 |
Использование LTTng для прозрачной трассировки приложений в Ubuntu Linux (доп. ссылка 1) |
[комментарии]
|
| | Система трассировки LTTng (http://lttng.org/) работает на уровне Linux-ядра и
отличается минимальным влиянием на работу профилируемого приложения, что
позволяет приблизить условия работы данного приложения к его выполнению без
использования трассировки (например, позволяет выявлять проблемы с
производительностью в программах, работающих в реальном режиме времени).
Поддержка LTTng пока не включена в состав Linux-ядра, но недавно для Ubuntu
Linux был подготовлен специальный PPA-репозиторий, позволяющий значительно
упростить установку LTTng.
Приведем пример использования LTTng для отладки системы и тюнинга производительности.
Подключаем репозиторий:
sudo add-apt-repository ppa:lttng/ppa
sudo aptitude update
Устанавливаем компоненты для трассировки ядра (LTTng работает только с ядром
2.6.35, поэтому в Ubuntu 10.04 может потребоваться установка экспериментального
пакета с более новым ядром):
sudo apt-get install lttng
Установка утилит для трассировки пользовательских приложений:
sudo apt-get install ust-bin libust-dev liburcu-dev
Пример поддержи трассировки на уровне ядра
Загружаем ядро lttng:
sudo ltt-armall
Начинаем трассировку:
sudo lttctl -C -w /tmp/trace1 программа
Прекращаем трассировку:
sudo lttctl -D программа
Результаты трассировки /tmp/trace1 теперь можно открыть в утилите lttv или
использовать режим текстового дампа:
lttv -m textDump -t /tmp/trace1 | grep ...
Трассировка пользовательских приложений со связыванием специальной библиотеки
Собираем приложения добавив в опции сборки флаг '-lust'.
Запускаем приложение с трассировкой:
usttrace исследуемая_программа
Контроль трассировки с удаленной машины
На локальной машине устанавливаем и запускаем программу-агент:
sudo apt-get install tcf-lttng-agent
sudo tcf-agent
На удаленной машине устанавливаем и запускаем клиента:
sudo apt-get install tcf-lttng-client
tcf-client
далее, в появившейся консоли вводим:
connect ip_локальной_машины
и после соединения передаем управляющие команды:
tcf ltt_control getProviders
tcf ltt_control setupTrace "kernel" "0" "traceTest"
Пример трассировки
Рассмотрим для примера простую программу, открывающую файл и записывающую в него циклично числа.
#include <stdio.h>
#define INT_MAX 2147483647
int main(volatile int argc, char **argv) {
int i = 3;
FILE *fd = fopen("test.out", "w");
fwrite(&i, sizeof(int), 1, fd);
fclose(fd);
volatile long a;
int x;
for (x = 0; x<INT_MAX; x++) {
a++;
}
return 0;
}
Собираем данную программу:
gcc -o usecase usecase.c
Теперь попробуем выполнить трассировку при помощи LTTng.
Активируем точки трассировки в ядре:
sudo ltt-armall
Для автоматизации выполнения активации трассировки, запуска программы и
остановки трассировки напишем небольшой скрипт trace-cmd.sh:
#!/bin/sh
if [ -z "$@" ]; then
echo "missing command argument"
exit 1
fi
cmd="$@"
name="cmd"
dir="$(pwd)/trace-$name"
sudo rm -rf $dir
sudo lttctl -o channel.all.bufnum=8 -C -w $dir $name
echo "executing $cmd..."
$cmd
echo "return code: $?"
sudo lttctl -D $name
Запускаем:
./trace-cmd.sh ./usecase
После выполнения трассировки для наглядного анализа результатов запускаем
GUI-утилиту lttv-gui, заходим в меню File->Add и выбираем директорию
трассировки "trace-имя", сохраненную в каталоге, в котором был запущен скрипт
trace-cmd.sh. Каждое из событий трассировки представлено в виде графика. Для
нашего тестового приложения будет присутствовать три фазы: создание/доступ к
файлу, вычислительная фаза и завершение процесса.
Оценка различий от strace
Если сравнить результаты работы стандартной утилиты strace:
strace -o usecase.strace ./usecase
В дополнение к системным вызовам, LTTng учитывает задействование подсистем
ядра, события планировщика задач, обработку прерываний и прочие детали,
недоступные в выводе strace. Но самым интересным отличием от strace является
то, что программа никаким образом не может определить, что подвергается
трассировке. Время наступления событий отображается в наносекундах. Влияние на
производительность трассировки минимально, тестирование показало, что работа
замедляется не более чем на 3%.
|
| |
 |
|
|
Как подружить plPlot и wxWidgets под ОС Windows |
Автор: KoD
[комментарии]
|
| | 0) Введение.
Данный материал рассчитан на начинающих программистов, в частности, студентов,
которым поможет избежать огромного количества подводных камней, таящихся на
пути к использованию этих мощных программных продуктов.
0.1) wxWidgets
В сети очень много материала про данную библиотеку, поэтому отмечу здесь только
основной плюс, что она не имеет лицензионных ограничений в отличие от
аналогичного продукта в виде библиотеки Qt, и позволяет легко писать свободное
и коммерческое ПО любому желающему.
Со всей богатой документацией можно ознакомиться на официальном сайте.
0.2) plPlot
plPlot так же является свободно распространяемой (LGPL) библиотекой,
предназначенной для построения графиков функций в 2х-мерном и 3х-мерном
пространствах, различных видов и форм.
В связке с библиотекой wxWidgets дает практически неограниченные возможности по
визуализации данных в различных областях применения, от систем мониторинга до
финансовых приложений, калькуляторов и расчетных систем.
Ссылка на официальный сайт.
Обе библиотеки распространяются в виде исходного кода, а значит на OS Windows,
необходимо будет их собрать и скомпилировать при помощи утилиты CMake и
компилятора gcc из пакета MinGW32.
На момент написания статьи самые свежие версии необходимого ПО были:
CMake - 3.12.4;
Mingw BASE-bin - 2013072200, gcc-c++ - 6.3.0-1;
wxWidgets - 3.0.4 Stable;
plPlot - 5.13.0;
IDE code::Blocks - 17.12;
Рекомендую использовать именно данную конфигурацию для более предсказуемого результата.
1) Установка утилит и компиляторов
1.1)Cmake
Качаем установщик в соответствии с разрядностью своей операционной системы
x32
x64
Запускаем..., далее..., далее..., после установки необходимо добавить в
переменную %PATH% путь к каталогу "CMake\\bin\\", в
стандартной установке это "C:\\Program
Files\\CMake\\bin", сделать это можно через
Пуск/ Панель управления/ Система/ Дополнительные параметры/ Переменные среды.
1.2) MinGW32
На официальном сайте забираем утилиту "MinGW Installation Manager
(mingw-get)" из раздела "Downloads". Запускаем ее и в открывшемся окне через
правую кнопку мыши отмечаем для установки пакеты "mingw32-base-bin"
и "mingw32-gcc-g++-bin", затем в меню "Installaton" жмем
на "Apply Changes" и дожидаемся установки всех пакетов.
В случае сбоя недостающие библиотеки можно докачать с репозитория MinGW на sourceforge.net.
Нужно убедиться в том, что установилась библиотека
"MinGW\\lib\\libgdiplus.a" и заголовочный файл "MinGW\\include\\gdiplus.h".
Так же добавляем путь к каталогу "bin\\" в переменную
%PATH%, в стандартной установке это "C:\\MinGW\\bin"
2) Установка библиотеки wxWidgets
На сайте библиотеки в разделе Downloads качаем установочный файл с
исходными текстами и распаковываем.. Путь по-умолчанию будет в корне диска
"c:\\wxWidgets-3.0.4\\", и желательно, чтобы он не содержал
кириллицы и пробелов.
Перед установкой редактируем файл
"wxWidgets-3.0.4\\include\\wx\\msw\\setup.h", меняем
в нем переменную wxUSE_GRAPHIC_CONTEXT=0 на 1 для всех
компиляторов. Затем копируем этот "setup.h" в каталог "wxWidgets-3.0.4\\include\\wx\\"
По невыясненным причинам компилятор выдает ошибку при сборке библиотеки, чтобы
ее избежать редактируем "MinGW\\include\\stdio.h".
Нужно закомментировать строку 345:
// extern int __mingw_stdio_redirect__(snprintf)(char*, size_t, const char*, ...);
Далее, нужно открыть командную строку через Пуск-Выполнить - cmd
В командной строке:
cd c:\\wxWidgets-3.0.4\\build\\msw
mingw32-make -f makefile.gcc SHARED=1 UNICODE=1 BUILD=release MONOLITHIC=0
Компиляция обычно занимает до получаса, в результате в каталоге
"wxWidgets-3.0.4\\lib\\gcc_dll" дожны появиться бинарные файлы
библиотек. Можно идти далее...
3) Установка библиотеки plPlot
Качаем исходники с офциального сайта, распаковываем во временный каталог
"c:\\Temp\\" или другой,
но только не в корень диска, так как там, в результате, будет бинарная сборка.
Для успешной компиляции необходимо произвести следующие действия:
Скопировать из "wxWidgets-3.0.4\\lib\\gcc_dll\\"
файлы "wxbase30u_gcc_custom.dll" и
"wxmsw30u_core_gcc_custom.dll" в каталог "Temp\\plplot-5.13.0\\dll\\"
Отредактировать
"Temp\\plplot-5.13.0\\drivers\\wxwidgets_dev.cpp" строку
под номером 647 rand_s(&m_seed); и привести ее к виду:
m_seed = rand();
Сохранить файл.
В командной строке Windows cmd:
cd c:\\Temp\\plplot-5.13.0\\
cmake -G "MinGW Makefiles" -DCMAKE_INSTALL_PREFIX=c:\\plplot\\ -DENABLE_wxwidgets=ON -DPLD_wxwidgets=ON
Необходимо убедиться в отсутствии ошибок и что переменные установлены верно:
.... a lot of output ....
wxWidgets_FOUND=TRUE
.... a lot of output ....
ENABLE_wxwidgets=ON
Если что-то пошло не так, нужно выяснить причину, удалить каталог
"CMakeFiles\\" и файл "CMakeCache.txt" и запустить CMake повторно.
Опять переходим в командную строку:
mingw32-make
Дожидаемся успешной компиляции и в cmd от имени Администратора:
cd c:\\Temp\\plplot-5.13.0\\
mingw32-make install
После указанных действий появляется каталог
"c:\\plplot\\" c бинарной сборкой библиотеки и
заголовочными файлами.
4) Установка среды разработки приложений Code::Blocks
Здесь особых нюансов не предвидется. Качаем C::B с официального сайта,
запускаем установщик и убеждаемся, что система увидела
компилятор.
Запускаем IDE с рабочего стола двойным щелчком.
5) Проба пера: "Hello, World!"
На начальном экране Code::Blocks нажимаем "Create New Project", в выпадающем
списке "Category"->"GUI", нажать "new wxWidgets Project".
В диалоге нужно выбрать версию wxWidgets-3.0.x, далее, директорию проекта и
название, имя автора, далее установить буллеты:
Preferred GUI Builder - [o]wxSmith
Application type - [o]Frame based
далее, "wxWidgets location" - "c:\\wxWidgets-3.0.4" , далее, установить
галочки в "wxWidgets library settings":
[V] Use wxWidgets dll
[V] Enable Unicode
Finish.
Раскроется окно GUI-Builder'а wxSmith. Здесь в окне "Management"
переходим во вкладку "Projects" и правым щелчком мыши на названии
проекта в контекстном выбираем "Build options".
Откроется окно "Project build options", на вкладке "Linker
settings" добавляем 3 библиотеки кнопкой "Add" это (одной строкой):
plplot.dll;plplotcxx.dll;plplotwxwidgets.dll;
на вкладке "Search directories":
для "Compiler" добавить "c:\\plplot\\include",
для "Linker" добавить "c:\\plplot\\lib".
5.1) Можно приступить к программированию..
В дереве проекта открываем файл "Headers - Main.h" и добавляем заголовки:
#include <wx/dc.h>
#include <wx/dcclient.h>
#include <wx/dcmemory.h>
#include <plplot/wxPLplotstream.h>
В секции private класса Фрейма пишем:
private:
int w, h;
wxBitmap bmp;
wxMemoryDC mdc;
wxPLplotstream pls;
Открываем файл "Sources - Main.cpp" и в теле конструктора Фрейма
testFrame::testFrame(wxWindow* parent,wxWindowID id) после служебного кода вставляем:
GetSize(&w, &h);
bmp.Create( w, h, -1 );
mdc.SelectObject(bmp);
if(! pls.IsValid()){
pls.Create((wxDC*)&mdc, w, h, wxPLPLOT_NONE);
}
const int NSIZE = 80;
PLFLT x[NSIZE], y[NSIZE];
x[0] = (-1) * NSIZE/4;
y[0] = x[0] * x[0];
for(int i=1; i < NSIZE; i++){
x[i] = x[i - 1] + 0.5;
y[i] = x[i] * x[i];
}
pls.env(-20., 20., -10., 100, 0, 1);
pls.width(2);
pls.col0(3);
pls.line(NSIZE, x, y);
Затем, необходимо в окне "Management" на вкладке "Resources" открыть wxSmith,
выделить главное окно и создать обработчик события EVT_PAINT в
разделе "{}" Events. Функция автоматически называется "OnPaint".
В ее теле вводим код:
void testFrame::OnPaint(wxPaintEvent& event)
{
int width, height;
GetSize( &width, &height );
height = height;
// Check if we window was resized (or dc is invalid)
if((w != width) || (w != height) ) {
w = width;
h = height;
mdc.SelectObject( wxNullBitmap );
bmp.Create(w,h, mdc);
mdc.SelectObject(bmp);
pls.SetSize( width, height );
pls.replot();
Refresh(false);
}
wxPaintDC dc(this);
dc.Blit(0,0,w,h,(wxDC*)&mdc,0,0);
}
Для запуска приложения потребуются бинарники всех библиотек, так что копируем
из "wxWidgets-3.0.4\\lib\\gcc_dll\\" файлы
"wxbase30u_gcc_custom.dll" и "wxmsw30u_core_gcc_custom.dll", из
"plplot\\bin" все 5 dll файлов и из
"plplot\\lib\\plplot5.13.0\\drivers" файл
"wxwidgets.dll" в каталог проекта "bin\\Debug", туда, где будет собран
основной .exe файл.
Итого, минимальный список библиотек:
libcsirocsa.dll
libplplot.dll
libplplotcxx.dll
libplplotwxwidgets.dll
libqsastime.dll
wxwidgets.dll
wxmsw30u_gcc_custom.dll
wxmsw30u_core_gcc_custom.dll
Теперь можно спокойно собрать проект и запустить бинарный файл. в итоге
получается такая симпатичная парабола.
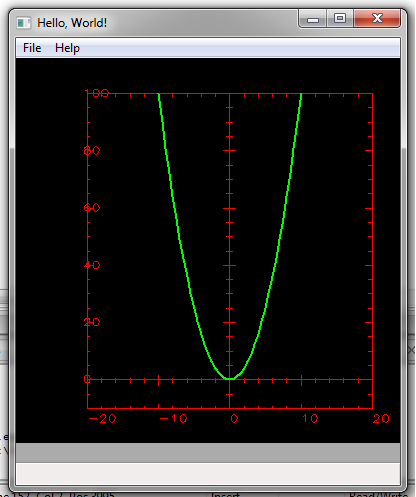 По вопросам сборки библиотек, прошу обращаться на почту автора xsrc@mail.ru.
По вопросам сборки библиотек, прошу обращаться на почту автора xsrc@mail.ru.
|
| |
|
|
|
Ускорение пересборки llama.cpp (доп. ссылка 1) |
Автор: Аноним
[комментарии]
|
| | При работе с llama.cpp имеется постоянная необходимость её пересобирать, так
как в отличие от ONNX Runtime GGUF-файлы не хранят сериализованный граф
вычислений, вместо этого процедура инференса вручную кодится в C++-коде, и за
счёт применения информации, которую в ONNX обычно не сериализуют (ONNX обычно
экспортируется автоматически, но знания можно туда встроить, если закодировать
конструирование ONNX-графа вручную), может быть достигнута большая
эффективность (по потреблению ресурсов) инференса.
Это приводит к тому, что для того, чтобы исполнять модель на llama.cpp
необходимы усилия программистов. В большинстве случаев каждая новая модель
обладает уникальной архитектурой, и в большинстве случаев её поддержка кодится
в проект сотрудниками компании-разработчика самой модели, если компания
нуждается в продвижении своих моделей (зачастую такие модели распространяются
под проприетарной лицензией, запрещающей коммерческое использование без
заключения договора, при этом они закрывают некоторые потребности тех, кому
нужен экономичный к ресурсам инференс).
Так как структура проекта не подразумевает динамической загрузки отдельно
собираемой разделяемой библиотеки с архитектурой модели, то при добавлении
моделей или возможностей приходится пересобирать весь проект. Это обосновано,
так как архитектура проекта и его API не являются стабильными и код одной
реализации модели переиспользуется в другой.
Однако проект имеет некоторые проблемы. Которые, впрочем, "никому" "не мешают",
так как нейросети (стереотипно "тяжёлое" приложение, не смотря на то, что
существуют мелкие нейросети размером в несколько мебибайт) запускать на
"калькуляторе", "обогревателе" и "музейном хламе со свалки" никто "в здравом
уме" (со слов "здравомыслящих") не будет. Проблемы заключаются в том, что
проект долго компилируется и долго линкуется, и при этом имеет тенденцию
требовать пересборки и перелинковки при малейших вроде-бы безобидных
изменениях, вроде изменения переменной "CMAKE_INSTALL_LIBDIR". Я
проанализировал и исправил некоторые, но не все, причины подобного поведения.
Причины заключаются в том, что в проекте использованы приёмы, являющиеся
антипаттернами, которые было бы неплохо разобрать, чтобы вы так не делали.
1. Проект полагается на пару больших заголовочных файлов. Почти любое
функциональное изменение требует модификации этих заголовочных, а любая их
модификация приводит к полной перекомпиляции проекта. Это не то, что мы можем
поправить парой патчей, это требует изменений в процессах.
2. Проект имеет в нескольких местах "add_library(${TARGET} STATIC". Это
приводит к тому, что некоторые куски кода линкуются статически в некоторые
другие куски кода. Это, конечно, должно приводить к более быстрому коду при
линковке с LTO, но линковка с LTO тот ещё тормоз, а инструментов в проекте
мнооогооо, и никто и не задавался вопросом, нужна ли конкретно вон там
максимальная производительность, достигаемая инлайном и стиранием границы между
модулями, или всё же heavy lifting у нас делает GGML, и основная часть
вычислений жрётся инференсом, а оптимизация консольной обёртки вокруг GGML даст
очень немного.
При этом хардкод STATIC а равно SHARED является антипаттерном, так как в
проектах на CMake это решение принимается теми людьми, кто исходник собирает в
бинарники, и выставляется через стандартную переменную CMake
"BUILD_SHARED_LIBS". Поэтому целесообразно там стереть STATIC, и при
"set(BUILD_SHARED_LIBS ON)" это нам срежет время линковки. Поскольку библтотеки
теперь могут быть SHARED, добавляем их установку (патч).
3. В проекте присутствует код
cmake
target_compile_definitions(ggml-base PRIVATE
GGML_VERSION="${GGML_INSTALL_VERSION}"
GGML_COMMIT="${GGML_BUILD_COMMIT}"
)
При этом "GGML_BUILD_COMMIT" и "GGML_INSTALL_VERSION" динамически генерятся при
запуске CMake. "ninja" автоматически определяет, какие объектные файлы
нуждаются в перекомпиляции, и изменение аргументов вызова компилятора - это
показание к перекомпиляции. Что приводит к тому, что при любом коммите
"ggml-base" пересобирается полностью, а линкующие его бинари -
перелинковываются, а от "ggml-base" транзитивно зависит почти весь проект.
Указанные макроопределения используются ровно в одних местах - в реализациях
методов, возвращающих указанные значения, дальнейший доступ к этим значениям
идёт исключительно через методы. Имеет смысл вынести указанные методы в
отдельную библиотеку. Линковать я её бы, разумеется, предпочёл бы в
соответствии с "BUILD_SHARED_LIBS", но так как смысл этих методов - быть
прибитыми к файлу библиотеки ggml-base гвоздями, то вот тут как раз хардкодим "STATIC"
(патч).
4. В проекте присутствует
cmake ()
target_compile_definitions(ggml PUBLIC GGML_BACKEND_DIR="${GGML_BACKEND_DIR}")
, при этом макроопределение "GGML_BACKEND_DIR" за пределами библиотеки "ggml"
не используется. Использование "PUBLIC" приводит к тому, что все бинари,
которые линкуют "ggml", получат в командной строке вызова своего компилятора
это определение. Соответственно, если вы потрогаете эту переменную, то это
приведёт к почти полной перекомпиляции проекта. При этом это макроопределение
используется в коде ровно в одном месте:
"search_paths.push_back(fs::u8path(GGML_BACKEND_DIR));", и поэтому "PUBLIC"
нужно смело менять на "PRIVATE".
По-хорошему путь вообще не должен хардкодиться, а должен определяться
относительно бинарей. В проекте используется поиск в директории бинарей, но
путь относительно неё не конфигурируется, а задание "GGML_BACKEND_DIR"
используется для того, чтобы shared-библиотеки бэкендов легли не в "/usr/bin".
Подход в некоторой степени странный. Логичнее сделать конфигурируемым путь
относительно директории бинарника, тогда при изменении префикса пересобирать
библиотеку не придётся, ибо относительный путь останется тем же (патч).
5. В директории "common" в "CMakeLists.txt" есть кусочек
cmake
set(TEMPLATE_FILE "${CMAKE_CURRENT_SOURCE_DIR}/build-info.cpp.in")
set(OUTPUT_FILE "${CMAKE_CURRENT_BINARY_DIR}/build-info.cpp")
configure_file(${TEMPLATE_FILE} ${OUTPUT_FILE})
set(TARGET build_info)
add_library(${TARGET} OBJECT ${OUTPUT_FILE})
, где файл шаблона
c++
int LLAMA_BUILD_NUMBER = @LLAMA_BUILD_NUMBER@;
char const *LLAMA_COMMIT = "@LLAMA_BUILD_COMMIT@";
char const *LLAMA_COMPILER = "@BUILD_COMPILER@";
char const *LLAMA_BUILD_TARGET = "@BUILD_TARGET@";
Проблема такого решения в том, что при каждом запуске CMake пересоздаётся файл
"${OUTPUT_FILE}", а от него уже транзитивно зависят все инструменты, что
приведёт к их перелинковке. Ninja не считает хеши файлов, он определяет
изменения файлов по атрибутам уровня файловой системы, за хешами - к "ccache".
В то же время Ninja отслеживает изменения в командной строке компилятора по
контенту, поэтому в данном случае предпочтительнее не пересоздавать файл
исходного кода, а использовать макроопределения. Ещё я заменил OBJECT на
STATIC. OBJECT в CMake поддерживается не особо официально, долгое время он был
вообще недокументированой внутренней возможностью, о которой, тем не менее, все
знали, и по-прежнему ломается в очень многих случаях (патч).
6. В бэкэндах, связанных с OpenCL, с помощью питоньего скрипта генерятся
заголовочные файлы с хардкодом исходного кода OpenCL-ядер. Во-первых это
трогает файлы при каждом запуске CMake, что приведёт к пересборке, во-вторых
данную проблему можно решить исключительно с помощью CMake, использование
Python здесь излишне. В-третьих хардкод ядер в бинарник - это антипаттерн. У
них есть опция ядра не хардкодить, но они забыли их установить!
7. "common" сливает в одну либу кучу всякой всячины, часть из которой которая
нужна далеко не во всех инструментах, а часть нужна абсолютно во всех, напр.
управление контекстом, и вебсервер и парсинг аргументов командной строки в
конфиг, и контролируемая генерация - всё собрано в этой библиотеке,
превращённой в монструозную помойку размером в 37 мегабайт отстрипанных,
которая до наших патчей ещё статически линковалась в каждый инструмент. В
результате изменение вещи нужной для меньшинства инструментов приводит к
перелинковке всех инструментов.
8. Ещё имеет смысл запачить сборку ненужных бэкендов (она не настраивается
гибко, и не мне это исправлять).
===
Другие патчи исправляют ошибки и добавляют улучшения, обсуждать их не имеет
смысла, так как с антипаттернами, влияющими на скорость сборки, они не связаны.
Апстрим всех патчей, как всегда, на вас, все что можно идёт под Unlicense (но
содержат код, производный от оригинала под MIT), можете вообще от своего имени.
Единственное, что надо отметить: вы не можете просто взять и переместить
библиотеки в другую директорию, как это сделано в Дебиане, из-за ошибки CMake:
https://gitlab.kitware.com/cmake/cmake/-/issues/22621 . Дело в том, что по
факту CMake не поддерживает установку библиотек в какие-либо директории,
которые и так не находятся в RPATH, потому что машинерия CMake, которая патчит
RPATH в бинарях при установке, не пытается собирать RPATH из путей установки
линкуемых библиотек.
Соответственно все библиотеки и приложения, которые залинковали библиотеку,
устанавливаемую не в место по умолчанию, её не найдут. В CMake нет опции,
позволяющей это поправить, все опции, которые вы можете нагуглить для верси 4.2
делают другие вещи. Это определённо баг, так как функциональность установки
CMake вместе с CPack должна собирать работоспособные пакеты, а место установки
- оно определяется не в скрипте сборки, а собирающим.
Можно данную проблему поправить на уровне костыльного CMake-кода, ставящего
RPATH вручную, если он не совпадает с "CMAKE_INSTALL_LIBDIR", но определённо
это должно не так работать, и в этом проекте для этого придётся править код
каждого инструмента, скорее всего апстрим такое не примет.
В Дебиане проблему решают (см.
https://salsa.debian.org/deeplearning-team/llama.cpp и
https://salsa.debian.org/deeplearning-team/ggml.git ) собирая GGML из
отдельного репозитория (что в общем-то было бы правильно, но...), и для каждого
вызова CMake вручную ставя RPATH в "debian/rules", но проблема в том, что
отдельный репозиторий для GGML теперь не является основным, а основной "ggml"
живёт в репозитории llama.cpp и иногда синхронизируется в ggml-евский и
"whisper.cpp" копированием кода ("whisper.cpp" давно пора удалить, так как
поддержка новых мультимодальных моделей (включая модели для TTS и ASR)
завозятся в "llama.cpp"). Это неправильно и грязно, но это не мне решать, раз
разрабам llama так удобно - то пусть в монорепе держат. Но в таком случае
по-хорошему репозиторий "ggml" не мешало бы либо просто удалить, чтобы сломать
всем скрипты сборки и делом довести до сведения, откуда надо теперь ggml
ставить, либо заменить на CMake скрипт, использующий "FetchProject". А пока
есть шанс, что в Дебиане llama будет слинкована с неподходящим ggml.
Все патчи можно скачать единым архивом. Архив имеет 2 директории, в одной
патчи для ускорения пересборки, а в другой - другие патчи, исправляющие
некоторые проблемы и потенциальные проблемы в скриптах сборки, и имеющие
некоторое отношение к пакетированию. Желателен апстрим всех. Ещё желателен
рефактор ggml-части с разносом файлов исходников по директориям.
|
| |
|
|
|
Создание программ под SynapseOS |
Автор: Арен Елчинян
[комментарии]
|
| | Пример создания приложения "Hello World", используя clang и сисфункцию вывода для
SynapseOS.
Перед написанием любой программы нужно установить средства сборки.
В Ubuntu:
sudo apt install llvm lld
Далее перейдём к теории.
Сисфункции в SynapseOS вызываются через прерывание 0x80.
Регистры сисфункций:
eax - номер сисфункций
ebx - параметр 1
edx - параметр 2
ecx - параметр 3
esi - параметр 4
edi - параметр 5
ebp - параметр 6
В eax также идёт результат выполнения.
Пример вызова сисфункции:
mov eax, 42 ; Получаем количество тиков
int 80h ; Вызов прерывания
Нас интересует сисфункция под номером 0 - вывод строки в консоль.
На языке С это выглядит так:
int print_str(char *str) {
uint32_t result = 0;
asm volatile("int $0x80"
: "=a"(result) // result = eax (после выполнения)
: "a"(SC_CODE_puts), // eax = SC_CODE_puts(0)
"b"(str) // ebx = str
);
return result;
}
int main() {
return print_str("Hello world!\\n");
}
Результат:
Hello world!
На ассемблере FASM:
; Hello World - FASM
format ELF
public main
main:
mov eax, 0 ; 0 - сисфункция
mov ebx, hello ; параметры сисфункции
int 80h
ret
hello db 'Hello world!\\n',0
Результат:
Hello world!
|
| |
|
|
|
Тестирование хелловорлда под 17 платформ одним скриптом |
Автор: Урри
[комментарии]
|
| | В заметке рассказано как собрать и, главное, запустить и протестировать свой
хелловорлд сразу под 17 платформ (29 вариантов сборки, так как почти каждая
платформа идёт в двух вариантах: libc и musl) не создавая зоопарк виртуалок.
Все желаемое осуществляется с помощью сборочного инструментарий void-linux, за
что им огромное спасибо - работа проделана огромная.
Итак, что нам надо:
Linux, любой (я использую Mint),
Git (им будем ставить инструментарий для сборки исходных текстов),
20+ ГБ на диске (у меня выделенный SSD, хотя все равно долго получается).
fuse-overlayfs
proot
qemu-static
Все остальное автоматически доставится в процессе.
Шаг 1: настройка основной среды.
Этот шаг полностью описан в совете "Сборка и тестирование хелловорлда под 17
платформ одним скриптом" по ссылке https://www.opennet.ru/tips/3193_build_compile_test_arm_mips_x86_powerp.shtml
Там же описана сборка. Следующие шаги предполагают, что шаг 1 проделан и все
функционирует без ошибок.
Шаг 2: установка fuse-overlayfs и proot
В Linux Mint это производится с помощью "sudo apt install fuse-overlayfs proot".
fuse-overlayfs нам нужен для того, чтобы не захламлять сборочный
инструментарий. Мы будем "накладывать" ваш собранный хелловорлд (и все что с
ним, вы же не только один бинарный файл будете собирать?) поверх рабочей
файловой системы.
proot нам нужен для создания рута (/), в котором и будет работать наша эмуляция всяких arm и mips.
Шаг 3: qemu.
Ставим qemu, причём нам нужны статически скомпонованные исполняемые файлы, так
как мы их будем запускать в отдельном руте, не имеющем доступа к любым
библиотекам хоста.
Для тестирования всех платформ нам нужны будут вот эти: qemu-aarch64-static,
qemu-arm-static, qemu-i386-static, qemu-mipsel-static, qemu-mips-static,
qemu-ppc64le-static, qemu-ppc64-static, qemu-ppc-static, qemu-x86_64-static.
В Linux Mint они ставятся с помощью "sudo apt install qemu-user-static".
Шаг 4: пути.
Создаём каталог "testing" прямо в нашем рабочем окружении (куда вы клонировали
void-packages, у меня этот каталог так и называется - "void-packages"). Не
будем выносить сор из избы. В этом каталоге заводим временные подкаталоги для
fuse-overlayfs. Я их назвал по платформам (aarch64, armv5tel, armv7hf-musl, и т.д.)
Полный список не даю - мы их будем автоматически создавать в скрипте.
Шаг 5: скрипт.
Создаём вот такой, немного увесистый скрипт (ну уж извините - платформ много,
под каждую надо кое-что захардкодить) в том же рабочем каталоге
("void-packages"). Я назвал его "script.sh".
Пара комментариев к скрипту (они же есть и в коде скрипта):
1. Очистка обязательна. Некоторые платформы между собой конфликтуют и без
очистки у вас вполне возможно бинарник не запустится.
2. В скрипте считается, что ваша поделка инсталлируется как
/usr/bin/helloworld. Если это не так - поправьте скрипт под себя.
3. Обязательно обратите внимание на то, что версия нашего хелловорлда -
"1.0". Это вписано в предыдущем совете. Если версия у вас уже другая -
поменяйте путь в скрипте (найдёте его поиском).
Запускать скрипт как: "$ script.sh armv7l"
#!/bin/bash
[ -z "$1" ] && exit
export PATH=$PATH:`pwd`/xbps/usr/bin
arch=$1
folder() {
case $1 in
aarch64-musl)
echo aarch64-linux-musl;;
aarch64)
echo aarch64-linux-gnu;;
armv5tel-musl)
echo arm-linux-musleabi;;
armv5tel)
echo arm-linux-gnueabi;;
armv5te-musl)
echo arm-linux-musleabi;;
armv5te)
echo arm-linux-gnueabi;;
armv6hf-musl)
echo arm-linux-musleabihf;;
armv6hf)
echo arm-linux-gnueabihf;;
armv6l-musl)
echo arm-linux-musleabihf;;
armv6l)
echo arm-linux-gnueabihf;;
armv7hf-musl)
echo armv7l-linux-musleabihf;;
armv7hf)
echo armv7l-linux-gnueabihf;;
armv7l-musl)
echo armv7l-linux-musleabihf;;
armv7l)
echo armv7l-linux-gnueabihf;;
i686-musl)
echo i686-linux-musl;;
i686)
echo i686-pc-linux-gnu;;
mipselhf-musl)
echo mipsel-linux-muslhf;;
mipsel-musl)
echo mipsel-linux-musl;;
mipshf-musl)
echo mips-linux-muslhf;;
mips-musl)
echo mips-linux-musl;;
ppc64le-musl)
echo powerpc64le-linux-musl;;
ppc64le)
echo powerpc64le-linux-gnu;;
ppc64-musl)
echo powerpc64-linux-musl;;
ppc64)
echo powerpc64-linux-gnu;;
ppcle-musl)
echo powerpcle-linux-musl;;
ppcle)
echo powerpcle-linux-gnu;;
ppc-musl)
echo powerpc-linux-musl;;
ppc)
echo powerpc-linux-gnu;;
x86_64-musl)
echo x86_64-linux-musl;;
esac
}
qemu() {
case $1 in
aarch64-musl)
echo qemu-aarch64-static;;
aarch64)
echo qemu-aarch64-static;;
armv5tel-musl)
echo qemu-arm-static;;
armv5tel)
echo qemu-arm-static;;
armv5te-musl)
echo qemu-arm-static;;
armv5te)
echo qemu-arm-static;;
armv6hf-musl)
echo qemu-arm-static;;
armv6hf)
echo qemu-arm-static;;
armv6l-musl)
echo qemu-arm-static;;
armv6l)
echo qemu-arm-static;;
armv7hf-musl)
echo qemu-arm-static;;
armv7hf)aarch64-linux-musl
echo qemu-arm-static;;
armv7l-musl)
echo qemu-arm-static;;
armv7l)
echo qemu-arm-static;;
i686-musl)
echo qemu-i386-static;;
i686)
echo qemu-i386-static;;
mipselhf-musl)
echo qemu-mipsel-static;;
mipsel-musl)
echo qemu-mipsel-static;;
mipshf-musl)
echo qemu-mips-static;;
mips-musl)
echo qemu-mips-static;;
ppc64le-musl)
echo qemu-ppc64le-static;;
ppc64le)
echo qemu-ppc64le-static;;
ppc64-musl)
echo qemu-ppc64-static;;
ppc64)
echo qemu-ppc64-static;;
ppcle-musl)
echo qemu-ppc-static;;
ppcle)
echo qemu-ppc64le-static;;
ppc-musl)
echo qemu-ppc-static;;
ppc)
echo qemu-ppc-static;;
x86_64-musl)
echo qemu-x86_64-static;;
esac
}
ROOT=`pwd`/testing/$arch
# qemu.
# на этом шаге мы копируем бинарник qemu в наш будущий рут, чтобы fuse-overlayfs могла его не только найти, но и спокойно запустить
[ -s `pwd`/masterdir/usr/$(folder $arch)/$(qemu $arch) ] || cp `which $(qemu $arch)` `pwd`/masterdir/usr/$(folder $arch)
echo -----------------------------------------------------------------------------------------------------
echo $arch
# обязательно почистим сборку
./xbps-src -a $arch clean helloworld
# собираем. детали в прошлом совете
./xbps-src -a $arch -C pkg helloworld || exit $?
echo -- package built, lets install them -----------------------------------------------------------------
# создаём временный каталог для fuse-overlayfs
[ -d "$ROOT" ] || mkdir "$ROOT"
# накладываем собранный (и заинсталлированный тулчейном во внутренний каталог) хелловорлд на новый рут тестируемой платформы
# 1.0 - версия сборки вашего пакета. детали в предыдущем совете.
sleep 1
fuse-overlayfs \\
-o lowerdir=`pwd`/masterdir/usr/$(folder $arch) \\
-o upperdir=`pwd`/masterdir/destdir/$(folder $arch)/helloworld-1.0 \\
-o workdir=$ROOT \\
$ROOT
echo -- testing ------------------------------------------------------------------------------------------
# а вот и само тестирование - тут ваш хелловорлд для проверки может, например, сделать `system("uname -a");`
# /usr/bin/helloworld - путь, куда инсталлируется по умолчанию ваша поделка
sleep 1
proot -R $ROOT /$(qemu $arch) /usr/bin/helloworld
# вот мой вывод, например: "Linux ___ 5.4.0-99-generic #112-Ubuntu SMP Thu Feb 3 13:50:55 UTC 2022 armv7l"
echo -- done ---------------------------------------------------------------------------------------------
# и, конечно же, надо прибрать за собой.
sleep 1
fusermount -u $ROOT
Шаг 6: последний - автоматизация.
Делаем ещё один, финальный скрипт. Его же и дёргаем когда хотим проверить не
сломали ли мы что-то в очередной раз своим новым кoдoм.
for arch in x86_64-musl \
aarch64-musl aarch64 \
armv5tel-musl armv5tel armv5te-musl armv5te armv6hf-musl armv6hf armv6l-musl armv6l armv7hf-musl armv7hf armv7l-musl armv7l \
i686-musl i686 \
mipselhf-musl mipsel-musl mipshf-musl mips-musl \
ppc64le-musl ppc64le ppc64-musl ppc64 \
ppcle-musl ppcle \
ppc-musl ppc
do
./script.sh $arch
done
Все.
Надеюсь, эта вполне несложная автоматизация поможет вам овладеть действительно
мультиплатформенным кодингом.
|
| |
|
|
|
Sonatype Nexus как Maven proxy (доп. ссылка 1) |
Автор: ACCA
[комментарии]
|
| | При попытке установить, например,
com.google.protobuf:protoc:exe:linux-x86_64:2.6.1, получаете ошибку:
Return code is: 400, ReasonPhrase: Detected content type [application/x-executable], but expected [application/x-dosexec]: com/google/protobuf/protoc/2.6.1/protoc-2.6.1-linux-x86_64.exe
В настройке репозитория maven2(proxy) есть незаметная галочка "Validate that
all content uploaded to this repository is of a MIME type appropriate for the
repository format".
Её выключение решает проблему, так как Nexus и Maven Central по-разному назначают MIME type.
|
| |
|
|
|
Запись бинарных данных в секцию ELF |
Автор: 赤熊
[комментарии]
|
| | Стоит задача - в программе запрятать бинарные данные. Допустим архив.
Создаём файл data.cpp для включения запланированных для добавления данных:
volatile char a[DATASIZE] __attribute__((section(".her"))) = {0xfa};
Таким образом мы обозначаем намерения создать переменную в отдельной секции.
Далее компилируем data.cpp в object-файл data.o:
g++ -c -g data.cpp
Смотрим shed-адрес секции. И производим заливку согласно предустановленному
размеру переменной "a". На моём компьютере это выглядит так:
dd if=out.tar of=data.o bs=1 count= seek=52 conv=notrunc
Архив, либо бинарник конечно предварительно может быть зашифрован, дабы
избежать лишних посягательств. Дальнейшую сборку программы можно сделать Make
файлом, но я решил написать командами для наглядности процесса:
g++ -c -g main.cpp
g++ -g -o test main.o data.o
Альтернативный вариант от посетителя maneken:
__asm(
".global data_file\n"
".global _data_file\n"
"data_file:\n"
"_data_file:\n"
".incbin \"data.zip\"\n"
".global data_file_len\n"
".global _data_file_len\n"
"data_file_len:\n"
"_data_file_len:\n"
".int .-data_file \n"
);
extern void * data_file;
extern void * data_file_len;
unsigned char * data =(unsigned char *)&data_file;
int * datalen =(int *) &data_file_len;
|
| |
|
|
|
Оценка стоимости сборки Android 5 (x86-64) на облачных серверах Amazon EC2 (доп. ссылка 1) |
Автор: Abylay Ospan
[комментарии]
|
| | Краткая сводка по результатам тестирования:
сервер 4 CPU, 16GB RAM, время сборки: 04:35:30 стоимость: $1.15
сервер 16 CPU, 64GB RAM, время сборки: 01:12:02 стоимость: $1.21
сервер 40 CPU, 160GB RAM, время сборки: 00:32:15 стоимость: $1.34
По результам видно, что разница в цене всего 15%, но при этом время сборки
уменьшается в 8-9 раз. Сборка проводилась в разное количество потоков (make -j X).
Лучший результат показал вариант 'количество CPU * 2'. Исходные тексты Android
были взяты из репозитория на http://www.android-x86.org/
Сборка проводилась командами:
. build/envsetup.sh && lunch android_x86_64-eng && make -j X
ОС: Ubuntu 14.04.2 LTS, kernel 3.13.0-48-generic x86_64 CPU: Intel(R) Xeon(R)
CPU E5-2676 v3 @ 2.40GHz HDD: SSD 160GB
|
| |
|
|
|
Как собрать в новом GCC старую C++-программу, использующую iostream.h |
[комментарии]
|
| | В блоках #include следует заменить iostream.h и fstream.h на iostream и fstream
(убрать ".h"). В начало файлов нужно добавить "using namespace std;", а при
сборке в Makefile указать флаг "-fpermissive".
|
| |
|
|
|
Внедрение точек останова gdb в исходный код (доп. ссылка 1) |
Автор: glebiao
[комментарии]
|
| | На github опубликован способ внедрения в исходный код точек останова для
gdb, не влияющий на нормальное выполнение программы в отсутствие отладчика.
Способ основан на размещении адреса локальной переменной в секции
(embed-breakpoints линкера).
#define EMBED_BREAKPOINT \\
asm("0:" \\
".pushsection embed-breakpoints;" \\
".quad 0b;" \\
".popsection;")
int main() {
printf("Hello,\\n");
EMBED_BREAKPOINT;
printf("world!\\n");
EMBED_BREAKPOINT;
return 0;
}
Собираем враппер для gdb:
sudo apt-get install binutils-dev
git clone git://github.com/kmcallister/embedded-breakpoints.git
cd embedded-breakpoints
./build.sh
Собираем тестовое приложение и запускаем под управлением враппера к gdb:
$ gcc -g -o example example.c
$ ./gdb-with-breakpoints ./example
Reading symbols from example...done.
Breakpoint 1 at 0x4004f2: file example.c, line 8.
Breakpoint 2 at 0x4004fc: file example.c, line 10.
(gdb) run
Starting program: example
Hello,
Breakpoint 1, main () at example.c:8
8 printf("world!\\n");
(gdb) info breakpoints
Num Type Disp Enb Address What
1 breakpoint keep y 0x00000000004004f2 in main at example.c:8
breakpoint already hit 1 time
2 breakpoint keep y 0x00000000004004fc in main at example.c:10
При выполнении напрямую и или в версии gdb без специального враппера точки
останова никак не отражаются на работе программы.
|
| |
|
|
|
Создание модуля для iptables, изменяющего ID пакета (доп. ссылка 1) |
Автор: xlise
[комментарии]
|
| | Данная статья основывается на материале "Разработка Match-модуля для iptables
своими руками" (http://www.linuxjournal.com/article/7184), но код работает на
ядрах 2.6.20+.
Мне потребовалось изменить ID IP пакетов, в интернете подходящей инструкции как
это сделать на ядре 2.6.24 я не нашел, из-за этого решил написать, как удалось
решить задачу.
Для реализации задуманного нам понадобится написать модуль ядра, который будет
выполнять проверку и модуль расширения для iptables, который будет работать с
модулем ядра - создавать новые цепочки,
использующие наш модуль, выводить информацию о критерии при выводе списка
правил на экран, а также проверять корректность передаваемых модулю параметров.
Сначала создадим общий заголовочный файл ipt_ID.h:
#ifndef _IPT_ID_H
#define _IPT_ID_H
enum {
IPT_ID_RAND = 0,
IPT_ID_INC
};
#define IPT_ID_MAXMODE IPT_ID_INC
struct ipt_ID_info {
u_int8_t mode;
u_int16_t id;
};
#endif
Теперь скопируем его в исходники netfilter в директорию
linux/netfilter_ipv4/
Далее рассмотрим модуль ядра ipt_ID.с.
#include <linux/module.h>
#include <linux/skbuff.h>
#include <linux/ip.h>
#include <net/checksum.h>
#include <linux/random.h>
#include <linux/netfilter/x_tables.h>
#include <linux/netfilter_ipv4/ipt_ID.h>
MODULE_AUTHOR("Xlise <demonxlise@gmail.com>");
MODULE_DESCRIPTION("Xtables: IPv4 ID field modification target");
MODULE_LICENSE("GPL");
static int count=0;
static struct iphdr l_iph[5];
static unsigned int
id_tg(struct sk_buff *skb, const struct net_device *in,
const struct net_device *out, unsigned int hooknum,
const struct xt_target *target, const void *targinfo)
{
struct iphdr *iph;
const struct ipt_ID_info *info = targinfo;
u_int16_t new_id;
int i=0;
if (!skb_make_writable(skb, skb->len))
return NF_DROP;
iph = ip_hdr(skb);
switch (info->mode) {
case IPT_ID_RAND:
get_random_bytes(&info->id, sizeof(info->id));
new_id = info->id;
break;
case IPT_ID_INC:
while (i<5)
{
if (l_iph[i].daddr == iph->daddr)
{
new_id = l_iph[i].id + htons(1);
l_iph[i].id = new_id;
}
else
{new_id = iph->id;
l_iph[count] = *iph;
count++;
if (count > 4)
count = 0;
}
i++;
}
default:
new_id = iph->id;
break;
}
if (new_id != iph->id) {
csum_replace2(&iph->check, iph->id,
new_id);
iph->id = new_id;
}
return XT_CONTINUE;
}
static bool
id_tg_check(const char *tablename, const void *e,
const struct xt_target *target, void *targinfo,
unsigned int hook_mask)
{
const struct ipt_ID_info *info = targinfo;
if (info->mode > IPT_ID_MAXMODE) {
printk(KERN_WARNING "ipt_ID: invalid or unknown Mode %u\n",
info->mode);
return false;
}
if (info->mode != IPT_ID_SET && info->id == 0)
return false;
return true;
}
static struct xt_target id_tg_reg __read_mostly = {
.name = "ID",
.family = AF_INET,
.target = id_tg,
.targetsize = sizeof(struct ipt_ID_info),
.table = "mangle",
.checkentry = id_tg_check,
.me = THIS_MODULE,
};
static int __init id_tg_init(void)
{
return xt_register_target(&id_tg_reg);
}
static void __exit id_tg_exit(void)
{
xt_unregister_target(&id_tg_reg);
}
module_init(id_tg_init);
module_exit(id_tg_exit);
Напишем Makefile для нашего модуля:
obj-m := ipt_ID.o
KDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
$(MAKE) -C $(KDIR) M=$(PWD) modules
добавим модуль в ядро
insmod ipt_ID.ko
Для создания модуля для iptables нам потребуются исходники для iptables-1.4.4
Создадим файл libipt_ID.c
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <getopt.h>
#include <xtables.h>
#include <linux/netfilter_ipv4/ipt_ID.h>
#define IPT_ID_USED 1
static void ID_help(void)
{
printf(
"ID target options\n"
" --id-rand value Set ID to \n"
" --id-inc value Increment ID by \n");
}
static int ID_parse(int c, char **argv, int invert, unsigned int *flags,
const void *entry, struct xt_entry_target **target)
{
struct ipt_ID_info *info = (struct ipt_ID_info *) (*target)->data;
u_int16_t value;
if (*flags & IPT_ID_USED) {
xtables_error(PARAMETER_PROBLEM,
"Can't specify ID option twice");
}
if (!optarg)
xtables_error(PARAMETER_PROBLEM,
"ID: You must specify a value");
if (xtables_check_inverse(optarg, &invert, NULL, 0))
xtables_error(PARAMETER_PROBLEM,
"ID: unexpected `!'");
if (!xtables_strtoui(optarg, NULL, &value, 0, UINT16_MAX))
xtables_error(PARAMETER_PROBLEM,
"ID: Expected value between 0 and 255");
switch (c) {
case '1':
info->mode = IPT_ID_RAND;
break;
case '2':
if (value == 0) {
xtables_error(PARAMETER_PROBLEM,
"ID: increasing by 0?");
}
info->mode = IPT_ID_INC;
break;
default:
return 0;
}
info->id = value;
*flags |= IPT_ID_USED;
return 1;
}
static void ID_check(unsigned int flags)
{
if (!(flags & IPT_ID_USED))
xtables_error(PARAMETER_PROBLEM,
"TTL: You must specify an action");
}
static void ID_save(const void *ip, const struct xt_entry_target *target)
{
const struct ipt_ID_info *info =
(struct ipt_ID_info *) target->data;
switch (info->mode) {
case IPT_ID_SET:
printf("--id-set ");
break;
case IPT_ID_DEC:
printf("--id-dec ");
break;
case IPT_ID_INC:
printf("--id-inc ");
break;
}
printf("%u ", info->id);
}
static void ID_print(const void *ip, const struct xt_entry_target *target,
int numeric)
{
const struct ipt_ID_info *info =
(struct ipt_ID_info *) target->data;
printf("ID ");
switch (info->mode) {
case IPT_ID_SET:
printf("set to ");
break;
case IPT_ID_DEC:
printf("decrement by ");
break;
case IPT_ID_INC:
printf("increment by ");
break;
}
printf("%u ", info->id);
}
static const struct option ID_opts[] = {
{ "id-set", 1, NULL, '1' },
{ "id-inc", 1, NULL, '2' },
{ .name = NULL }
};
static struct xtables_target id_tg_reg = {
.name = "ID",
.version = XTABLES_VERSION,
.family = NFPROTO_IPV4,
.size = XT_ALIGN(sizeof(struct ipt_ID_info)),
.userspacesize = XT_ALIGN(sizeof(struct ipt_ID_info)),
.help = ID_help,
.parse = ID_parse,
.final_check = ID_check,
.print = ID_print,
.save = ID_save,
.extra_opts = ID_opts,
};
void _init(void)
{
xtables_register_target(&id_tg_reg);
}
Далее скопируем файл ipt_ID.h в iptables-1.4.4/include/linux/netfilter_ipv4/ и
файл libipt_ID.c в iptables-1.4.4/extensions/
теперь скомпилируем iptables и скопируем файл
iptables-1.4.4/extensions/libipt_ID.so в /lib/xtables/
Теперь можно создавать цепочки в iptables
пример:
iptables -t mangle -A POSTROUTING -j ID --id-rand 1
Будет выдавть всем пакетам случайные ID (единица в конце ничего не обозначает
просто я не доделал модуль)
iptables -t mangle -A POSTROUTING -j ID --id-inc 1
Будет пакетам направленным на один IP присваивать ID постоянно увеличивая на
единицу, может хранить в памяти пять таких цепочек (количество цепочек можно увеличить)
P.S. Если кого интересует данная тема, то я доделаю статью и допишу модуль,
просто пока всё работает и так не хочется ничего переделывать, но если нужно сделаю.
|
| |
|
|
|
Как в программе на Си узнать от какого пользователя запущен активный экран |
Автор: pavlinux
[комментарии]
|
| | #include <stdio.h>
#include <stdlib.h>
#include <string.h> // strcmp
#include <utmpx.h>
#define XTTY ":0"
int main(void)
{
struct utmpx *entry;
setutxent();
while ( (entry = getutxent()) != NULL) {
if ( !strcmp(entry->ut_line, XTTY) )
printf("%s %s\n",entry->ut_line, entry->ut_user);
}
endutxent();
return(EXIT_SUCCESS);
}
|
| |
|
|
|
Как указать GCC выводить предупреждения для бессмысленных сравнений (доп. ссылка 1) |
Автор: Kir Kolyshkin
[комментарии]
|
| | При сборке ниже представленного некорректного кода, gcc не выдает никаких
предупреждений даже с -Wall, при этом указатель он приводит к unsigned, поэтому
результат сравнения всегда ложен.
if ((fp = fopen(file, "w")) < 0)
Если написать:
unsigned int a;
if (a < 0)
return 1;
return 0;
gcc опять не ругается и даже с -O0 генерирует код, который не делает никаких
сравнений, а сразу возвращает результат. То есть знает, что сравнение
бессмысленное, но молчит.
Для того, чтобы gcc начал выводить предупреждения нужно указать -Wextra, тогда буде выведено:
warning: comparison of unsigned expression < 0 is always false
Вариант 2 (правильный):
$ gcc -std=c99 -W
|
| |
|
|
|
Изменение номера inode файла в Linux |
Автор: Victor Leschuk
[комментарии]
|
| | Для некоторых специфических целей может понадобиться изменить номер inode у существующего файла,
либо создать файл с заранее заданным номером. Штатными средствами сделать это -
задача нетривиальная,
однако с помощью модуля ядра это несложно.
Создаем файл inode_modify.c следующего содержания:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/version.h>
#include <linux/fs.h>
#include <linux/namei.h>
#ifndef BUF_LEN
#define BUF_LEN 256
#endif
char file[BUF_LEN];
unsigned long new_num=0;
module_param_string( name, file, BUF_LEN, 0);
module_param(new_num, ulong, 0);
struct nameidata nd;
unsigned long get_number() {
int error;
error = path_lookup( file, 0, &nd);
printk( KERN_ALERT "name = %s\n", file);
if(error) {
printk( KERN_ALERT "Can't access file\n");
return -1;
}
#if LINUX_VERSION_CODE >= KERNEL_VERSION(2,6,25)
return nd.path.dentry->d_inode->i_ino;
#else
return nd.dentry->d_inode->i_ino;
#endif
}
unsigned long set_number(unsigned long new_num) {
#if LINUX_VERSION_CODE >= KERNEL_VERSION(2,6,25)
nd.path.dentry->d_inode->i_ino = new_num;
return nd.path.dentry->d_inode->i_ino;
#else
nd.dentry->d_inode->i_ino = new_num;
return nd.dentry->d_inode->i_ino;
#endif
}
int inode_modify_init(){
unsigned long inode_num;
inode_num = get_number();
printk ( KERN_ALERT "Inode number is %lu\n", inode_num);
printk ( KERN_ALERT "New inode number is %lu\n", set_number(new_num));
return 0;
}
void inode_modify_exit(){
printk(KERN_ALERT "Exiting...\n");
}
module_init(inode_modify_init);
module_exit(inode_modify_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Victor Leschuk <Victor.Leschuk@ebanat.com>");
И простой Makefile:
obj-m := inode_modify.o
После чего в директории с модулем:
$ make -C /path/to/kernel/sources SUBDIRS=$PWD modules
Здесь нужно помнить, что исходники и версия gcc должны соответствовать тем,
которые были использованы при сборке используемого ядра.
Далее тестируем модуль:
$ touch /dev/shm/test
$ ls -i /dev/shm/test
172461 /dev/shm/test
$ sudo insmod ./inode_modify.ko name=/dev/shm/test new_num=12345
$ ls -i /dev/shm/test
12345 /dev/shm/test
$ sudo rmmod inode_modify
$ dmesg |tail
name = /dev/shm/test
Inode number is 172461
New inode number is 12345
Exiting...
|
| |
|
|
|
Как отлаживать сетевые скрипты с помощью netcat (доп. ссылка 1) |
Автор: Вячеслав
[комментарии]
|
| | mkdir tmp
cd tmp
mkfifo sock1 sock2
nc -l -p 8000 < sock1 | tee sock2 &
nc 10.245.134.32 23 < sock2 | tee sock1
Теперь вместо того, чтобы устанавливать соединение непосредственно с узлом 10.245.134.32:23,
делаем telnet на localhost:8000 из другой консоли на хосте home и наблюдаем
проходящие данные внутри
tcp-сессии в консоли, где выполняли команды.
Для этой же цели подходит и утилита socat:
socat -v tcp4-l:8000 tcp4:yandex.ru:80
|
| |
|
|
|
Отладка php скриптов на стороне сервера |
Автор: Pavel Piatruk
[комментарии]
|
| | Иногда пользовательские скрипты или зависают, или хотят соединиться с чем-то
запрещенным в файрволе,
или интерпретатор неожиданно вылетает, не передав заголовок Content-type, что
приводит к ошибке 500.
Для того, чтобы разобраться в причине, попробуем отладить скрипты со стороны сервера,
не залезая в код php. Сначала придется изменить конфигурацию apache, чтобы php
работало через suphp,
а не через модуль mod_php5. Я не буду рассказывать, как это делается. Главное, кроме обычного,
"неотладочного", надо добавить свой обработчик в suphp.conf:
x-httpd-php_debug=php:/usr/local/bin/php-cgi.sh
А вот содержимое этого скрипта /usr/local/bin/php-cgi.sh. Поставьте ему права 755.
Видно, что он запускает отладчиком php с перенаправлением отладочной информации в файл.
#!/bin/bash
/usr/bin/strace /usr/bin/php5-cgi $@ 2>/tmp/debug
Не забудьте добавить этот обработчик в конфиг apache , это делается строкой
suPHP_AddHandler x-httpd-php_debug
Затем в .htaccess нужного сайта допишите
AddHandler x-httpd-php_debug .php
В результате после повторной загрузки сайта появится файл /tmp/debug, в который будет добавляться
отладочная информация о работе php нужного сайта. В это время лучше ограничить посещение сайта,
разрешив только 1 IP адрес, чтобы отладочной информации не было чрезмерно.
Обычно будет достаточно имени системного вызова, который приводит к прекращению
выполнения скрипта.
Можно поиграться с параметрами strace.
|
| |
|
|
|
Ускорение компиляции в Gentoo (доп. ссылка 1) |
Автор: wildarcher7
[комментарии]
|
| | В наличии два ПК, на которых установлен Gentoo Linux с одинаковой версией gcc (4.3.1).
Так как компиляция из исходников в Gentoo необходима и компиляция отнимает некоторое время,
хотелось бы сократить время сборки. На помощь приходит distcc и ccache.
Всё описанное ниже нужно проделать на обоих ПК.
emerge distcc ccache #установим distcc и ccache
Две данные строчки появились в данной статье при помощи метода профессора Копи-Пастера:
mv /root/.ccache /root/snafu.ccache
ln -s /var/tmp/ccache /root/.ccache
distcc-config --set-hosts "192.168.0.1 192.168.0.2" #перечислим ip адреса серверов distcc
rc-update add distccd #
/etc/init.d/distccd restart
ccache -M 4G
/etc/conf.d/distccd
DISTCCD_OPTS="${DISTCCD_OPTS} -allow 192.168.0.0/24" #разрешим доступ для подсети
настроим make.conf
FEATURES="ccache distcc"
CCACHE_DIR="/var/tmp/ccache"
CCACHE_SIZE="4G"
DISTCC_HOSTS="192.168.0.1 192.168.0.2"
DISTCC_DIR="/tmp/.distcc"
#DISTCC_VERBOSE="1" #раз комментировать при желании лицезреть подробный отчет о проделанной работе distcc
Источник http://wildarcher7.wordpress.com/
|
| |
|
|
|
VMWare Workstation 6 для отладки ядра Linux (доп. ссылка 1) |
Автор: Тарасенко Николай
[комментарии]
|
| | Недавно была добавлена интересная особенность в Workstation 6.0, которая делает
WS6 отличным средством
для отладки ядра Linux. Теперь можно с легкостью отлаживать Linux VM на хосте при помощи gdb
без каких-либо изменений в Guest VM. Ни каких kdb, перекомпиляций или еще одной
машины не требуется.
Все что вам потребуется, так это всего одна строчка в VM'шном конфигурационном файле.
Чтобы использовать новую особенность, необходимо достать последний билд WS6:
http://www.vmware.com/products/beta/ws/
Разместить в вашем Linux VM конфигурационном файле строчку:
debugStub.listen.guest32=1
Теперь, всякий раз, когда вы запускаете виртуальную машину, Вы будете видеть на хост консоле:
VMware Workstation is listening for debug connection on port 8832.
Запустите gdb на хосте, ссылаясь на ядро, для которого у Вас есть System.map и
присоедините его к виртуальной машине:
% gdb
(gdb) file vmlinux-2.4.21-27.EL.debug
(gdb) target remote localhost:8832
|
| |
|
|
|
Как посмотреть причину генерации core файла в gdb (доп. ссылка 1) |
[комментарии]
|
| | программа - файл рухнувшей программы, собранной с включением отладочной информации
core - файл с core
$ gdb
Указываем файл рухнувшей программы, собранной с включением отладочной информации
(gdb) программа
Указываем файл с core, будет показана причина и строка на которой приложение рухнуло
(gdb) core core
(gdb) info thread
(gdb) info shared
(gdb) info locals
(gdb) info files
(gdb) info variables
(gdb) help info
Смотрим состояние стека до падения
(gdb) backtrace 1
(gdb) backtrace 2
или просто (gdb) backtrace
Указываем номер фрейма который будем смотреть подробнее (показан как #N)
(gdb) frame 0
Смотрим состояние переменных (в примере - result)
(gdb) info locals
(gdb) print result
(gdb) whatis result
Полезно также посмотреть на выполнении какого системного вызова происходит сбой используя программы
strace (http://strace.sourceforge.net), ltrace (для Linux) или ktrace и truss (входят в состав FreeBSD).
|
| |
|
|
|
Как избавиться от линковки GNOME приложения с лишними библиотеками (доп. ссылка 1) |
[комментарии]
|
| | Собираем по умолчанию:
readelf -d /usr/local/bin/gnome-terminal |grep NEEDED | wc -l
52 - требуется 52 библиотеки.
Устанавливаем флаг --as-needed:
export CFLAGS = "-Os -s -Wl,--as-needed"
После пересборки, требуется 21 реально необходимая для работы библиотека.
|
| |
|
|
|
Обобщение используемых моделей ввода/вывода (доп. ссылка 1) |
[обсудить]
|
| | Стратегии организации ввода-вывода:
- Блокируемый I/O - после вызова read/write происходит блокировка до завершения
операции, функция завершается только после принятия или передачи блока данных.
- Неблокируемый I/0 - функция завершается сразу, если данные не были приняты/отправлены
возвращается код ошибки (т.е. нужно вызывать функции I/O в цикле пока не получим
положительный результат).
- Мультиплексирование через select/poll - опрашиваем список состояния сокетов,
перебирая состояния определяем сокеты готовые для приема/передачи.
Главный минус - затраты на перебор, особенно при большом числе неактивных
сокетов.
- select - число контролируемых сокетов ограничено лимитом FD_SETSIZE,
в некоторых случаях лимит обходится пересборкой программы, в других - пересборкой
ядра ОС.
- poll - нет лимита FD_SETSIZE, но менее эффективен из за большего размера передаваемой
в ядро структуры.
- Генерация сигнала SIGIO при изменении состояния сокета (ошибка, есть данные для приема,
или отправка завершена), который обрабатывает обработчик SIGIO.
В классическом виде применение ограничено и трудоемко, подходит больше для UDP.
- Асинхронный I/O - описан в POSIX 1003.1b (aio_open, aio_write, aio_read...),
функция aio_* завершается мгновенно, далее процесс сигнализируется о
полном завершении операции ввода/вывода (в предыдущих пунктах процесс информировался
о готовности прочитать или передать данные, т.е. данные еще нужно было принять или отправить
через read/write, в aio_* процесс сигнализируется когда данные полностью получены и скопированы в локальный буфер).
- Передача данных об изменении состояния сокета через генерацию событий. (специфичные для определенных ОС решения, малопереносимы, но эффективны).
- kqueue - лучшее для FreeBSD, NetBSD. Данные о нескольких событиях могут быть переданы за раз, очень гибкое решение.
- /dev/epoll - лучшее для 2.6 Linux ядра, передача нескольких событий за раз, трудоемкость поддержки /dev/epoll если параллельно в программе поддерживаются другие механизмы нотификации.
- Realtime Signals (F_SETSIG) - лучшее для 2.4 Linux ядра.
- /dev/poll - имеет смысл в Solaris, в Linux реализация недостаточно хороша.
- Ссылки:
|
| |
|
|
|
Как посмотреть какие файлы пытается открыть или выполнить программа |
[комментарии]
|
| | strace -f -o strace.txt -e execve программа
strace -f -o strace.txt -e open,ioctl программа
|
| |
|
|
|
Как посмотреть какие функции системных библиотек используются в программе |
[комментарии]
|
| | nm "объектный или запускной файл"
Для работы nm нужна таблица символов, т.е. нельзя использовать после утилиты
strip или ключа "-s" в gcc.
|
| |
|
|
|
Как пропатчить приложение запускаемое через inetd для определения IP клиента. |
Автор: uldus
[обсудить]
|
| | Си:
struct sockaddr_in addr_name;
socklen_t addr_len;
addr_len = sizeof(addr_name);
bzero(&addr_name, sizeof(addr_name));
if (getpeername(0, (struct sockaddr *)&addr_name, &addr_len) >= 0){
// выводим адрес в printf через inet_ntoa(addr_name.sin_addr)
}
Perl:
use Socket;
my $std_sockaddr = getpeername(STDIN);
my $cur_ipaddr = "0.0.0.0";
if (defined $std_sockaddr){
my ($tmp_port, $tmp_iaddr) = sockaddr_in($std_sockaddr);
$cur_ipaddr = inet_ntoa($tmp_iaddr);
}
|
| |
|
|
|
Какие параметры указать GCC для оптимизации. (доп. ссылка 1) |
[комментарии]
|
| | -O6 - полная оптимизация (по умолчанию часто стоит -O2).
-fomit-frame-pointer -использовать стек для доступа к переменным.
-march=i686 -mcpu=i686 -DARCH=k6 -DCPU=k6 - оптимизация под CPU (586, 686,k5,k6,k7,athlon,pentiumpro).
-ffast-math -funroll-loops
|
| |
|
|
|
|
|
Сборка хелловорлда под 17 платформ одним скриптом |
Автор: Урри
[комментарии]
|
| | Понадобилось настроить и запустить на сторонней машине автоматизированную
сборку (и автотесты) своего кода сразу под ARM, MIPS, x86 и PowerPC - решил
заодно поделиться с местным сообществом.
Сейчас будет про автоматическую сборку. Про тестирование будет отдельно.
Хотите собрать свой хелловорлд сразу под 17 (29 вариантов сборки, так как почти
каждая платформа идёт в двух вариантах: libc и musl)? Если да - внизу шаги.
Сборка осуществляется с помощью сборочного инструментарий void-linux, за что им
огромное спасибо - работа проделана огромная.
Рецепт описывается простой и последовательный. Желающие сделать что-то
нестандартное или разнообразить секс^Wпроцесс сборки идут читать инструкцию на
гитхаб, она не слишком большая и вполне понятная.
Вот, что нам надо:
Linux, любой (я использую Mint),
Git (им будем ставить тулчейны для сборки исходных текстов),
20+ ГБ на диске (у меня выделенный SSD, хотя все равно долго получается).
Все остальное автоматически доставится в процессе.
Шаг 1: xbps
Собираем xbps:
$ git clone --depth 1 https://github.com/void-linux/xbps
$ cd xbps
$ ./configure --enable-rpath --prefix=/usr --sysconfdir=/etc
$ make
Ставим его в отдельный каталог, не замусоривая систему (пусть это будет каталог ~/xbps-git)
$ make DESTDIR=~/xbps-git install clean
Прекрасно, базовый инструментарий готов.
Добавляем путь к xbps в PATH (потом это же сделаем в скрипте)
$ export PATH=~/xbps-git/usr/bin:$PATH
Шаг 2: сборочный инструментарий void-linux.
Забираем инструментарий:
$ git clone --depth 1 https://github.com/void-linux/void-packages
$ cd void-packages
Не забываем про PATH к xbps, который прописали раньше (export PATH=~/xbps-git/usr/bin:$PATH)
Доставляем локально недостающие детали:
$ ./xbps-src binary-bootstrap
Шаг 3: готовим свой код к сборке
Ваш код, само собой, лежит где-то на гитхабе (гитлабе, дома) и у него проставлен тег "1.0".
В каталоге srcpkgs создаем свой подкаталог с любым именем (у нас будет helloworld)
В созданном каталоге размещаем вот такой текстовый файл "template":
# Template file for 'helloworld'
pkgname=helloworld
version=1.0
revision=1
build_style=gnu-makefile
hostmakedepends="xxd"
short_desc="Hello World"
maintainer="superpuperprogrammer <superpuperprogrammer@gmail.com>"
license="MIT"
homepage="https://superpuperprogrammer.github.io/"
distfiles="https://github.com/superpuperprogrammer/helloworld/archive/${version}.tar.gz"
checksum=b5...............f1
do_check() {
make check
}
post_install() {
vlicense LICENSE
}
"xxd" в зависимостях просто так - впишите своё, если надо;
адрес архива с кодом вписываете свой, в примере гитхаб по тегу;
checksum получаете запустив "sha256sum 1.0.tar.gz";
"make check" можете исключить, но с ним интереснее.
Шаг 4, последний. Собираем.
На выбор есть много платформ/архитектур, вот их список: x86_64-musl
aarch64-musl aarch64 armv5tel-musl armv5tel armv5te-musl armv5te armv6hf-musl
armv6hf armv6l-musl armv6l armv7hf-musl armv7hf armv7l-musl armv7l i686-musl
i686 mipselhf-musl mipsel-musl mipshf-musl mips-musl ppc64le-musl ppc64le
ppc64-musl ppc64 ppcle-musl ppcle ppc-musl ppc. Впечатляет?
Собираем так:
$ ./xbps-src -a armv7hf-musl -C pkg helloworld
Вместо armv7hf-musl подставляете нужную платформу из списка. В процессе
xbps-src сам доставит отсутствующий тулчейн и сам запустит сборку. Берите пиво,
колу, чай (что вы пьете) и наблюдайте логи.
Лично я делаю скриптом:
for arch in x86_64-musl \\
aarch64-musl aarch64 \\
armv5tel-musl armv5tel armv5te-musl armv5te armv6hf-musl armv6hf armv6l-musl armv6l armv7hf-musl armv7hf armv7l-musl armv7l \\
i686-musl i686 \\
mipselhf-musl mipsel-musl mipshf-musl mips-musl \\
ppc64le-musl ppc64le ppc64-musl ppc64 \\
ppcle-musl ppcle \\
ppc-musl ppc
do
./xbps-src -a $arch clean helloworld
./xbps-src -a $arch -C pkg helloworld || exit $?
done
Пока все. Автоматическое тестирование всех этих платформ/архитектур не вставая
с кресла и не создавая сорок виртуалок будет в следующем совете - https://www.opennet.ru/tips/3201_helloworld_build_compile_libc_musl.shtml
|
| |
|
|
|
Компиляция приложений с поддержкой OpenCL без закрытых драйверов |
Автор: Аноним
[комментарии]
|
| | При сборке Wine не для личного использования, а чтобы распространять сборки, я
столкнулся с проблемой. С какой реализацией OpenCL линковать? NVIDIA, AMD,
Intel, Mesa? Ответ - FreeOCL!
На самом деле, не важно с чем линковать. У всех известных мне реализаций
OpenCL, сама библиотека libOpenCL.so.1 занимает около 30 Кб.
Оказывается, внутри этой библиотеки ничего нет. Сам OpenCL находится в другой
библиотеке (например в libatiocl64.so - см.
/etc/OpenCL/vendors/*.icd для подробностей). Однако залить
проприетарный драйвер в OBS-репозиторий я не могу, так как закрытый код.
Остаётся только Mesa и FreeOCL.
FreeOCL это программная реализация OpenCL, написанная на C++, и имеющая у
себя в зависимостях libatomic_ops - а LLVM не имеющая. Установив в систему
FreeOCL и opencl-headers, я успешно собрал Wine. Причём
Wine линкуется только с OPENCL_1.0, что не помешало конечному софту,
запущенному в Wine, успешно задействовать расширения 1.2 и 2.0.
В общем, рекомендую всем, кто до сих пор собирает с AMD APP SDK 3.0, перейти на
FreeOCL. Я попробовал скомпилировать весь известный мне OpenCL-софт при помощи
FreeOCL, а затем запустить на NVIDIA и AMD - всё работает безупречно. Не
падает, не отказывается стартовать, и демонстрирует ровно ту же скорость работы.
P.S. Бинарник получает зависимость от libOpenCL.so.1 (параметр
-lOpenCL), а пакет RPM или DEB также получает от pkg-config ещё
несколько зависимостей:
libOpenCL.so.1(OPENCL_1.0)(64bit)
libOpenCL.so.1(OPENCL_1.1)(64bit)
libOpenCL.so.1(OPENCL_1.2)(64bit)
libOpenCL.so.1(OPENCL_2.0)(64bit)
Поэтому если вы собираете пакеты, а не просто tar.gz архив с программой,
рекомендую пропатчить FreeOCL патчем
freeocl-0.3.6-disable-symbol-versioning.patch. В этом случае, пакет получит
зависимость только от libOpenCL.so.1()(64bit). Например в моей
системе в пакете NVIDIA 340.xx нет "версионинга" OpenCL, а в 390.xx
он есть. Вследствие чего, пакет не хотел устанавливаться, но после force
install - работал.
|
| |
|
|
|



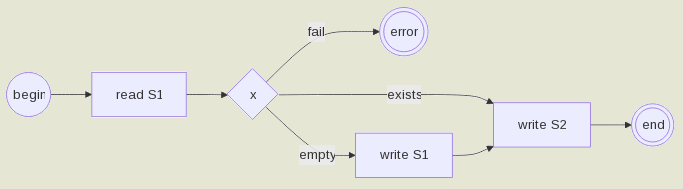 Общее решение гарантии консистентности состояний
Ниже перечислены рассматриваемые виды состояний:
Общее решение гарантии консистентности состояний
Ниже перечислены рассматриваемые виды состояний:
 В результате мы должны получить нечто подобное рис 2.
Рисунок 2.
В результате мы должны получить нечто подобное рис 2.
Рисунок 2.
 Пример использующий контроллер mvc_2edit_1scale.py допускает изменение параметров с
помощью полей ввода целых чисел и чисел с плавающей запятой (вернее точкой), но для
того, чтобы он заработал, пришлось слегка изменить формат передачи параметров и начать
указывать в них, какого типа значение будет принимать параметр.
Пример создадим файл model2_1.mac
work_dir:sconcat(maxima_tempdir,"/work/maxima/gnuplot/");
load(sconcat(work_dir,"idraw"));
g1:explicit(a*sin(x),x,-c*%pi,c*%pi);
g2:explicit(sin(b*x),x,-c*%pi,c*%pi);
call_d:'draw2d(color=red,g1, color=blue,g2);
model:call_d;
param_set:[[a,55.0,"f:0.1:100.0"], [b,17,"i:1:100"], [c,2,"1:10"]];
name_model:sconcat(work_dir,"mvc_2edit_1scale.py");
в определении параметров добавили столбец, определяющий тип параметра int(i) или
float(f).
load(sconcat(maxima_tempdir,"/work/maxima/gnuplot/model2_1.mac"));
и запустим интерпретацию нашей модели модели
idraw(model,param_set,name_model);
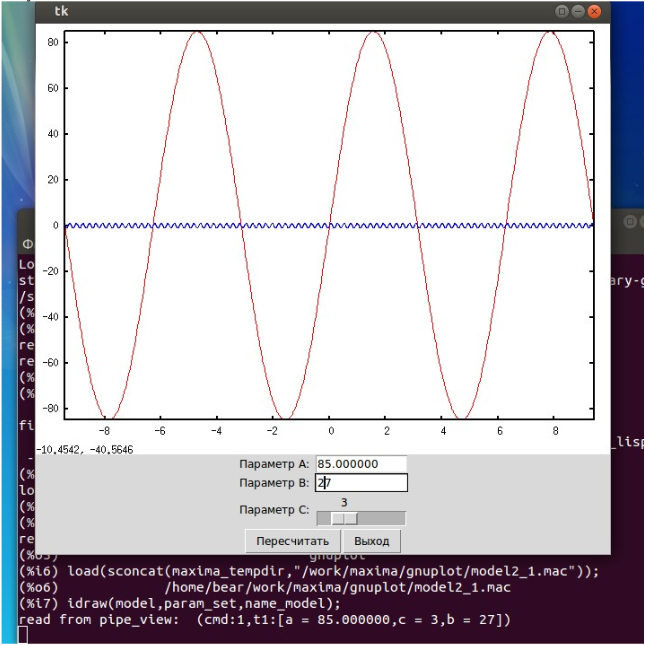
должны получить нечто подобное рис.3
Рисунок 3.
Пример использующий контроллер mvc_2edit_1scale.py допускает изменение параметров с
помощью полей ввода целых чисел и чисел с плавающей запятой (вернее точкой), но для
того, чтобы он заработал, пришлось слегка изменить формат передачи параметров и начать
указывать в них, какого типа значение будет принимать параметр.
Пример создадим файл model2_1.mac
work_dir:sconcat(maxima_tempdir,"/work/maxima/gnuplot/");
load(sconcat(work_dir,"idraw"));
g1:explicit(a*sin(x),x,-c*%pi,c*%pi);
g2:explicit(sin(b*x),x,-c*%pi,c*%pi);
call_d:'draw2d(color=red,g1, color=blue,g2);
model:call_d;
param_set:[[a,55.0,"f:0.1:100.0"], [b,17,"i:1:100"], [c,2,"1:10"]];
name_model:sconcat(work_dir,"mvc_2edit_1scale.py");
в определении параметров добавили столбец, определяющий тип параметра int(i) или
float(f).
load(sconcat(maxima_tempdir,"/work/maxima/gnuplot/model2_1.mac"));
и запустим интерпретацию нашей модели модели
idraw(model,param_set,name_model);
должны получить нечто подобное рис.3
Рисунок 3.
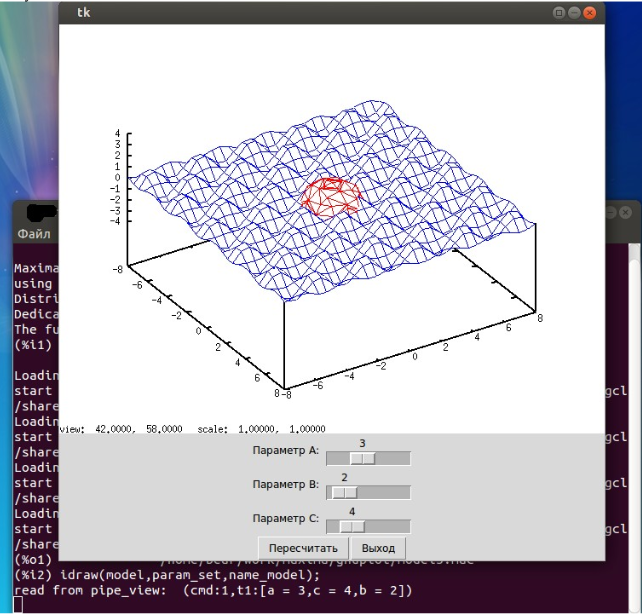
 Ну и в завершении я представлю программу mvc_any_param.py, которая идеально подойдет
для людей, не желающих программировать для каждой модели еще и контроллер, она
способна в минимальном представлении отрисовать любое передаваемое ей количество
параметров любого типа. Для того, чтобы она работала, необходимо опять изменить формат
передаваемых параметров, и для каждого параметра указывать, какого типа виджет мы
желаем использовать для его редактирования. Добавим в начало каждой строки параметров,
там где мы ранее задавали диапазон, еще одно поле со значениями s - Scale
или e - Entry.
Изучаем пример, файл model4.mac:
work_dir:sconcat(maxima_tempdir,"/work/maxima/gnuplot/");
load(sconcat(work_dir,"idraw"));
g1:explicit((a/10.)*sin(x),x,-c*%pi,c*%pi);
g2:explicit(sin(b*x),x,-c*%pi,c*%pi);
model:'draw2d(color=red,g1, color=blue,g2);
param_set:[[a,55.0,"e:f:10.0:1000.0"], [b,17,"e:i:1:100"], [c,2,"s:1:10"]];
param_set1:[[a,55.0,"e:f:10.0:1000.0"], [b,17,"e:i:1:100"], [c,2,"s:1:10"],
[da,55,"s:10:1000"], [bi,17,"e:f:1:100"], [ca,2,"s:0:20"]];
param_set2:[[a,55.0,"e:f:10.0:1000.0"], [b,17,"e:i:1:100"], [c,2,"s:1:10"],
[da,55,"s:10:1000"], [bi,17,"e:f:1:100"], [ca,2,"s:0:20"],
[w,55,"s:10:1000"], [bu,17,"e:f:1:100"]];
name_model:sconcat(work_dir,"mvc_any_param.py");
Загрузив нашу модель командой:
load(sconcat(maxima_tempdir,"/work/maxima/gnuplot/model4.mac"));
запустим интерпретацию нашей модели
idraw(model,param_set2,name_model);
Мы должны получить что то подобное рисунку 4
Я не стал изменять саму модель, просто продемонстрировал простоту добавления
параметров.
Рисунок 4.
Ну и в завершении я представлю программу mvc_any_param.py, которая идеально подойдет
для людей, не желающих программировать для каждой модели еще и контроллер, она
способна в минимальном представлении отрисовать любое передаваемое ей количество
параметров любого типа. Для того, чтобы она работала, необходимо опять изменить формат
передаваемых параметров, и для каждого параметра указывать, какого типа виджет мы
желаем использовать для его редактирования. Добавим в начало каждой строки параметров,
там где мы ранее задавали диапазон, еще одно поле со значениями s - Scale
или e - Entry.
Изучаем пример, файл model4.mac:
work_dir:sconcat(maxima_tempdir,"/work/maxima/gnuplot/");
load(sconcat(work_dir,"idraw"));
g1:explicit((a/10.)*sin(x),x,-c*%pi,c*%pi);
g2:explicit(sin(b*x),x,-c*%pi,c*%pi);
model:'draw2d(color=red,g1, color=blue,g2);
param_set:[[a,55.0,"e:f:10.0:1000.0"], [b,17,"e:i:1:100"], [c,2,"s:1:10"]];
param_set1:[[a,55.0,"e:f:10.0:1000.0"], [b,17,"e:i:1:100"], [c,2,"s:1:10"],
[da,55,"s:10:1000"], [bi,17,"e:f:1:100"], [ca,2,"s:0:20"]];
param_set2:[[a,55.0,"e:f:10.0:1000.0"], [b,17,"e:i:1:100"], [c,2,"s:1:10"],
[da,55,"s:10:1000"], [bi,17,"e:f:1:100"], [ca,2,"s:0:20"],
[w,55,"s:10:1000"], [bu,17,"e:f:1:100"]];
name_model:sconcat(work_dir,"mvc_any_param.py");
Загрузив нашу модель командой:
load(sconcat(maxima_tempdir,"/work/maxima/gnuplot/model4.mac"));
запустим интерпретацию нашей модели
idraw(model,param_set2,name_model);
Мы должны получить что то подобное рисунку 4
Я не стал изменять саму модель, просто продемонстрировал простоту добавления
параметров.
Рисунок 4.
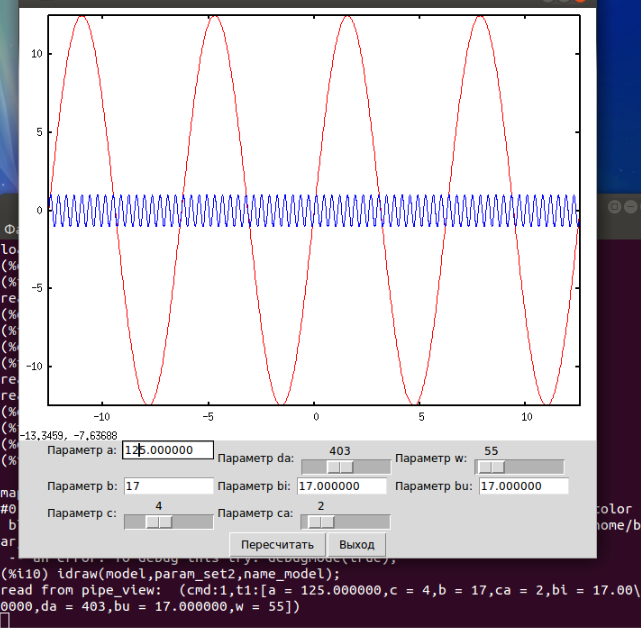 Заключение.
Ну вот, собственно говоря, и все. В принципе, в программе можно еще много что
делать и совершенствовать. Но, как говорится, лучшее враг хорошего, к нему можно
бесконечно приближаться, а работу надо рано или поздно заканчивать. Удачи вам,
удосужившимся ознакомиться с моим трудом, надеюсь знакомство с максимой, линуксом и
питоном обогатят вашу жизнь, сделают шире ваши возможности, как это произошло со мной.
Разработал Гагин Михаил ака NuINu c благодарностью к разработчикам Maxima, Gnuplot,
Python, Linux и всему сообществу OpenSource.
Примеры кода к статье и версию статьи в формате PDF можно загрузить
Заключение.
Ну вот, собственно говоря, и все. В принципе, в программе можно еще много что
делать и совершенствовать. Но, как говорится, лучшее враг хорошего, к нему можно
бесконечно приближаться, а работу надо рано или поздно заканчивать. Удачи вам,
удосужившимся ознакомиться с моим трудом, надеюсь знакомство с максимой, линуксом и
питоном обогатят вашу жизнь, сделают шире ваши возможности, как это произошло со мной.
Разработал Гагин Михаил ака NuINu c благодарностью к разработчикам Maxima, Gnuplot,
Python, Linux и всему сообществу OpenSource.
Примеры кода к статье и версию статьи в формате PDF можно загрузить  Опции
Дополнительные опции, регулирующие количество дней в прогнозе,
единицы измерения, вывод дополнительных данных и другие параметры
задаются после вопросительного знака в строке запроса:
$ curl wttr.in/San-Francisco?u
(для просмотра прогноза с использованием системы мер USCS).
Полный список доступных опций
можно посмотреть на странице /:help:
$ curl wttr.in/:help
PNG-вывод и маркировка фотографий
Если добавить к концу запроса суффикс ".png", то сервис предоставит прогноз
погоды в виде PNG-файла (который будет выглядеть как вывод cURL в терминале).
Этот режим можно использовать в нескольких случаях:
1. Для просмотра погоды в браузере, в котором некорректно поддерживаются
моноширинные Unicode-шрифты (главным образом старые Windows-браузеры);
2. Для непосредственного использования в web-страницах (файл можно
непосредственно встраивать в страницу c помощью <img src="http://wttr.in/Moscow.png"/>.
3. Для добавления информации о погоде на фотографии:
$ convert 1.jpg < ( curl wttr.in/Oymyakon_tqp0.png ) -geometry +50+50 -composite 2.jpg
В этом примере к фотографии 1.jpg добавится погода в данный момент в Оймяконе и
результат будет записан в 2.jpg.
Опции
Дополнительные опции, регулирующие количество дней в прогнозе,
единицы измерения, вывод дополнительных данных и другие параметры
задаются после вопросительного знака в строке запроса:
$ curl wttr.in/San-Francisco?u
(для просмотра прогноза с использованием системы мер USCS).
Полный список доступных опций
можно посмотреть на странице /:help:
$ curl wttr.in/:help
PNG-вывод и маркировка фотографий
Если добавить к концу запроса суффикс ".png", то сервис предоставит прогноз
погоды в виде PNG-файла (который будет выглядеть как вывод cURL в терминале).
Этот режим можно использовать в нескольких случаях:
1. Для просмотра погоды в браузере, в котором некорректно поддерживаются
моноширинные Unicode-шрифты (главным образом старые Windows-браузеры);
2. Для непосредственного использования в web-страницах (файл можно
непосредственно встраивать в страницу c помощью <img src="http://wttr.in/Moscow.png"/>.
3. Для добавления информации о погоде на фотографии:
$ convert 1.jpg < ( curl wttr.in/Oymyakon_tqp0.png ) -geometry +50+50 -composite 2.jpg
В этом примере к фотографии 1.jpg добавится погода в данный момент в Оймяконе и
результат будет записан в 2.jpg.
 Локализация и интернационализация
wttr.in переведён на более чем 40 языков народов мира в том числе на русский,
украинский и некоторые другие языки бывших союзных республик.
Выбор языка вывода определяется автоматически на основе заголовков HTTP
(Accept-Language) или может быть задано с помощью параметра lang:
$ curl wttr.in/Moscow?lang=ru
Поддерживаются не только различные языки вывода, но и различные языки запросов
(они должны быть в кодировке UTF-8).
Например, такие запросы будут работать:
$ curl wttr.in/станция+Восток
$ curl wttr.in/Килиманджаро
$ curl wttr.in/Северный+полюс
и тому подобные.
Это очень важно, поскольку далеко не все населённые пункты (и места) на земном
шаре имеют англоязычное название.
Для входных запросов поддерживается не только русский, но и любые другие языки.
Локализация и интернационализация
wttr.in переведён на более чем 40 языков народов мира в том числе на русский,
украинский и некоторые другие языки бывших союзных республик.
Выбор языка вывода определяется автоматически на основе заголовков HTTP
(Accept-Language) или может быть задано с помощью параметра lang:
$ curl wttr.in/Moscow?lang=ru
Поддерживаются не только различные языки вывода, но и различные языки запросов
(они должны быть в кодировке UTF-8).
Например, такие запросы будут работать:
$ curl wttr.in/станция+Восток
$ curl wttr.in/Килиманджаро
$ curl wttr.in/Северный+полюс
и тому подобные.
Это очень важно, поскольку далеко не все населённые пункты (и места) на земном
шаре имеют англоязычное название.
Для входных запросов поддерживается не только русский, но и любые другие языки.
 Новые функции и исходный код
Сервис wttr.in постоянно развивается.
Информация о новых функциях публикуется в твиттере главного разработчика
проекта -
Новые функции и исходный код
Сервис wttr.in постоянно развивается.
Информация о новых функциях публикуется в твиттере главного разработчика
проекта -  Выводы.
Технологии, основывающиеся на необходимости хранения состояния клиента
потенциально ограничены ростом клиентских подключений, и как следствие
предполагают централизацию аппаратных ресурсов. Возможность инициации событий
со стороны сервера является необходимой опцией для внутренних решений. Три
перечисленных фактора определяет рынок корпоративных решений, как наиболее
привлекательный для технологий, аналогичных Korolev. Качественная оптимизация
Korolev явно демонстрируют стремление к минимизации накладных расходов на
хранение клиентских состояний, но не устраняет их.
Pusa, принципиально следуя парадигме чистого REST, нацелена на рынок открытых
решений, со значительным количеством клиентских подключений. Pusa предполагает
использование множества независимых инстансов, с минимальными требования, без
необходимости их общего взаимодействия. Запросы одного и того же пользователя к
Pusa могут обрабатываться различными инстансами в рамках одной сессии, что
позволяет использовать решение под значительными нагрузками.
Ссылки
Выводы.
Технологии, основывающиеся на необходимости хранения состояния клиента
потенциально ограничены ростом клиентских подключений, и как следствие
предполагают централизацию аппаратных ресурсов. Возможность инициации событий
со стороны сервера является необходимой опцией для внутренних решений. Три
перечисленных фактора определяет рынок корпоративных решений, как наиболее
привлекательный для технологий, аналогичных Korolev. Качественная оптимизация
Korolev явно демонстрируют стремление к минимизации накладных расходов на
хранение клиентских состояний, но не устраняет их.
Pusa, принципиально следуя парадигме чистого REST, нацелена на рынок открытых
решений, со значительным количеством клиентских подключений. Pusa предполагает
использование множества независимых инстансов, с минимальными требования, без
необходимости их общего взаимодействия. Запросы одного и того же пользователя к
Pusa могут обрабатываться различными инстансами в рамках одной сессии, что
позволяет использовать решение под значительными нагрузками.
Ссылки
 Одно замечание по этому плагину - он был разработан только для пользователей
Linux и не будет работать в Windows в том виде в каком он есть.
git.vim
Git.vim более комплексный плагин, который позволяет пользователю производить
больше действий с Git не покидая окружения Vim. Домашняя страница на GitHub
http://github.com/motemen/git-vim/tree/master перечисляет все возможности,
доступные благодоря этому плагину.
Функция вызываемая для установки статусной строки называется - GitBranch().
Итак, строки добавляемые в .vimrc должны быть такими:
set laststatus=2
set statusline=%{GitBranch()}
Но к сожалению, здесь есть ошибка в функции GitBranch(). Снова выручает GitHub,
проект был форкнут и доступен здесь
Одно замечание по этому плагину - он был разработан только для пользователей
Linux и не будет работать в Windows в том виде в каком он есть.
git.vim
Git.vim более комплексный плагин, который позволяет пользователю производить
больше действий с Git не покидая окружения Vim. Домашняя страница на GitHub
http://github.com/motemen/git-vim/tree/master перечисляет все возможности,
доступные благодоря этому плагину.
Функция вызываемая для установки статусной строки называется - GitBranch().
Итак, строки добавляемые в .vimrc должны быть такими:
set laststatus=2
set statusline=%{GitBranch()}
Но к сожалению, здесь есть ошибка в функции GitBranch(). Снова выручает GitHub,
проект был форкнут и доступен здесь  ":GitCommit" открывает отдельное окно для ввода информации о коммите, и
коммитит текущий файл в репозиторий. Если файлы не добавлены в индекс, то
плагин автоматически вызывает git commit с опицей -a для внесения всех
измененных файлов в индекс и коммитит их в репозиторий.
":GitCommit" открывает отдельное окно для ввода информации о коммите, и
коммитит текущий файл в репозиторий. Если файлы не добавлены в индекс, то
плагин автоматически вызывает git commit с опицей -a для внесения всех
измененных файлов в индекс и коммитит их в репозиторий.
 ":GitDiff" открывает отдельное окно с выводом команды git diff по текущему файлу.
":GitDiff" открывает отдельное окно с выводом команды git diff по текущему файлу.
 ":GitLog" показывает лог сообщение коммита по текущему файлу.
":GitLog" показывает лог сообщение коммита по текущему файлу.
 ":GitBlame" показывает изменения файла в виде списка однострочных записей, по
одному имени пользователя на строку в вертикальном окне.
Это экспериментальная функция, для слияния конфликтующих файлов использует
Vimdiff, ":GitVimDiffMerge" и другие команды git можно вызвать из Vim используя :Git.
":GitBlame" показывает изменения файла в виде списка однострочных записей, по
одному имени пользователя на строку в вертикальном окне.
Это экспериментальная функция, для слияния конфликтующих файлов использует
Vimdiff, ":GitVimDiffMerge" и другие команды git можно вызвать из Vim используя :Git.
{kind=link}