"Автор LZ4 представил новый быстрый и эффективный алгоритм сж..."
 Вариант для распечатки Вариант для распечатки |
Пред. тема | След. тема | ||
| Форум Разговоры, обсуждение новостей | |||
|---|---|---|---|
| Изначальное сообщение | [ Отслеживать ] | ||
| "Автор LZ4 представил новый быстрый и эффективный алгоритм сж..." | +2 +/– | |
| Сообщение от opennews (ok), 25-Янв-15, 10:31 | ||
Ян Колле (Yann Collet), автор эталонной реализации алгоритма LZ4 (https://en.wikipedia.org/wiki/LZ4_%28compression_algori...), | ||
| Ответить | Правка | Cообщить модератору | ||
| Оглавление |
| Сообщения | [Сортировка по ответам | RSS] |
| 1. Сообщение от Fracta1L (ok), 25-Янв-15, 10:31 | +15 +/– | |
> он не рассчитан на достижение рекордных скоростей, свойственных LZMA и ZPAQ, или максимальных уровней сжатия, обеспечиваемых в LZ4 | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Ответы: #10 | ||
| 2. Сообщение от Аноним (-), 25-Янв-15, 10:37 | –5 +/– | |
То есть алгоритм не годится ни для одной конкретной задачи) | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Ответы: #3 | ||
| 3. Сообщение от anon9 (?), 25-Янв-15, 10:55 | +12 +/– | |
Вполне себе годится: на моих данных (логи в JSON-формате) жмёт по объёму так же как gzip -6, но при этом в 7.6 раза быстрее. По-моему очень достойный результат | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #2 Ответы: #12 | ||
| 4. Сообщение от Baz (?), 25-Янв-15, 11:35 | +/– | |
алгоритм, который среднячек во всём. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Ответы: #5 | ||
| 5. Сообщение от Tyuiop (?), 25-Янв-15, 11:43 | +5 +/– | |
Предпочтёшь свербыстрый алгоритм, который почти не жмёт? Или отлично сжимающий, но результата ждать неделю на современном железе? | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #4 Ответы: #16 | ||
| 6. Сообщение от Аноним (-), 25-Янв-15, 12:01 | +1 +/– | |
<сарказм>Все сжимаю в tar. Почему в тесте его нет? | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Ответы: #7, #17 | ||
7.
Сообщение от Michael Shigorin (ok), 25-Янв-15, 12:07 (ok), 25-Янв-15, 12:07
| +11 +/– | |
> <сарказм>Все сжимаю в tar. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #6 Ответы: #8 | ||
| 8. Сообщение от A.Stahl (ok), 25-Янв-15, 12:13 | +3 +/– | |
Ну если упаковывается множество мелких файлов, то можно сэкономить за счёт более рационального использования кластеров. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #7 Ответы: #9 | ||
| 9. Сообщение от ALex_hha (ok), 25-Янв-15, 12:20 | –2 +/– | |
> Ну если упаковывается множество мелких файлов, то можно сэкономить за счёт более рационального использования кластеров. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #8 Ответы: #11, #14 | ||
| 10. Сообщение от Аноним (-), 25-Янв-15, 12:32 | +9 +/– | |
А что ждать? | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #1 Ответы: #35, #40 | ||
| 11. Сообщение от Crazy Alex (ok), 25-Янв-15, 13:21 | +8 +/– | |
А теперь представь, что файлы по десятку байт и не неси фигню. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #9 Ответы: #13 | ||
| 12. Сообщение от funny_falcon (?), 25-Янв-15, 13:56 | +1 +/– | |
А lz4 как при этом жмёт? Т.е. понятно, что размер сжатого файла будет несколько больше, но на сколько? и во сколько раз быстрее он сожмёт? | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #3 Ответы: #19 | ||
| 13. Сообщение от Аноним (-), 25-Янв-15, 14:33 | +1 +/– | |
Если это не FAT какой-нибудь, то данные короткого файла лежат в метаданных, вместе с прочими атрибутами. Не занимает он ни одного кластера. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #11 Ответы: #20 | ||
| 14. Сообщение от Ня (?), 25-Янв-15, 14:37 | +1 +/– | |
Даже если результат меньше оригинала на два бита, то это уже сжатие. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #9 | ||
| 15. Сообщение от Аноним (-), 25-Янв-15, 14:49 | +1 +/– | |
ждем в 7зип ? | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Ответы: #29, #60 | ||
| 16. Сообщение от Аноним (-), 25-Янв-15, 15:05 | +10 +/– | |
>Предпочтёшь свербыстрый алгоритм, который почти не жмёт? Или отлично сжимающий, но результата ждать неделю на современном железе? | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #5 | ||
| 17. Сообщение от Аноним (-), 25-Янв-15, 15:08 | +1 +/– | |
> <сарказм>Все сжимаю в tar. Почему в тесте его нет? | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #6 | ||
| 18. Сообщение от Etch (?), 25-Янв-15, 15:43 | +3 +/– | |
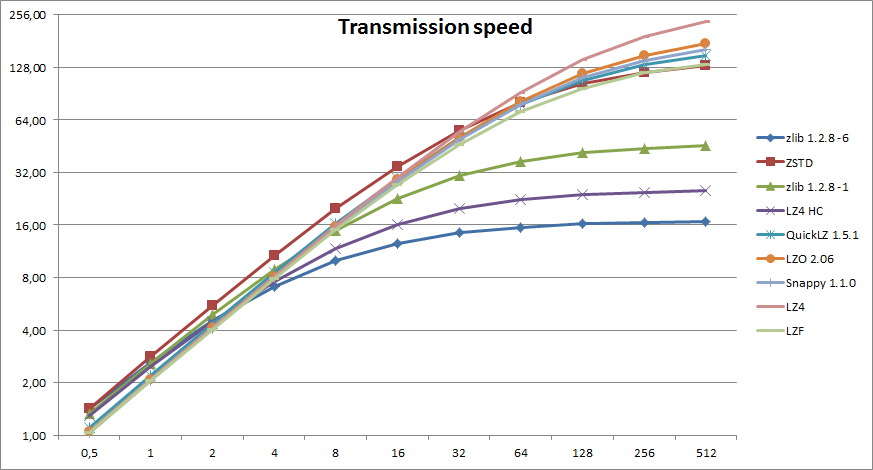
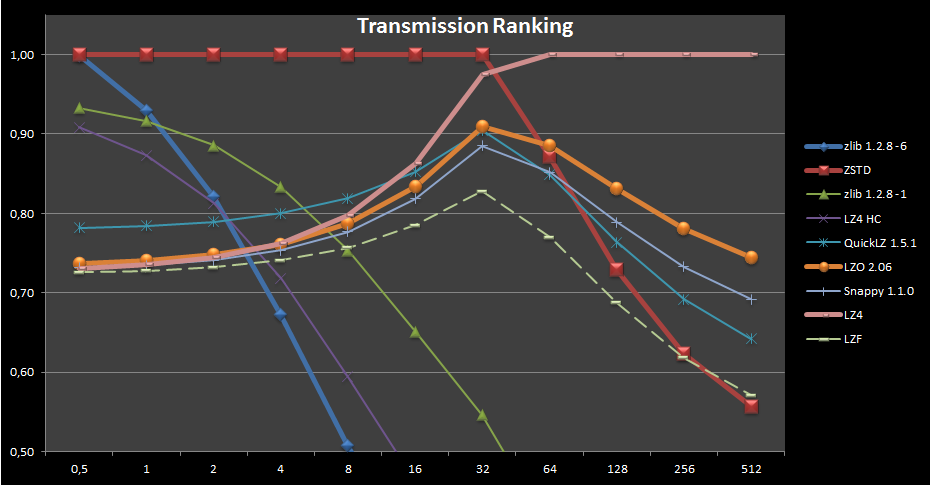
> Первый рафик показывает соотношение времени выполнения операции (ось Y) к пропускной способность канала связи в Мб/сек (ось X). | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| 19. Сообщение от Stax (ok), 25-Янв-15, 16:00 | +/– | |
Судя по таблице вверху, lz4 сожмет не быстрее, а в несколько раз медленнее. И хуже. Но - разжиматься потом будет быстрее. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #12 Ответы: #22 | ||
| 20. Сообщение от Crazy Alex (ok), 25-Янв-15, 16:01 | +1 +/– | |
Минимум - inode + directory record. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #13 Ответы: #21 | ||
| 21. Сообщение от Crazy Alex (ok), 25-Янв-15, 16:06 | +1 +/– | |
Кстати, в ext4 inline data - это экспериментальная фича. В продакшне её нет. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #20 Ответы: #23, #36 | ||
| 22. Сообщение от tyuiop (?), 25-Янв-15, 16:18 | +3 +/– | |
Есть lz4 hc, и есть просто lz4. Вглядись. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #19 | ||
| 23. Сообщение от tyuiop (?), 25-Янв-15, 16:20 | +1 +/– | |
А те, кто пользуются reiser3, используют notail. Быстрее и стабильней. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #21 Ответы: #27, #30 | ||
| 27. Сообщение от Ne01eX (??), 25-Янв-15, 19:39 | –1 +/– | |
Это для наоборот. Опция даёт прирост в скорости в ущерб вместимости (- ~5%). | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #23 Ответы: #28 | ||
| 28. Сообщение от Ne01eX (??), 25-Янв-15, 19:42 | +/– | |
Кстати, Reiser4 умеет танцевать деревья для экономии дискового пространства. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #27 Ответы: #42 | ||
| 29. Сообщение от Мандаринос (?), 25-Янв-15, 19:55 | +/– | |
А зачем он там, если lzma жмет эффективней при сравнимой скорости? | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #15 Ответы: #59 | ||
| 30. Сообщение от Crazy Alex (ok), 25-Янв-15, 20:20 | –1 +/– | |
А те, кто пользуются reiserfs - ищут грабли. начиная с риска угробить ФС к чертовой матери изаканчивая суровым падением скорости вследствеи фрагментации. Если, конечно, за последнюю пару лет что-то радикально не улучшилось, но не припомню такого. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #23 Ответы: #32 | ||
| 32. Сообщение от Ne01eX (??), 25-Янв-15, 21:05 | +/– | |
>>А те, кто пользуются reiserfs - ищут грабли. начиная с риска угробить ФС к чертовой матери изаканчивая суровым падением скорости вследствеи фрагментации. Если, конечно, за последнюю пару лет что-то радикально не улучшилось, но не припомню такого. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #30 Ответы: #33 | ||
| 33. Сообщение от Crazy Alex (ok), 25-Янв-15, 22:05 | +/– | |
Для начала - речь шла о reiserfs. Сейчас вы говорите о reiser4. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #32 Ответы: #39 | ||
| 34. Сообщение от AlexAT (ok), 25-Янв-15, 23:19 | +1 +/– | |
Хотелось бы ZSTD в TokuDB увидеть... Самое оно. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Ответы: #55 | ||
| 35. Сообщение от Аноним (-), 26-Янв-15, 03:52 | +4 +/– | |
А смысл этой возни? Там уже есть вполне сравнимый LZO, вот никто и не рвется особо имплементить еще 1 почти такой же алгоритм. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #10 | ||
| 36. Сообщение от Аноним (-), 26-Янв-15, 03:53 | +/– | |
> Кстати, в ext4 inline data - это экспериментальная фича. В продакшне её нет. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #21 Ответы: #54 | ||
| 37. Сообщение от Анонимко (?), 26-Янв-15, 08:28 | +/– | |
А в MySQL до сих пор только zlib, только в innodb и, по сути, размер всё равно больше, чем у несжатой myisam... | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Ответы: #38, #44 | ||
| 38. Сообщение от AlexAT (ok), 26-Янв-15, 08:46 | +3 +/– | |
> А в MySQL до сих пор только zlib, только в innodb и, | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #37 Ответы: #43, #51 | ||
| 39. Сообщение от Ne01eX (??), 26-Янв-15, 09:17 | +3 +/– | |
Хорошо, встанем тогда на том, что это хорошо когда у людей есть выбор, какой ФС пользоваться в GNU/Linux. =) | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #33 Ответы: #41, #50 | ||
| 40. Сообщение от Аноним (-), 26-Янв-15, 11:49 | –1 +/– | |
Почитай про checkinstall хотя бы, болезный. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #10 | ||
| 41. Сообщение от Crazy Alex (ok), 26-Янв-15, 15:20 | –1 +/– | |
А тут и спорить не с чем. Сейчас, насколько я понимаю, в моде экстенты, но, вероятно, Рейзер сумел бы их со своей архитектурой подружить. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #39 Ответы: #49, #53 | ||
| 42. Сообщение от Stax (ok), 26-Янв-15, 15:20 | +/– | |
"Dancing Tree" это как бы название структуры данных, а не "танец" каких-то других типов деревьев. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #28 Ответы: #52 | ||
| 43. Сообщение от Аноним (-), 26-Янв-15, 18:32 | +/– | |
Ага, и использовать двиг, который занимает в 7 раз больше места? ( http://www.percona.com/forums/questions-discussions/mysql-an... ). Боже упаси. Я не проверял, но что-то верится с трудом что innodb при таком оверхеде может быть быстрее myisam. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #38 Ответы: #46 | ||
| 44. Сообщение от Аноним (-), 26-Янв-15, 18:40 | –1 +/– | |
Порекомендуйте идеальную СУБД? | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #37 Ответы: #45, #47 | ||
| 45. Сообщение от Мандаринос (?), 26-Янв-15, 18:43 | +/– | |
Не успел я написать слово "Oracle", как у моего комментария уже был минус :) | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #44 | ||
| 46. Сообщение от AlexAT (ok), 26-Янв-15, 20:36 | +/– | |
> Ага, и использовать двиг, который занимает в 7 раз больше места? ( | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #43 | ||
| 47. Сообщение от AlexAT (ok), 26-Янв-15, 20:38 | +/– | |
> Порекомендуйте идеальную СУБД? | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #44 Ответы: #48 | ||
| 48. Сообщение от Аноним (-), 27-Янв-15, 02:34 | +2 +/– | |
> Порекомендуйте идеальный автомобиль. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #47 | ||
| 49. Сообщение от Аноним (-), 27-Янв-15, 02:48 | +/– | |
> как по мне - это на порядок большее надругательство над линуксовой | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #41 | ||
| 50. Сообщение от Аноним (-), 27-Янв-15, 02:51 | –1 +/– | |
> включения в основную ветвь, со временем, код reiserfs v.3 стал отлаженным | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #39 | ||
| 51. Сообщение от Анонимко (?), 27-Янв-15, 10:08 | +/– | |
Я рад за вас, у меня таблицы при переводе на innodb разрастаются в 5 раз. Лично я по этому параметру вижу регресс, myisam по тестам оказывается гораздо быстрее. Еслиб еще к этому двигу прикрутили сжатие и построчную блокировку, - myisam бы обходил innodb на порядки. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #38 | ||
| 52. Сообщение от Ne01eX (ok), 27-Янв-15, 19:28 | +/– | |
> "Dancing Tree" это как бы название структуры данных, а не "танец" каких-то | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #42 | ||
| 53. Сообщение от Аноним (-), 27-Янв-15, 21:18 | –1 +/– | |
Проснись, тормоз. В РСУБД экстенты в моде уже больше 30 лет - ты столько на свете не прожил. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #41 | ||
| 54. Сообщение от Аноним (-), 27-Янв-15, 21:18 | –1 +/– | |
>> Кстати, в ext4 inline data - это экспериментальная фича. В продакшне её нет. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #36 Ответы: #56 | ||
| 55. Сообщение от Аноним (-), 27-Янв-15, 21:19 | +/– | |
> Хотелось бы ZSTD в TokuDB увидеть... Самое оно. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #34 | ||
| 56. Сообщение от AlexAT (ok), 27-Янв-15, 21:45 | +1 +/– | |
> В ZFS это есть уже лет 8. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #54 Ответы: #57 | ||
| 57. Сообщение от iZEN (ok), 29-Янв-15, 01:12 | +/– | |
>> В ZFS это есть уже лет 8. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #56 Ответы: #58 | ||
| 58. Сообщение от AlexAT (ok), 29-Янв-15, 08:28 | +/– | |
Не используется. В топку. | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #57 | ||
| 59. Сообщение от Vic (??), 09-Сен-15, 10:54 | +1 +/– | |
А можно подробнее про большую скорость lzma? | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #29 | ||
| 60. Сообщение от мяя (?), 27-Ноя-19, 11:53 | +/– | |
https://github.com/mcmilk/7-Zip-zstd | ||
| Ответить | Правка | Наверх | Cообщить модератору | ||
| Родитель: #15 | ||
|
Архив | Удалить |
Рекомендовать для помещения в FAQ | Индекс форумов | Темы | Пред. тема | След. тема |



{kind=link}
{kind=link}
{kind=link}
{kind=link}