когда процесс начинает вычисления, не имея доступа ко всем другим процессам. В таких ситуациях MPI_COMM_WORLD является коммуникатором, включающим все процессы, с которыми подключающийся процесс может немедленно связаться. Поэтому, MPI_COMM_WORLD может одновременно иметь различные значения в различных процессах.
Все реализации MPI должны обеспечить наличие коммуникатора MPI_COMM_WORLD. Он не может быть удален во время существования процесса. Группа, соответствующая этому коммуникатору, не появляется как предопределенная константа, но к ней можно обращаться, используя MPI_COMM_GROUP. MPI не определяет соответствия между номером процесса в MPI_COMM_WORLD и его (машинно-зависимым) абсолютным адресом.
Возможны также другие, зависящие от реализации, предопределенные коммуникаторы.
Этот раздел описывает управление группами процессов в MPI. Операции управления являются локальными и их выполнение не требует межпроцессного обмена.
![\includegraphics[width=4.93in,height=1.65in]{Chapter51.eps}](img52.png)
![\includegraphics[width=5.44in,height=2.78in]{Ch4figure6.eps}](img27.png)